







目录
一、pandas是什么?
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
前言
在这里讲一下Python中分类分析中的聚类分析中的K-均值和层次聚类
二、使用步骤
1.引入库
代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import calinski_harabaz_score2.读入数据
代码如下:
#读取数据
data = pd.read_csv('iris.csv')
data.head()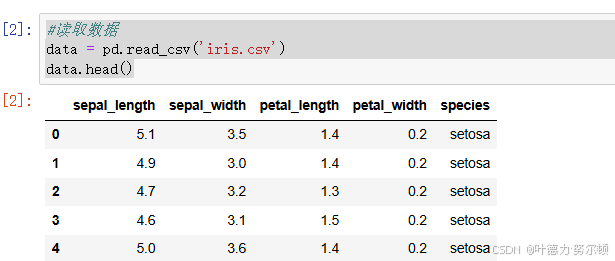
三、聚类分析
聚类分析是一组将研究对象分为相对同质的群组的统计分析技术
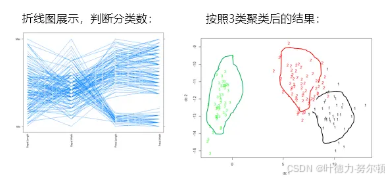
聚类分析对具有共同趋势或结构的数据进行分组,将数据项分组成多个簇(类),簇之间的数据差别尽可能大,簇内的数据差别尽可能小,即“最小化”簇内的相似性,最大化簇间的相似性。它主要解决的是把一群对象划分成若干个组的问题。划分的依据是聚类问题的核心。所谓“物以类聚,人以群分”,故得名聚类。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1155
1155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









