







一.什么是机器学习
机器学习是人工智能的一个分支,它使计算机系统能够利用数据和算法自动学习和改进其性能。简单来说,机器学习涉及开发数学模型,这些模型可以帮助计算机使用样本数据(即训练数据)来做出预测或决策,而无需明确编程指令。
简而言之,机器学习就是从历史数据中获取规律,预测未来发展情况
二.机器学习算法的分类
- 监督学习:使用标记的训练数据来学习,目标是预测输出。
- 目标值为类别:分类问题
- 目标值为连续型数字:回归问题
- 无监督学习:使用未标记的训练数据来发现数据中的模式或结构。
- 没有特定目标值:无监督学习
- 半监督学习:结合了少量标记数据和大量未标记数据。
- 强化学习:通过与环境的交互来学习,目标是最大化某种累积奖励。
三.机器的开发过程
机器学习的过程通常包括以下几个步骤:
- 数据收集:收集用于训练模型的数据。
- 数据预处理:清洗数据,处理缺失值,进行特征选择等。
- 选择模型:根据问题的性质选择一个合适的机器学习算法。
- 训练模型:使用训练数据来训练选定的模型。
- 评估模型:使用测试数据来评估模型的性能。
- 参数调优:根据模型的表现调整模型参数以优化性能。
- 模型部署:将训练好的模型部署到实际应用中。
四.数据集---sklearn中包含的数据集
1.在sklearn中,使用load获取小数据集,fetch获取大数据集
from sklearn.datasets import load_iris,fetch_20newsgroups
# load_iris 经典鸢尾花数据集,小数据集使用"load"
iris = load_iris()
news = fetch_20newsgroups()2.数据集的基本信息查看
print("鸢尾花数据集:\n",iris)
print("查看数据集描述:\n", iris.DESCR)
print("查看特征值的名字:\n",iris.feature_names)
print("查看特征值:\n",iris.data,iris.data.shape)iris:
直接打印数据集会得到一个很大的字典, 其中key为"data"和"target",value是一个充满数据的一个数组
iris.DESCR
可以查看sklearn官方对该数据集的描述
iris.feature_name:
查看特征值的名字,其中target的value是一个值为[0,1,2]的数组,分别表示该数据集的不同特征
iris.data
查看isri中key为"data"的value
iris.data.shape
查看"data"的形状,包括有几条数据,几个特征值

五.数据处理----数据集的划分
sklearn提供的API中,包括了数据集的划分
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
print("训练集的特征值:\n", x_train, x_train.shape)train_test_split():该方法需要传入参数
1.数据集的数据:既数据集中的"data"
2.数据集的目标值:既数据集中的"target"
3.测试集的大小:默认值0.25(25%)可以自己调参
4.random_state:随机数种子,通常用于控制随机数生成器的种子,目的是为了确保代码的可重复性,即每次运行代码时都能得到相同的结果
六.特征工程
1.什么是特征工程
特征工程是机器学习中的一个重要步骤,它涉及从原始数据中选择、创建和转换数据特征,以提高机器学习模型的性能。特征工程的目的是提取出对模型预测最有用的信息,并以一种模型能够理解的方式呈现。
特征工程最重要的一个操作就是对数据进行处理,合理的处理数据可以提高机器学习的性能,其中入门阶段主要学习的数据处理包括特征提取,特征预处理以及降维,下面将重点说明.
2.特征提取
1)特征处理API
sklearn.feature_extraction 2)字典特征提取
作用:对字典数据进行特征值化
from sklearn.feature_extraction import DictVectorizer
# 1、实例化一个转换器类
transfer = DictVectorizer(sparse=True)
# 2、调用fit_transform()
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new.toarray(), type(data_new))
print("特征名字:\n", transfer.get_feature_names())特征提取的父类是一个转换器类,都继承转换器,需要构造一个实例才能使用里面的方法,
DictVectorizer():可传入的参数主要有:
sparse:默认为 True,决定转换结果是否为稀疏矩阵
sort:默认为 True,决定在拟合过程中是否对 feature_names_ 和 vocabulary_ 进行排序。
DictVectorizer():可以使用的方法主要有:
transfer.fit_transform(data):将传入的data进行计算(fit),然后将其转换为一个稀疏矩阵

3)文本特征提取
作用:对文本数据进行特征值化
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
# 1、实例化一个转换器类
transfer = TfidfVectorizer(stop_words=["一种", "所以"])
# 2、调用fit_transform
data_final = transfer.fit_transform(data_new)
print("data_new:\n", data_final.toarray())
print("特征名字:\n", transfer.get_feature_names())4)图像特征提取
深度学习在学.
3.特征预处理
1)什么是特征预处理
特征预处理是数据预处理的一部分,它涉及将原始数据转换成适合机器学习算法处理的形式。特征预处理的目的是提高模型的性能、准确性和训练效率。
主要的内容就数值型数据的无量纲化:归一化,标准化
无量纲化::调整数据特征的尺度,使其位于相同的数值范围内
2)为什么要进行无量纲化(特征缩放)
- 加快学习算法的收敛速度。
- 提高模型的性能和准确性。
- 避免数值计算问题。
- 使不同尺度的特征对模型的影响均衡。
3)特征预处理API
sklearn.prepeocessing
4)归一化
定义:通过对原始数据进行变换,把数据映射到[0,1]之间
from sklearn.preprocessing import MinMaxScaler
# 1、获取数据
data = pd.read_csv("dating.txt")
data = data.iloc[:, :3]
print("data:\n", data)
# 2、实例化一个转换器类
transfer = MinMaxScaler(feature_range=[0, 1])
# 3、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)MinMaxScaler(feature_range=[0, 1]):实例化一个转换器,传入的参数为特征范围,默认是[0,1]
处理后的结果:
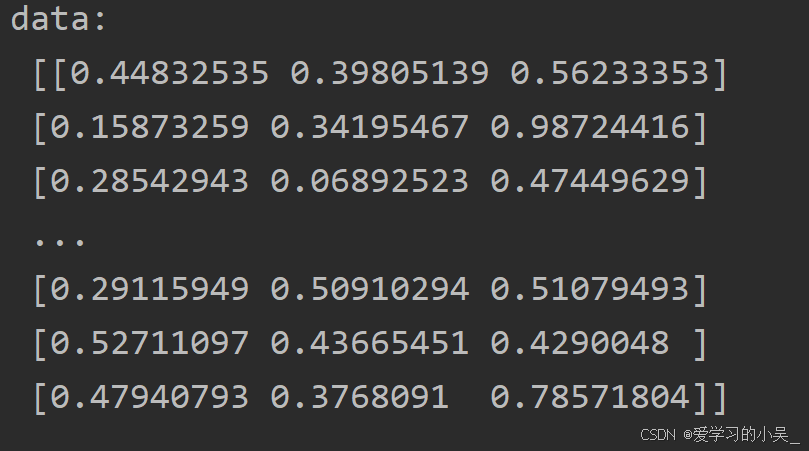
转换器类的方法比较通用:
-
fit_transform:这个方法结合了拟合(fit)和转换(transform)两个步骤。它首先拟合数据,学习数据的特征(例如,计算均值和标准差),然后应用这些学到的特征来转换数据。
-
fit:这个方法用于拟合数据,学习数据的特征,但不进行转换。例如,它可以计算每列的平均值和标准差,为后续的转换步骤做准备。fit只需要调用一次后就可以存储,后面只需要转换
-
transform:在数据已经被拟合(fit)之后,使用这个方法来转换数据。它应用在拟合步骤中学习到的特征来转换数据,例如,使用计算出的平均值和标准差来标准化数据。
-
get_params:获取转换器的参数。
-
set_params:设置转换器的参数。
-
fit_resample:结合拟合和重新采样的方法,用于处理数据不平衡问题。
-
score_samples:返回样本的分数或权重,这在某些转换器中可能适用,如基于树的转换器。
-
score_samples_:类似于
score_samples,但返回的是稀疏矩阵。
归一化优点:
简单易实现 线性可逆
归一化缺点:
对异常值敏感
5)标准化
定义:是一种将数据特征缩放到均值为0,标准差为1的方法。将数据处理为均值为0,标准差为1的正态分布
from sklearn.preprocessing import StandardScaler
# 1、获取数据
data = pd.read_csv("dating.txt")
data = data.iloc[:, :3]
print("data:\n", data)
# 2、实例化一个转换器类
transfer = StandardScaler()
# 3、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)处理后的结果:
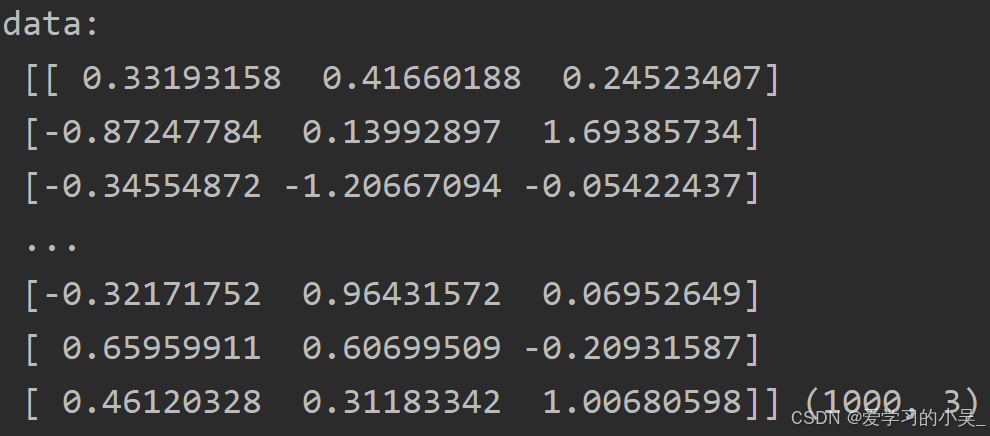
4.特征降维
1)什么是特征降维
降维是减少数据集中特征数量的过程,目的是简化模型,提高计算效率,减少过拟合,并可能提高模型的泛化能力。
降维主要包括两种方式:特征选择以及主成分分析.下面将具体讲述特征选择和主成分分析
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 787
787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









