







文末
js前端的重头戏,值得花大部分时间学习。

推荐通过书籍学习,《 JavaScript 高级程序设计(第 4 版)》你值得拥有。整本书内容质量都很高,尤其是前十章语言基础部分,建议多读几遍。

开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
另外,大推一个网上教程 现代 JavaScript 教程 ,文章深入浅出,很容易理解,上面的内容几乎都是重点,而且充分发挥了网上教程的时效性和资料链接。
学习资料在精不在多,二者结合,定能构建你的 JavaScript 知识体系。
面试本质也是考试,面试题就起到很好的考纲作用。想要取得优秀的面试成绩,刷面试题是必须的,除非你样样精通。
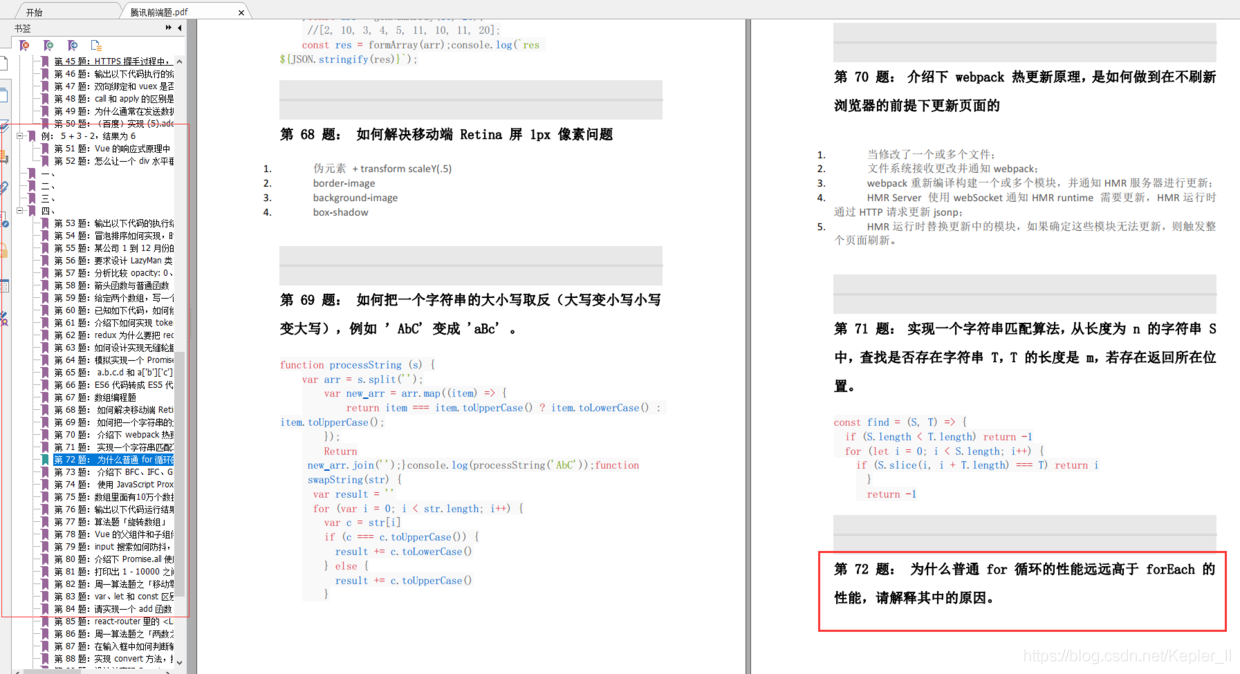
这是288页的前端面试题

1,JS 数据类型
JavaScript共 8 种数据类型:Undefined、Null、String、Number、Boolean、Object、Symbol、bigint,其中Object包含3种类型:Array、Function、Date。
2,JS 两种数据类型
首先我们说下 js 中的堆、栈:
JS中变量都存放在内存中,而内存给变量开辟了两块区域:栈区域和堆区域
- 基本数据类型存储在栈内存中,当被引用或者拷贝的时候,会创建一个完全相等的变量
- 引用数据类型存储在堆内存中,存储的是内存指针,多个引用会指向同一个地址
Js分为两大类型:基本数据类型和引用数据类型
-
基本数据类型(又称原始数据类型)包括:string、number、boolean、Symbol、bigint、null、undefined
- 该数据类型存储在栈中,栈内存的作用:提供执行代码的环境。
- 栈结构的特点:先进后出
- ECMAScript给数组提供几个方法,让它看起来像是另外一种数据结构。数组对象可以像栈一样,也就是一种限制插入和删除项的数据结构。栈是一种后进先出/先进后出(LIFO, Last-In-First-Out)的结构,也就是最近添加的项先被删除。数据项的插入(称为推入,push)和删除(称为弹出,pop)只在栈的一个地方发生,即栈顶。ECMAScript数组提供了push()和pop()方法,以实现类似栈的行为
-
引用数据类型Object(又称复合数据类型)包括:Array、Function、Date和两种不常见的Math、RegExp正则
- 该数据类型存储在堆中,堆内存的作用:存放东西(存放的是属性和方法)
- 队列以先进先出/后进后出(FIFO, First-In-First-Out)形式限制访问。队列在列表末尾添加数据,但从列表开头获取数据。因为有了在数据末尾添加数据的push()方法,所以要模拟队列就差一个从数组开头取得数据的方法了。这个数组方法叫shift(),它会删除数组的第一项并返回它,然后数组长度减1。使用shift()和push(),可以把数组当成队列来使用
1,基本数据类型
1,基本数据类型的值不可变
基本数据类型的值是不可变的,任何方法都不可以修改一个基本数据类型的值
基本数据类型的值存储在栈中 ,当声明一个变量的时候,变量会去内存空间找对应的值,如果找到了对应的值,就直接把该值的内存地址存到变量里;如果没找到,就创建一个新的空间来存储对应的值,并且把新空间的内存地址存到变量里。js中,变量不存储任何值,而存储的是值的内存地址。基本数据类型一旦创建,就是不可变的,因为它占据的空间是固定的,修改变量的值相当于重新创建一个内存空间,变量指向内存空间的地址
let username = "Jerry";
let name = username.toUpperCase();
console.log(username); // Jerry
console.log(name); // JERRY
// 以上代码说明基本数据类型的值是不可变的,任何方法都不可以修改一个基本数据类型的值,再看以下代码:
let username = "Jerry";
username = "Tom";
console.log(username); // Tom
// 以上代码,我们可以看出username的值变了,username = Jerry表示username是指向Jerry的一个指针,指针的指向可以发生改变的,所以下面的username = 'Tom',是将username指向了Tom,这里的 Tom 也是不可以被改变的。也就是说这里的改变只是指针指向的改变。
2,基本数据类型不可以添加属性和方法:
let userName = "xiaowang";
userName.age = 18;
userName.method = function () {
console.log("哈哈");
};
console.log(userName.age); // undefined
console.log(userName.method); // undefined
3,基本数据类型的赋值是简单的赋值
基本数据类型的赋值是简单的赋值,如果从一个变量向另一个变量赋值,会在变量对象上创建一个新值,然后把该值赋值到新变量分配的位置上:
let a = 18;
let b = a;
b++;
console.log(a, b); // 18 19
以上代码可以看出,a中保存了值是18,当使用a的值初始化b的时候,b中也保存了值是18,但是b中的18和a中的18完全是独立的,b中的值只是a中值的一个副本,所以这两个变量之间互不影响,其关系图如下

4,基本数据类型的比较是值的比较:
let a = "{}";
let b = "{}";
console.log(a === b); // true
5,基本数据类型的值存放在栈内存中
基本数据类型的值存放在栈内存中,占据固定大小的空间,例如以下代码:
let userName = "xiaowang";
let age = 18;
let sex = "女";
以上代码的存储结构如下 (栈区包括变量的标识符和变量的值):

6,基本数据类型详解
1,undefined
undefinde 未定义
- 调用函数的时候,应该提供的参数没有提供,该参数是undefined;
- 对象的属性没有赋值,该属性就是undefined;
- 函数没有返回值的时候,就返回undefined
2,Null
Null 空对象指针
null表示空对象,一般用于释放指向对象的引用地址
3,string
string 字符串
有length属性,获取字符串的值。“xiaowang”.length. // 8
String() 将某个值转换为字符串类型
4,Number
Number 数值类型
- number类型包含整数和浮点数(浮点数必须包含一个小数点,且小数点后至少有一位数字)
- 浮点数会自动转换为整数,let num = 1.00 console.log(num) // 1
- 浮点数的最高精度是17位,let a = 0.1; let b = 0.2;console.log(a+b) // 0.30000000000000004
- 数值转换:
Number() 转型函数,用于将某个值转为数值型
parseInt() 将值转换为整型
parseFloat() 将值转为浮点型
5,Boolean
Boolean 布尔类型
Boolean() 将某个值转为布尔型
6,Symbol
一旦创建,一定是唯一的
let a = Symbol("aaa");
let b = Symbol("aaa");
console.log(a === b, a == b); false false
Symbol作为对象属性名的时候需要[]表示,通过Symbol创建的属性是不必希望被外界访问的属性
let obj = {
name: "xiaowang",
[Symbol("age")]: 18,
};
console.log(obj[Symbol("age")]); // undefined
/**
* 这里访问对象用[]代替点,但是访问不到,因为Symbol('age)每次访问都是一个不一样的值
* 所以需要存储Symbol('age')的值正确做法如下
*/
let age = Symbol("age");
let obj = {
name: "xiaowang",
[age]: 18,
};
console.log(obj[age]); // 18
7,BigInt
BigInt是一种数字类型的数据,可以表示任意大的整数。- 作用是解决精度缺失的问题,
BigInt数据类型比Number类型支持更大的整数值,Number类型智能安全的支持-(253-1)和253-1之间的整数,任何超过这个范围的数值都会丢失精度;当超过Number数据类型支持的安全范围值的时候,将会被四舍五入,从而导致精度缺失的问题,BigInt可以解决这个问题 - 使用场景:更加准确的使用时间戳和数值比较大的ID
- BigInt使用
// 我们直接打印会输出 console.log(9007199254740999) //9007199254741000
// console.log(9007199254740993===9007199254740992) //true
BigInt使用:
1,在整数末尾加n
console.log(9007199254740999n) // 9007199254740999
2,调用BigInt()构造函数
var a = BigInt("9007199254740999");
console.log(a); // 9007199254740999n
2,引用数据类型
1,引用数据类型的值是可以改变的
let obj = {
a: 10,
};
obj.a = 20;
console.log(obj); // {a: 20}
obj.b = 18;
console.log(obj); // { a: 20, b: 18 }
let arr = [1, 2, 3, 4, 5, 6];
arr[0] = 100;
console.log(arr); // [ 100, 2, 3, 4, 5, 6 ]
2,引用类型可以添加属性和方法
let obj = {};
obj.a = 10;
obj.b = function () {
console.log("hello");
};
console.log(obj); // { a: 10, b: [Function (anonymous)] }
3,引用类型的赋值是对象引用
let obj = {};
let obj1 = obj;
obj.a = 10;
console.log(obj.a, obj1.a); // 10 10
obj1.b = 18;
console.log(obj.b, obj1.b); // 18 18
以上代码,引用类型保存在变量中的是对象在堆内存中的地址。所以,与基本数据类型的简单赋值不同,这个值的副本实际上是一个指针,而这个指针指向存储在堆内存的一个对象,那么赋值操作后,两个变量都保存了同一个对象的地址,而这两个地址都指向了同一个对象,因此,改变其中任何一个变量,都会互相影响,关系图如下:

以上代码改为:
let obj = {};
let obj1 = obj;
obj.a = 10;
obj1 = {
b: 20,
};
console.log(obj, obj1); // {a: 10} {b: 20}
以下代码会执行输出什么?
let a = {
n: 1,
};
let b = a;
a.x = a = {
n: 2,
};
console.log(a.x); // undefined
console.log(b); // {n: 1, x: {n: 2}}
console.log(a); // {n: 2}
JS 的赋值是关联不是拷贝

3,数据类型的检测方法
1,typeof
优点:快、用起来简单方便
缺点:对于引用数据类型,除
function外,都返回object
typeof: 用来检测数据类型的运算符
typeof [value]
返回:
首先是个字符串
字符串中包含对应的数据类型,例如:number、object、undefined、function、boolean、symbol、bigint、string
局限性:
typeof null => "object" // js 遗留 bug 不能具体区分对象数据类型的值
typeof [] => "object"
typeof {} => "object"
typeof /^$/ => "object"
2,instanceof
instanceof运算符用来检测构造函数的prototype属性是否出现在某个实例对象的原型链上。或者说
instanceof运算符用来检测实例是否隶属于某个类,返回值:true为属于,false为不属于
优点:
- 1,能区分引用类型
- 2,只要在当前实例的原型链中出现过的类,检测结果都为true
缺点:要求检测的实例必须是对象数据类型的,基本数据类型的实例无法检测出来
语法:实例 instanceof 类 // => true为属于,false为不属于
function CreatePerson(name, age) {
this.name = name;
this.age = age;
}
let p1 = new CreatePerson("AA", 18);
p1 instanceof CreatePerson; // true
p1 instanceof Object; // true
3,constructor
constructor(构造函数)
在类的原型上都会带有一个constructor属性,用来存储当前类本身。任何对象在其__proto__上有一个constructor属性用来存储当前类本身。利用这一点,可以获取到某个实例的constructor属性值是否为所属的类。
(除了null之外,任何对象都会在其__proto__上有一个constructor属性。使用字面量创建的对象也会有一个指向该对象构造函数的constructor属性,比如:数组字面量创建的Array对象和对象字面量创建的普通对象)。
const o1 = {};
o1.constructor === Object; // true
const o2 = new Object();
o2.constructor === Object; // true
const a1 = [];
a1.constructor === Array; // true
const a2 = new Array();
a2.constructor === Array; // true
const n = 3;
n.constructor === Number; // true
/**
原理:在类的原型上都会带constructor属性,存储当前类本身,利用这一点,可以获取某个实例的constructor属性值是否为所属的类,从而进行数据类型检测
局限性:constructor属性值太容易被修改了
*/
// null、undefined没有constructor
const arr = [1, 2, 3];
console.log(arr.constructor === Array); // true
const obj = { name: "xiaowang" };
console.log(obj.constructor === Object); // true
const str = "Hello";
console.log(str.constructor === String); // true
String.prototype.constructor = function fn() { // constructor 被改写
return {};
};
console.log(str.constructor === String); // false
console.log(str.constructor); // fn(){}
4,Object.prototype.toString.call([value])
1,Object.prototype.toString()
toString() 方法返回一个表示该对象的字符串
const arr = [1, 2, 3];
arr.toString() // "1,2,3"
Object.prototype.toString() // [object Object]
Object.prototype.toString.call() // [object undefined]
Object.prototype.toString.call(arr) // [object Array]
Object.prototype.toString()返回"[object Type]",这里的Type是对象的类型。
调用Object原型上的toString方法,方法执行的时候,方法中的this是要检测数据类型,从而获取到数据类型所属类的相关信息
形如:“[object 所属类]” 例如:“[object Array]”
2,Object.prototype.toString.call([value])
toString() 可以与每个对象一起使用,并且(默认情况下)允许你获得它的类
const toString = Object.prototype.toString;
toString.call(new Date()); // [object Date]
toString.call(new String()); // [object String]
// Math has its Symbol.toStringTag
toString.call(Math); // [object Math]
toString.call(undefined); // [object Undefined]
toString.call(null); // [object Null]
在 null 和 undefined 上调用 Object.prototype.toString() 分别返回 [object Null] 和 [object Undefined]
以这种方式使用 toString() 是不可靠的;**对象可以通过定义 Symbol.toStringTag 属性来更改 Object.prototype.toString() 的行为,从而导致意想不到的结果。**例如:
const myDate = new Date();
Object.prototype.toString.call(myDate); // [object Date]
myDate[Symbol.toStringTag] = "myDate";
Object.prototype.toString.call(myDate); // [object myDate]
Date.prototype[Symbol.toStringTag] = "prototype polluted";
Object.prototype.toString.call(new Date()); // [object prototype polluted]
4,JS 为什么要进行变量提升
1,定义
JS代码执行之前,浏览器会将var、function关键字提升到当前作用域的顶端,这种预处理的机制就叫变量提升机制。
2,了解JavaScript从编译到执行的过程
当浏览器开辟出供代码执行的栈内存后,代码并没有立即自上而下执行,而是会进行如下操作:
-
1,词法分析
-
**2,语法分析:**检查代码是否存在错误,若有,引擎会抛出错误,同时会构建一颗抽象的语法树
-
3,预编译(这个阶段会涉及到变量提升,变量提升是把当前作用域中的带var、function关键字进行提前声明和定义)
- MDN注解:函数和变量相比,会被优先提升
- 变量提升会把声明的变量提升到当前作用域的顶端
- JavaScript 只会提升声明,不会提升其初始化
- 如果一个变量先被使用再被声明和赋值的话,使用时的值是 undefined
- 预编译是指JavaScript引擎在实际执行代码之前,对代码进行一些处理,包括变量提升和函数声明
- 带 function 的不仅声明,而且还定义了,定义其实就是赋值,准确来说就是让变量和某个值进行关联
-
4,执行
3,JS 的两种预编译
JS 预编译分为:全局预编译、函数预编译,分别发生在script内代码执行前和函数的执行前。
预编译采用以下原则:
- 函数声明,整体提升(函数名+函数体)
- 变量声明,声明提升(定义/初始化不提升)
1,全局预编译
全局预编译的对象为变量声明和函数声明
1,全局预编译的过程
- 1,生成 GO(全局对象)
- 2,找变量声明,值赋值为undefined
- 3,找函数声明,值为函数体
2,代码演示
console.log(a); // undefined
console.log(c); // err: c is not defined
var a = 10;
var b = a;
b = 20;
console.log(a); // 10
console.log(sum(10, 20)); // 40
function sum(n, m) {
return n + m + a;
}
### 最后
小编综合了阿里的面试题做了一份前端面试题PDF文档,里面有面试题的详细解析
**[开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】](https://bbs.youkuaiyun.com/forums/4304bb5a486d4c3ab8389e65ecb71ac0)**

虽只说了一个公司的面试,但我们可以知道大厂关注的东西并举一反三,通过一个知识点延伸到另一个知识点,这是我们要掌握的学习方法,小伙伴们在这篇有学到的请评论点赞转发告诉小编哦,谢谢大家的支持!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









