







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
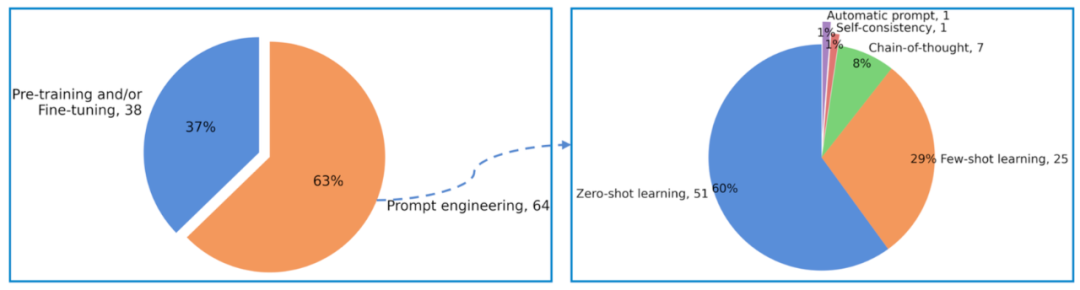
此外,研究人员发现有35项研究在运用大模型之上,还结合了传统测试技术,包括变异测试、差分测试、程序分析、统计分析等,以取得更好的测试有效性和覆盖率。
虽然大模型在各种任务中表现出巨大的潜力,但仍然存在一些局限性,如难以理解和处理复杂的程序结构。
因此,将大模型与其他技术结合起来,以最大程度地发挥它们的优势和避免劣势,从而在特定情况下实现更好的结果,例如生成更多样化和复杂的代码,更好地模拟真实场景。
用大模型找Bug还有哪些挑战?
过去两年中,利用大模型进行软件测试已经有了很多成功的实践。然而,研究人员指出它仍处于早期发展阶段,还有许多挑战和未解决问题需要探索。
挑战1:实现高覆盖率的挑战
探索被测试软件的多样行为以实现高覆盖率始终是软件测试的重要关注点。大模型直接实现所需的多样性仍然具有很大挑战,例如单元测试用例生成中,在SF110数据集上,行覆盖率仅为2%,分支覆盖率仅为1%。
在系统测试输入生成方面,对于面向深度学习库的模糊测试,TensorFlow的API覆盖率为66%(2215/3316)。已有工作通常将变异测试与大模型结合使用,以生成更多样化的输出。
其他潜在的研究方向涉及利用测试相关的数据来训练或微调能够理解测试特性的专用大模型,可以理解测试要求,自主地生成多样化的输出。
挑战2:测试预言的挑战
测试预言问题一直是各种测试应用面临的挑战,已有工作常见做法是将其转化为更容易获取的形式,通常通过差分测试来实现或仅关注容易自动识别的测试预言(例如崩溃类错误),虽然取得了不错效果,但仅适用于少数情况。
探索利用大模型解决其他类型的测试预言问题是非常有价值的。
例如,蜕变测试也是常用的缓解测试预言问题的技术,可以探索结合人机交互或领域知识自动产生蜕变关系,还可探索大模型自动生成基于蜕变关系的测试用例,覆盖各类输入。进一步,像GPT-4这样的多模态大模型也为检测用户界面相关缺陷并辅助推导测试预言提供了可能性。
挑战3:精准评估性能的挑战

△该图由GPT-4 AI生成
**缺乏基准数据集和基于大模型技术潜在的数据泄漏问题给进行严格和全面的性能评估带来了挑战。**研究人员通过检查训练大模型的数据源CodeSearchNet和BigQuery,发现Defect4J基准数据集中使用的四个代码库同时包含在CodeSearchNet中,并且整个Defects4J代码库都包含在BigQuery中。
因此,大模型在预训练过程中已经见过现有的程序修复基准数据集,存在严重的数据泄露问题。所以,需要构建更专门和多样化的基准数据集,并采取措施防止数据泄漏。
挑战4:用于现实项目的挑战
由于对数据隐私的关注,在考虑实际应用时,大多数软件组织倾向于避免使用商用大模型,更愿意采用开源的大模型,并使用组织特定的数据进行训练或微调。
此外,一些公司还考虑到计算能力的限制或关注能源消耗等,倾向于采用中等规模的模型。在这样的现实条件下,要达到与已有研究工作中报告的类似性能是非常具有挑战的。例如,在广泛使用的QuixBugs数据集中,40个Python错误中有39个能够自动修复,40个Java错误中有34个能够自动修复。
然而,当涉及到从Stack Overflow收集的深度学习程序(代表实际的编码实践)时,72个Python错误中仅有16个能够自动修复。如何更关注现实需求研发相应的技术才能更利于技术落地和实际应用。
大模型也带来了研究机遇
利用大模型进行软件测试也带来了许多研究机遇,对于软件测试领域的发展大有益处。
机遇1:利用大模型进行更多样化的软件测试任务和阶段
在测试任务的初期阶段,目前LLM还未得到有效应用(编者注:其实在早期,LLM更能发挥作用)。主要原因有两方面:一是早期测试任务的主观性,需要专家进行评估;二是早期阶段缺乏开放数据资源,这限制了大模型的性能表现。
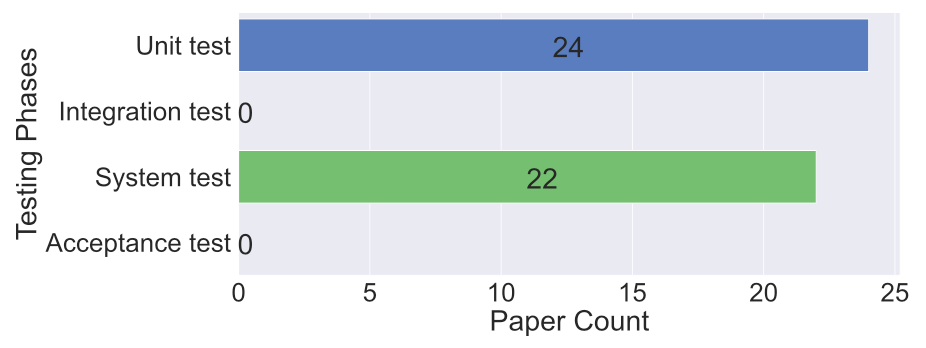
此外,如下图所示,虽然大模型在单元测试和系统测试方面得到了广泛应用,但在集成测试和验收测试方面的应用相对较少。总之,如何充分利用大模型进行更多样化的软件测试任务和测试阶段是一个值得深入研究的新方向。例如,在验收测试方面,大模型可以与人类测试人员协同工作,以自动生成测试用例并评估测试覆盖率。
机遇2:将大模型应用于更广泛的测试类型和软件
一方面,虽然大模型在功能测试方面得到了广泛应用,但在性能测试和可用性测试等其他方面应用较少,这可能是因为这些测试已有一些专门且让人满意的模型和工具。
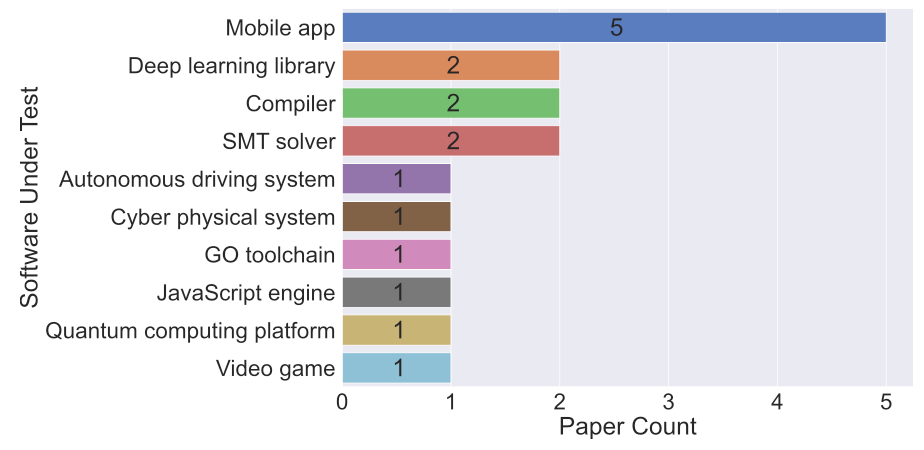
但将大模型与这些工具相结合仍不失为一个潜在的研究方向,例如利用大模型整合性能测试工具,并模拟真实用户行为来产生不同类型的工作负载。另一方面,如下图所示,已经有研究在多种类型的软件测试中成功应用了大模型,例如移动应用,深度学习库、自动驾驶系统等。不仅能将现有技术迁移到其他类型的软件上,也可以针对某类软件的特性,研发针对性的技术。
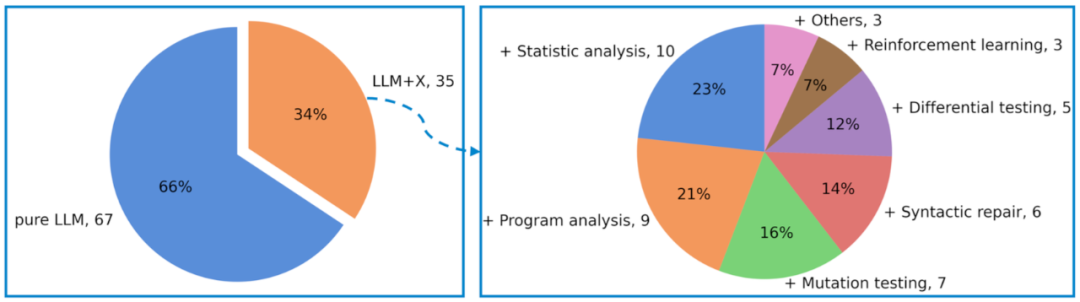
机遇3:整合先进的提示工程技术
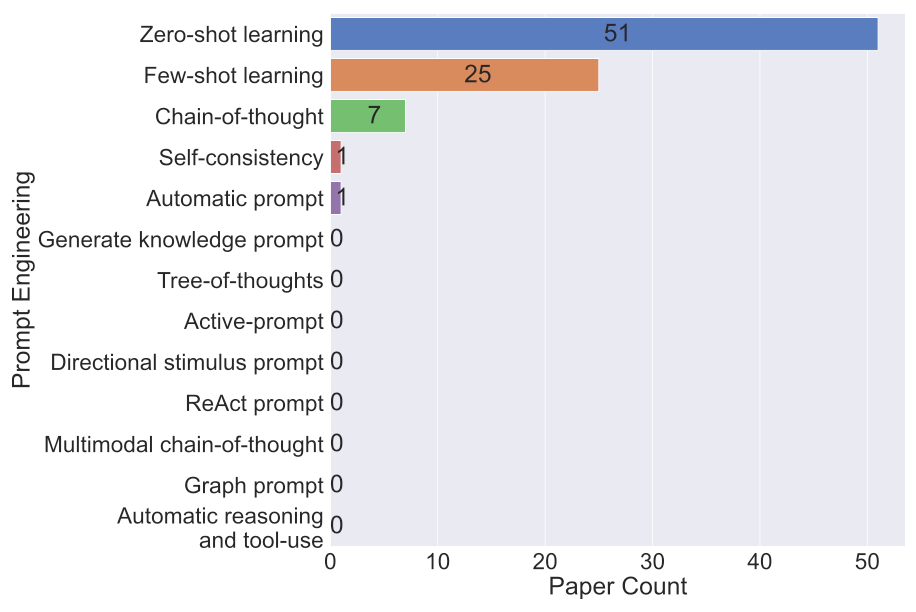
现有研究尚未充分挖掘大模型的潜力,如下图所示,仅使用了五种最常见的提示工程技术。未来的研究应该探索更高级的提示工程技术(如图中的思维树、多模态思维链等),以更充分地发挥或增强大模型的理解和推理能力。
机遇4:和传统技术结合
目前关于大模型在解决软件测试问题方面的能力还没有明确的共识,有研究将大模型与传统软件测试技术相结合取得了很好的效果,这可能意味着大模型并非解决软件测试问题的唯一灵丹妙药。
行动吧,在路上总比一直观望的要好,未来的你肯定会感谢现在拼搏的自己!如果想学习提升找不到资料,没人答疑解惑时,请及时加入群: 786229024,里面有各种测试开发资料和技术可以一起交流哦。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
s/4f45ff00ff254613a03fab5e56a57acb)**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

















 2395
2395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









