







最后

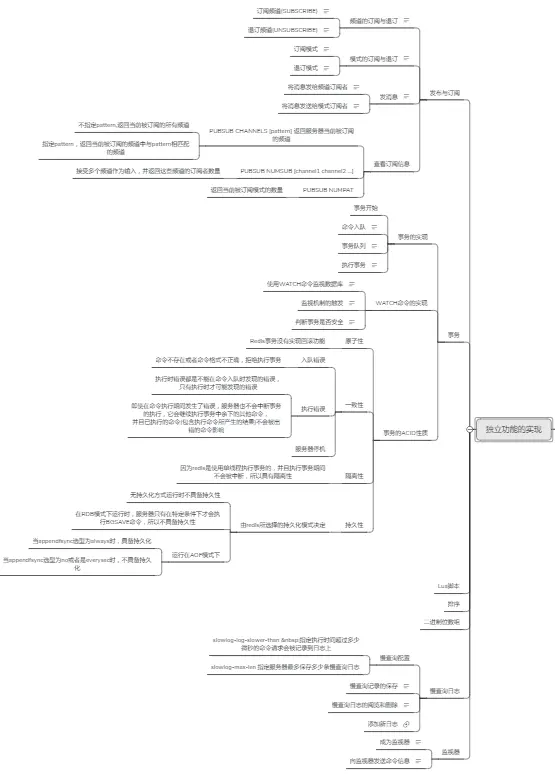
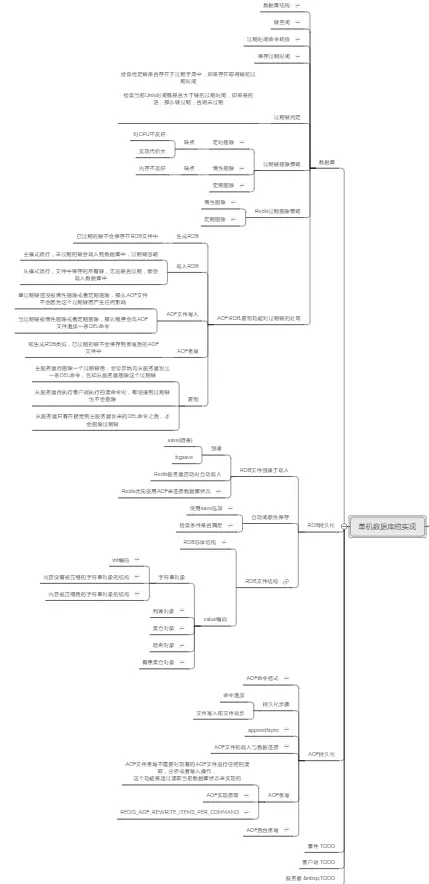
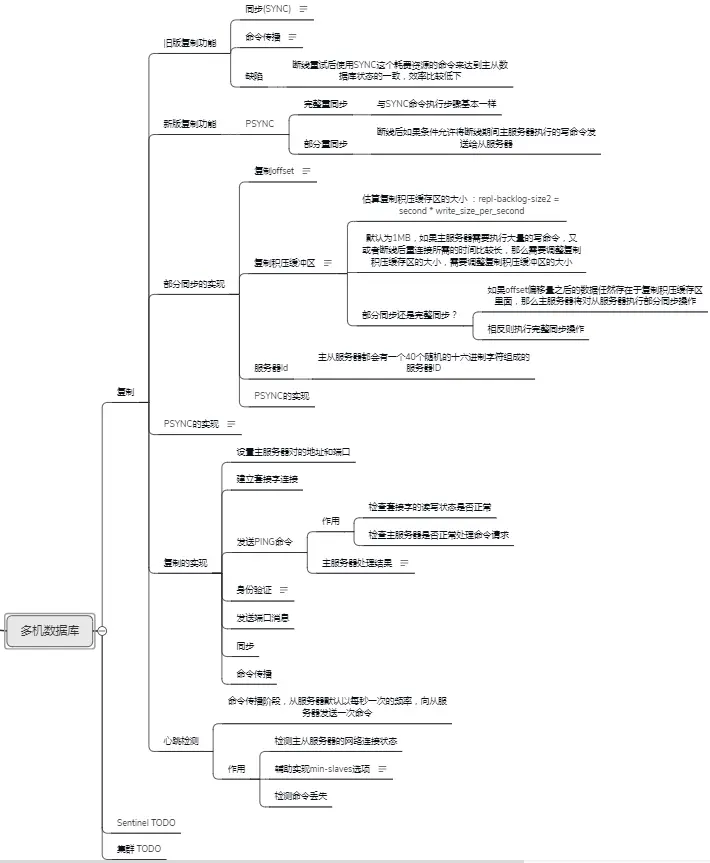
由于篇幅原因,就不多做展示了
| — | — | — | — | — | — |
| Read uncommitted 读未提交 | No | Yes | Yes | Yes | 排他写锁 |
| Read committed 读提交 | No | No | Yes | Yes | 瞬间共享读锁与排他写锁 |
| Repeatable read 重复读 | No | No | No | Yes | 共享读锁与排他写锁 |
| Serializable 序列化 | No | No | No | No | |
隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大。对于多数应用程序,可以优先考虑把数据库系统的隔离级别设为Read Committed。它能够避免脏读取,而且具有较好的并发性能。尽管它会导致不可重复读、幻读这些并发问题,应该由应用程序员采用悲观锁或乐观锁来控制。
举例说明
事务传播行为用来描述由某一个事务传播行为修饰的方法被嵌套进另一个方法的时事务如何传播。
用伪代码说明:
ServiceA {
@Transactional(Propagation=XXX)
void methodA() {
//其他持久层操作数据库
ServiceB.methodB();
}
}
ServiceB {
@Transactional(Propagation=YYY)
void methodB() {
//持久层操作数据库
}
}
代码中methodA()方法嵌套调用了methodB()方法,methodB()的事务传播行为由@Transactional(Propagation=YYY)设置决定。
Spring中七种事务传播行为
| 事务传播行为类型 | 说明 |
| — | — |
| PROPAGATION_REQUIRED | 如果当前没有事务,就新建一个事务,如果已经存在一个事务中,加入到这个事务中。这是最常见的选择。 |
| PROPAGATION_SUPPORTS | 支持当前事务,如果当前没有事务,就以非事务方式执行。 |
| PROPAGATION_MANDATORY | 使用当前的事务,如果当前没有事务,就抛出异常。 |
| PROPAGATION_REQUIRES_NEW | 新建事务,如果当前存在事务,把当前事务挂起。 |
| PROPAGATION_NOT_SUPPORTED | 以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。 |
| PROPAGATION_NEVER | 以非事务方式执行,如果当前存在事务,则抛出异常。 |
| PROPAGATION_NESTED | 如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与PROPAGATION_REQUIRED类似的操作。 |
定义非常简单,也很好理解,下面我们就进入代码测试部分,验证我们的理解是否正确。
回答一个问题:当一个Service函数里面既使用Mybatis Mapper,又使用JdbcTemplate操作同一个数据库,能保证二者操作的整体事务么? 答案是可以的,因为事务控制器是在Spring的层面控制的,与持久层框架无关。
新建的Spring Boot项目中,一般都会引用spring-boot-starter或者spring-boot-starter-web,而这两个起步依赖中都已经包含了对于spring-boot-starter-jdbc或spring-boot-starter-data-jpa的依赖。 当我们使用了这两个依赖的时候,框架会自动默认分别注入DataSourceTransactionManager或JpaTransactionManager。
所以我们不需要任何额外配置就可以用@Transactional注解进行事务的管理。在spring框架内实现多个数据库持久层操作的事务,我们只需要在方法或类添加@Transactional注解即可。@Transactional注解只能应用到public可见度的方法上,可以被应用于接口定义和接口方法,方法会覆盖类上面声明的事务。
@Transactional
public int xxx(){
// 增删改持久层操作一
// 增删改持久层操作二
// ……
}
当多个持久层操作在同一个Service层方法上时,能保证多个持久层操作要么都成功,要么都失败。
| 属性名 | 说明 |
| — | — |
| value | 当在配置文件中有多个 TransactionManager , 可以用该属性指定选择哪个事务管理器。 |
| propagation | 事务的传播行为,默认值为 REQUIRED。 |
| isolation | 事务的隔离度,默认值采用 DEFAULT。 |
| timeout | 事务的超时时间,默认值为-1。如果超过该时间限制但事务还没有完成,则自动回滚事务。 |
| read-only | 指定事务是否为只读事务,默认值为 false;为了忽略那些不需要事务的方法,比如读取数据,可以设置 read-only 为 true。 |
| rollback-for | 用于指定能够触发事务回滚的异常类型,如果有多个异常类型需要指定,各类型之间可以通过逗号分隔。 |
| no-rollback- for | 抛出 no-rollback-for 指定的异常类型,不回滚事务。 |
笔者自己将分布式事务分为两种:跨服务的分布式事务,跨库的分布式事务。
5.1.跨库的分布式事务
跨库的分布式事务:一个服务层函数,需要同时操作两个数据库。我们之前给大家讲的例子都是这一种,实际上总的思路:就是有一个“事务管理器”对象统一管理多个数据源事务的提交与回滚。事务管理器协调多数据源进行两段式提交。
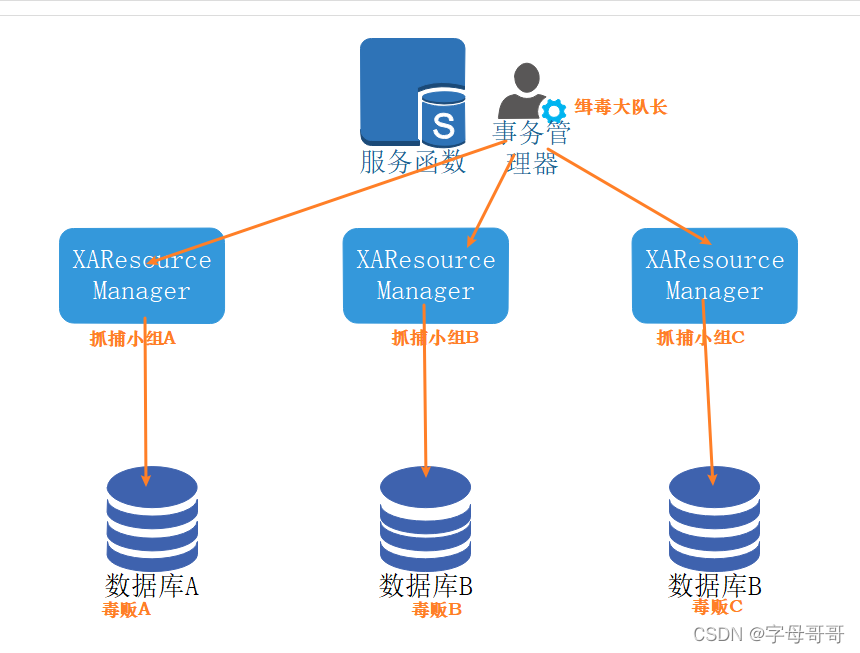
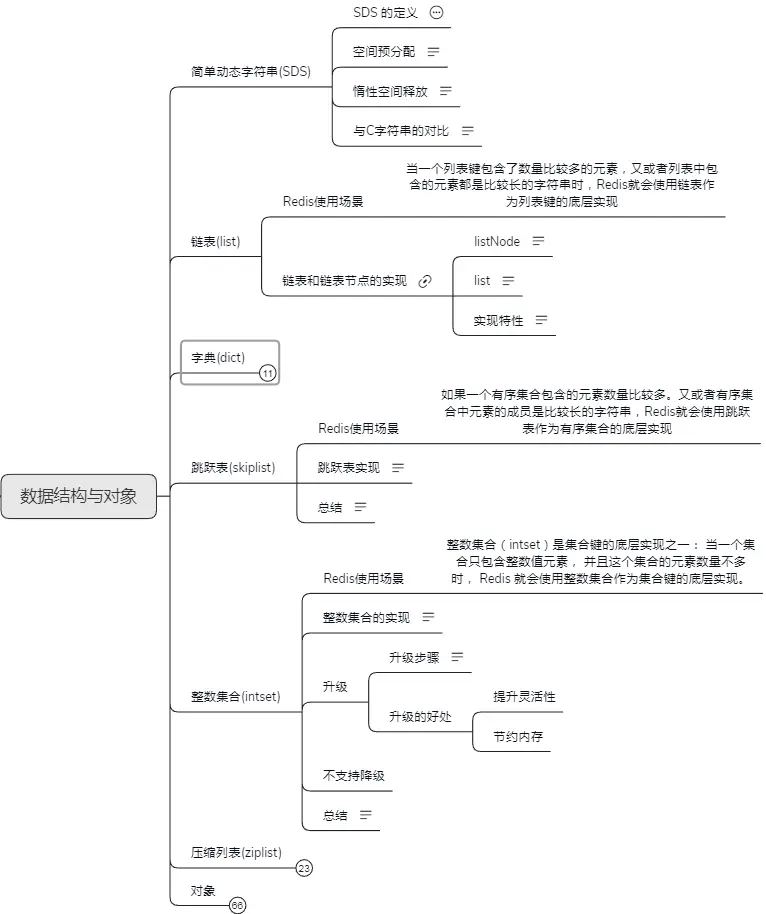
为了大家方便理解:我以小故事方式给大家讲一下两段式提交:
-
背景:以缉毒警察抓捕专案毒贩为背景,目前3位毒贩A、B、C分别住在不同的住址,目前要实施抓捕。将缉毒大队分成三个组,组A、组B、组C分别针对毒贩A、B、C,三个小组统一由“缉毒大队长”协调指挥。
-
三名毒贩住在不同的住址,体现的是“分布式”,3个数据库
-
“缉毒大队长”代表的是“事务管理器”TransctionManager,负责抓捕这个事务的协调指挥工作。
-
三个抓捕小组,代表的是XAResourceManager,是XA/JTA两阶段提交规范的单一资源操作的执行者。
-
-
抓捕的要求是:把三名毒贩同时抓获,不能先抓A,如果A抓捕失败打草惊蛇,可能给B、C报信。要么就全抓到,要么就一个也别抓,免得打草惊蛇。
- 抓捕的要求和我们对于“分布式”事务的要求是一样的,多数据库操作要么都成功,要么都失败。
-
抓捕的步骤:
-
第一步:三个小组分别靠近毒贩A、B、C的住址,然后等待“缉毒大队长”协调指挥。“缉毒大队长”询问A小组是否完成准备抓捕工作,A小组回复:准备完毕。以此类推,“缉毒大队长”询问B、C两个抓捕小组,这三个组都准备完成了,并且没有异常情况发生,第一阶段工作完毕。即:两阶段提交的第一阶段:预提交。
-
如果任何一个小组发现异常,整个行动计划立刻取消。三个抓捕小组同时收队,这个可以认为是数据库事务回滚。
-
第二步:三个小组已经全部准备好了,“缉毒大队长”下命令:“抓捕”。三个抓捕小组同时行动,分别抓捕三名毒贩。确保全部落网,一个也跑不掉。这就好比事务两阶段提交的第二阶段:整体提交。
-
5.2.跨服务的分布式事务
跨服务分布式事务: 也就是说我在做一个服务A的时候,需要通过HTTP网络请求调用多个其他服务,有可能第一个服务B成功了,第二个服务C执行失败了。我们期望的结果是:服务B和服务C都成功。这种分布式单纯的依靠数据库层面就很难解决了。

这种情况一般都是通过最终一致性的方式解决。比如:通过MQ消息队列,给服务B发消息,服务B执行,然后真的做持久化操作数据入库了。
最后
金三银四到了,送上一个小福利!
[外链图片转存中…(img-wFqL3iDo-1715651693186)]


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









