




page_text = response.text
tree = etree.HTML(page_text)
文本匹配
首先观察,发现所有的图片地址都在figure标签中,所有的figure标签又都存在于 div class=“gallery_inner” 中,所以我们先匹配到div这个标签。
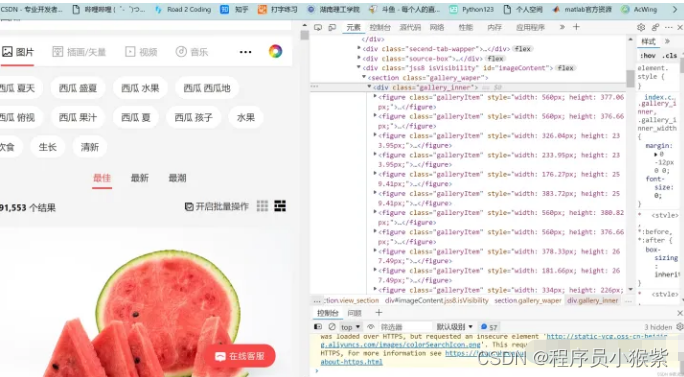
在xpath中//表示在该本文中搜索所有的div标签,[@class=“gallery_inner”]则将div标签限定,再通过/figure找到所有的标签。
xpath进行匹配:
figure_list = tree.xpath('//div[@class="gallery_inner"]/figure')
接着我们对所有的li标签进行循环,依次对每个图片地址进行操作。
for figure in figure_list:
img_src = figure.xpath('./a/img/@data-src')[0]
img_src = 'https:' + img_src
img_name = img_src.split('/')[-1]
img_data = requests.get(url=img_src,headers=header).content
img_path = 'piclitl/' + img_name
with open(img_path, 'wb') as fp:
fp.write(img_data)
print(img_name, '下载成功')
大致框架搭好后运行,发现了两个报错:
一、在对figure标签请求时,匹配没有结果出现列表超
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4361
4361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









