







最后
针对最近很多人都在面试,我这边也整理了相当多的面试专题资料,也有其他大厂的面经。希望可以帮助到大家。
下面的面试题答案都整理成文档笔记。也还整理了一些面试资料&最新2021收集的一些大厂的面试真题(都整理成文档,小部分截图)
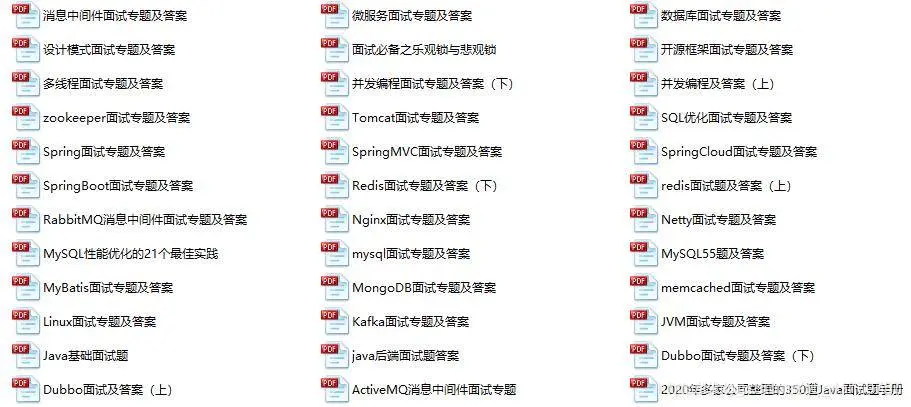
最新整理电子书
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
-
使用MapReduce开发WordCount应用程序
*/
public class CombinerApp {/**
-
Map:读取输入的文件
*/
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable>{LongWritable one = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// 接收到的每一行数据 String line = value.toString(); //按照指定分隔符进行拆分 String[] words = line.split(" "); for(String word : words) { // 通过上下文把map的处理结果输出 context.write(new Text(word), one); }}
}
/**
-
Reduce:归并操作
*/
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {long sum = 0; for(LongWritable value : values) { // 求key出现的次数总和 sum += value.get(); } // 最终统计结果的输出 context.write(key, new LongWritable(sum));}
}
/**
-
定义Driver:封装了MapReduce作业的所有信息
*/
public static void main(String[] args) throws Exception{//创建Configuration
Configuration configuration = new Configuration();// 准备清理已存在的输出目录
Path outputPath = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(configuration);
if(fileSystem.exists(outputPath)){
fileSystem.delete(outputPath, true);
System.out.println(“output file exists, but is has deleted”);
}//创建Job
Job job = Job.getInstance(configuration, “wordcount”);//设置job的处理类
job.setJarByClass(CombinerApp.class);//设置作业处理的输入路径
FileInputFormat.setInputPaths(job, new Path(args[0]));//设置map相关参数
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);//设置reduce相关参数
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);//通过job设置combiner处理类,其实逻辑上和我们的reduce是一模一样的
job.setCombinerClass(MyReducer.class);//设置作业处理的输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
-
## **二、MapReduce案例之Partitioner**
### **1、Partitioner的理解**
第一次使用MapReduce程序的一个常见误解就是认为程序只使用一个reducer。毕竟,单个reducer在处理之前对所有数据进行排序,并将输出数据存储在单独一个输出文件中—谁不喜欢排序数据?我们很容易理解这样的约束是毫无意义的,在大部分时间使用多个reducer是必需的,否则map / reduce理念将不在有用。
Partitioner的作用是针对Mapper阶段的中间数据进行切分,然后将相同分片的数据交给同一个reduce处理。Partitioner过程其实就是Mapper阶段shuffle过程中关键的一部分。
这就对partition有两个要求:
1)均衡负载,尽量的将工作均匀的分配给不同的reduce。
2)效率,分配速度一定要快。
### **2、Partitioner的使用**
在老版本的hadoop中,Partitioner是个接口。而在后来新版本的hadoop中,Partitioner变成了一个抽象类(本人目前使用的版本为2.6.5)。hadoop中默认的partition是HashPartitioner。根据Mapper阶段输出的key的hashcode做划分
在很多场景中,我们是需要通过重写Partitioner来实现自己需求的。例如,我们有全国分省份的数据,我们经常需要将相同省份的数据输入到同一个文件中。这个时候,通过重写Partitioner就可以达到上面的目的。
### **3、代码实例**
**3.1、需求:**
根据手机产品牌子,统计不同手机品牌数量,并将统计结果到不同文件
**3.2、分析:**
Mapreduce中会将map输出的kv对,按照相同key分组,然后分发给不同的reducetask,默认的分发规则为:根据key的hashcode%reducetask数来分发,所以:如果要按照我们自己的需求进行分组,则需要改写数据分发(分组)组件Partitioner,自定义一个CustomPartitioner继承抽象类:Partitioner,然后在job对象中,设置自定义partitioner: job.setPartitionerClass(CustomPartitioner.class)
**3.3、代码实现:**
package MapReduce.demo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class ParititonerApp {
/**
* Map:读取输入的文件
*/
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 接收到的每一行数据
String line = value.toString();
//按照指定分隔符进行拆分
String[] words = line.split(" ");
context.write(new Text(words[0]), new LongWritable(Long.parseLong(words[1])));
}
}
/**
* Reduce:归并操作
*/
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0;
for(LongWritable value : values) {
// 求key出现的次数总和
sum += value.get();
}
// 最终统计结果的输出
context.write(key, new LongWritable(sum));
}
}
public static class MyPartitioner extends Partitioner<Text, LongWritable> {
@Override
public int getPartition(Text key, LongWritable value, int numPartitions) {
if(key.toString().equals("xiaomi")) {
return 0;
}
if(key.toString().equals("huawei")) {
return 1;
}
if(key.toString().equals("iphone7")) {
return 2;
}
return 3;
}
}
/**
* 定义Driver:封装了MapReduce作业的所有信息
*/
public static void main(String[] args) throws Exception{
//创建Configuration
Configuration configuration = new Configuration();
// 准备清理已存在的输出目录
Path outputPath = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(configuration);
if(fileSystem.exists(outputPath)){
fileSystem.delete(outputPath, true);
System.out.println("output file exists, but is has deleted");
}
//创建Job
Job job = Job.getInstance(configuration, "wordcount");
//设置job的处理类
job.setJarByClass(ParititonerApp.class);
//设置作业处理的输入路径
总结
我们总是喜欢瞻仰大厂的大神们,但实际上大神也不过凡人,与菜鸟程序员相比,也就多花了几分心思,如果你再不努力,差距也只会越来越大。
面试题多多少少对于你接下来所要做的事肯定有点帮助,但我更希望你能透过面试题去总结自己的不足,以提高自己核心技术竞争力。每一次面试经历都是对你技术的扫盲,面试后的复盘总结效果是极好的!
的扫盲,面试后的复盘总结效果是极好的!
[外链图片转存中…(img-5A6bGYNa-1715620298452)]

















 621
621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









