







对象篇


模块化编程-自研模块加载器

开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】

*/
const http = require(‘http’)
const fork = require(‘child_process’).fork
const server = http.createServer(() => {
if(req.url === ‘/get-sum’) {
console.info(‘主进程 id’, process.pid)
// 开启子进程
const computeProcess = fork(‘./computer.js’)
computeProcess.send(‘开始计算’)
computeProcess.on(‘message’, data => {
console.info(‘主进程接收到信息:’, data)
res.end('sum is ’ + data)
})
computeProcess.on(‘close’, data => {
console.info(‘主进程因报错而退出’)
computeProcess.kill()
res.end(‘error’)
})
}
})
server.listen(3000, () => {
console.info(‘localhost: 3000’)
})
/**
- computed.js 子进程,计算
*/
function getSum() {
let sum = 0
for (let i = 0; i <10000; i++) {
sum += i
}
return sum
}
//子进程可以通过这种自定义事件的方式来监听
process.on(‘message’, data => {
console.log(‘子进程 id’, process.pid)
console.log('子进程接收到的信息‘, data)
const sum = getSum()
// 发送消息给主进程
process.send(sum)
})
//localhost: 30000
// 主进程 id: 80780
// 子进程 id: 80781
// 子进程接收到的信息: 开始计算
// 主进程接收到的信息: 49995000
使用cluster方式开启多进程
/**
- cluster:多子进程,多个服务
- 根据CPU核数派生子进程,每个子进程创建一个Http服务
*/
const http = require(‘http’)
const cpuCoreLength = require(‘os’).cpus().length //获取CPU核数
// 引入cluster
const cluster = require(‘cluster’)
if(cluster.isMaster) { // 是cluster的主进程
for (let i = 0; i < cpuCoreLength; i++) {
cluster.fork() // 开启子进程
}
cluster.on(‘exit’, worker => { // worker表示当前进程的实例
console.log(‘子进程退出’)
cluster.fork() // 进程守护
})
} else {
// 多个子进程会共享一个TCP连接,提供一份网络服务
const server = http.createServer((rep, res) => {
res.writeHead(200)
res.end(‘done’)
})
server.listen(3000)
}
总结:Node.js中开启子进程child\_process.fork和cluster.fork;使用send和on传递消息
扩展:工作中实际使用PM2 完成进程守护和开启多个进程 PM2 是一个针对Node.js应用的进程管理工具,可以用于进程守护、负载平衡、日志管理等。通过PM2可以方便地启动、停止、重启应用程序,并监控应用程序的运行状态
#### 6. 请描述js-bridge的实现原理?
**什么是JS Bridge?**
JSBridge是一种在Webview和Native之间进行通信的技术。JS 无法直接调用native API,需要通过一些特定"格式" 来调用,这些"格式"统称为JS-Bridge ,例如微信的JSSDK。基本实现原理:
1. 在Native端中创建一个Javascript对象,通过WebView的addJavascriptInterface()方法将该对象注入到WebView中。
2. 在Web端中通过Javascript代码调用该对象的方法,从而实现与Native的通信。
3. 在Native端中捕获Javascript代码的调用请求,解析请求参数并执行相应的操作(可执行一些特定操作,如打开摄像头、访问设备传感器等)。
4. 将操作结果通过Javascript代码的回调函数返回给Web端。
5. 在Web端中通过回调函数获取到Native端返回的数据,并进行相应的处理。
通过这种方式,JSBridge实现了Webview和Native之间的双向通信,可以使得Web应用和Native应用之间实现无缝的交互。
**JS Bridege的常见实现方式**
WebView方式:通过WebView加载一个网页,然后在网页中通过JavaScript代码调用Native代码来实现功能。这种方式适用于需要在网页中嵌入Native功能的场景
URL Scheme:通过定义特定的 URL Scheme,JavaScript 可以通过修改页面链接的方式触发原生应用执行相应操作。原生应用可以通过拦截特定的 URL Scheme 来响应 JavaScript 的请求。
// 封装JS-bridge
const sdk = {
invoke(url, data = {}, onSuccess, onError){
const iframe = document.createElement(‘iframe’)
iframe.style.visibility = ‘hidden’
document.body.appendChild(iframe)
iframe.onload = () => {
const content = iframe1.contentWindow.document.body.innerHTML
onSuccess(JSON.parse(content))
iframe.remove()
}
iframe.onError = () => {
onError()
iframe.remove()
}
iframe.src = my-app-name://${url}?data=${JSON.stringify(data)}
},
fn1(data, onSuccess, onError) {
this.invoke(‘api/fn1’,data, onSuccess, onError)
},
fn2(data, onSuccess, onError) {
this.invoke(‘api/fn2’,data, onSuccess, onError)
},
}
sdk.fn1()
#### 7. requestIdleCallbcak和requestAnimationFrame有什么区别?
requestIdleCallback并不是一个常用的API,由于React 16版本之后引入React fiber引起关注。React fiber可以将组件树转换为链表,可以分段渲染;渲染时可以暂停,去执行其他高优先级任务,空闲时再继续渲染,这样就会存在如何判断空闲的问题?
requestIdleCallback该方法会在浏览器空闲时调用回调函数,即在主线程上没有其他高优先级任务需要执行时。它会尽量在空闲时间内执行,以避免对用户交互和页面渲染的干扰。
区别:
requestAnimationFrame每次渲染完都会执行,高优;requestIdleCallback空闲时才会执行,低优。
// 演示 requestIdleCallbcak和requestAnimationFrame
change
扩展:它们是宏任务还是微任务?
两者都是宏任务;要等到DOM渲染完才执行,肯定宏任务
window.οnlοad=() => {
console.info(‘start’)
setTimeout(() => {
console.info(‘timeout’)
})
window.requestAnimationFrame(() =>{
console.info(‘requestAnimationFrame’)
})
window.requestIdleCallback(() =>{
console.info(‘requestIdleCallback’)
})
console.info(‘end’)
}
// start
// end
// timeout
// requestAnimationFrame 高优,不管位置总会在requestIdleCallback前执行
// requestIdleCallback
在 requestIdleCallback 中进行 DOM 操作可能导致页面再次重绘,因为此时页面布局已经完成,对 DOM 的修改可能会触发重新计算布局和绘制; 相比之下,requestAnimationFrame 更适合执行需要频繁重绘页面的任务,包括动画和其他与绘制相关的操作。在 requestAnimationFrame 回调函数中进行 DOM 操作可以确保这些操作在下一帧绘制之前完成,避免了不必要的重绘和性能损耗。
#### 8. Vue每个生命周期都做了什么?
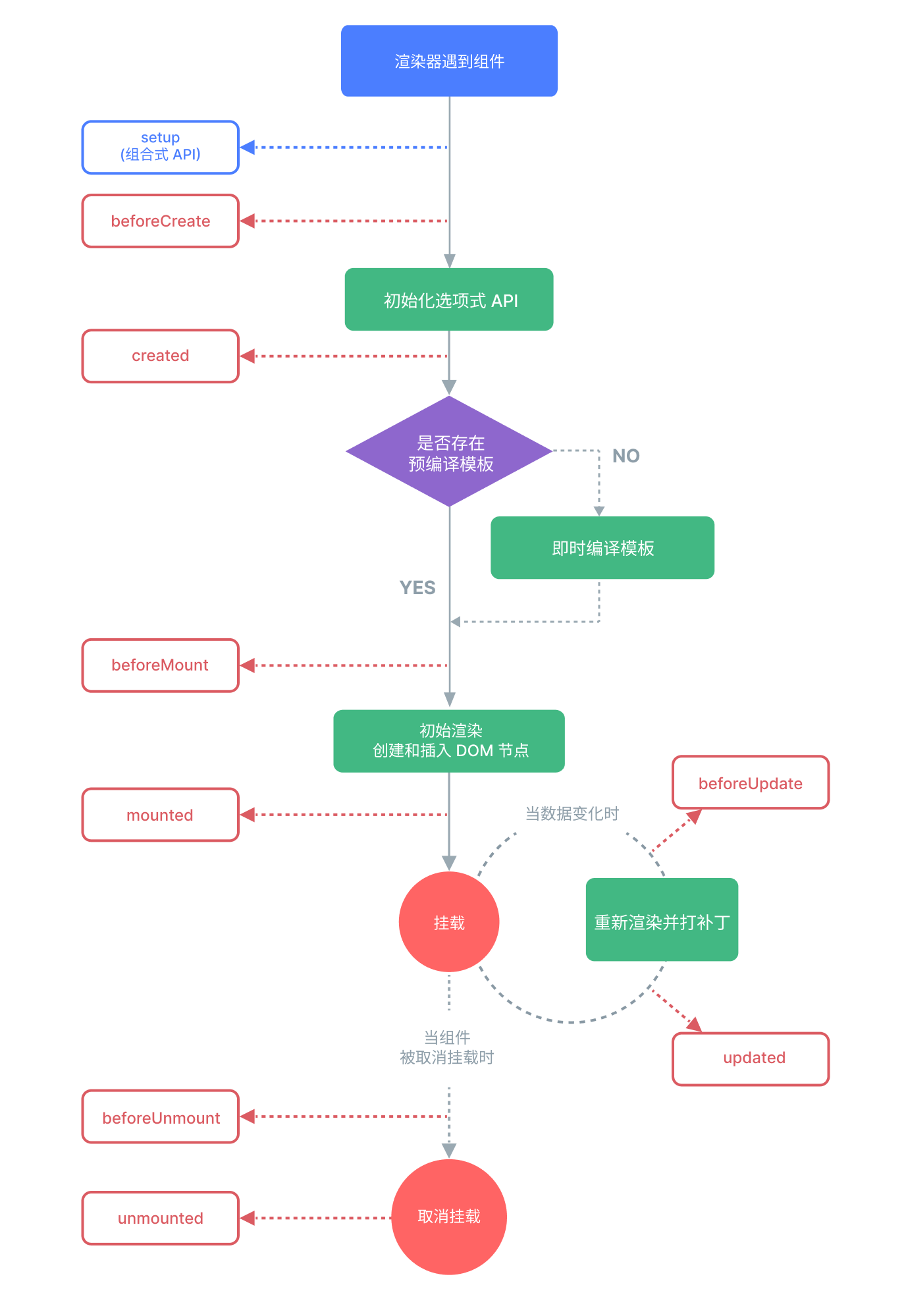
**Vue 3生命周期:**
**beforeCreate:**
创建一个空白的Vue实例;data method尚未被初始化,不可使用;
created:
Vue实例初始化完成,完成响应式绑定;data method都已经初始化完成,可调用
尚未开始渲染模板;此时可执行和JS模型有关,但是与DOM节点没有关系的事情
beforeMount:
编译模板,调用render生成vdom;还没有开始渲染DOM(vdom是JS级别)
mounted:
完成DOM渲染,组件创建完成;开始由"创建阶段"进入"运行阶段"(更新,销毁)
beforeUpdate:
data发生了变化后;准备更新DOM(尚未更新DOM)
updated:
data发生变化,且DOM更新完成;(**不要在updated中修改data,可能会导致死循环**)
beforeUnmount:
组件进入销毁阶段(尚未销毁,可正常使用);可移除、解绑一些全局事件、自定义事件
unmounted:
组件被销毁;所有的子组件也都被销毁
扩展1:keep-alive组件的生命周期
onActiveed:缓存组件被激活,当组件被插入到 DOM 中时调用
onDeactived:缓存组件被隐藏,当组件从 DOM 中被移除时调用
扩展2:Vue什么时候有操作DOM比较合适?
**mounted和updated都不能保证子组件全部挂载完成**;
**使用$nextTick渲染DOM**
扩展3:Ajax应该放在哪个生命周期?
推荐:mounted:将 Ajax 请求放在mounted生命周期钩子函数中的好处是,在页面渲染完成后立即发起请求,以获取数据并更新组件。这样可以确保组件被正确渲染后再进行数据请求,避免出现数据未就绪时的 UI 空白或异常情况.
扩展4:Vue3 Composition API生命周期有何区别?
setup代替了beforeCreate和created
使用Hooks函数的形式,如mounted改为onMounted()
#### 9. Vue2、Vue3和React三者的Diff算法有什么区别?
**介绍diff算法**
diff算法很早就有,且应用广泛,例如Git hub的Pull Request中代码diff;如果要严格diff两棵树,时间复杂度O(n^3), 不可用;
Tree diff的优化,只比较同一层级,不跨级比较,tag不同则删掉重建(不在去比较内部的细节),子节点通过key区分(key的重要性),优化后的时间复杂度O(n)。
Vue2、Vue3 和 React 底层都有用到 DOM diff,它们的相同点都是同级比对,复杂度差不多;时间复杂度来说呢,Vue2应该是比React快一倍的,但是Vue3在JS层,它的复杂度就不是O(n)了,而是O(nlogN);而 Vue3为什么复杂度更高了呢,因为Vue3的核心是为了减少DOM的移动,因为在浏览器中JS速度是很快的,但是 DOM 的移动是很昂贵的,而且 DOM 渲染速度很慢,很影响性能。
**React diff - 仅右移**
React中尽量减少跨层级的操作;可以使用shouldComponentUpdate() 来判断是否需要diff,避免react重复渲染;添加唯一key,减少不必要的重渲染
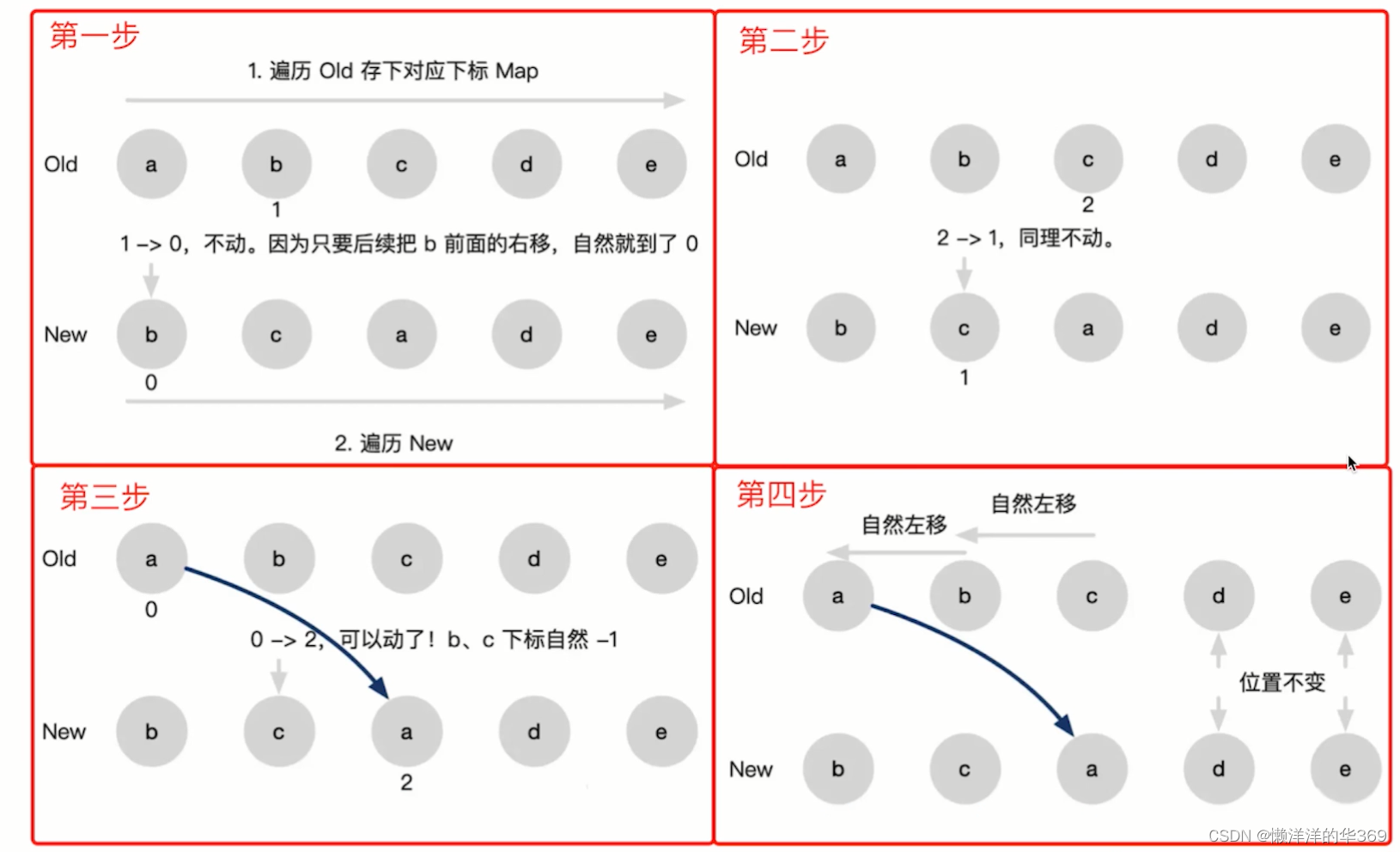
**Vue2 - 双端比较**
Vue2双端diff,指针从两端往中间移动,借助key值找到可复用的节点,再进行相关操作。相比React的Diff算法,同样情况下可以减少移动节点次数,减少不必要的性能损耗,更加的优雅
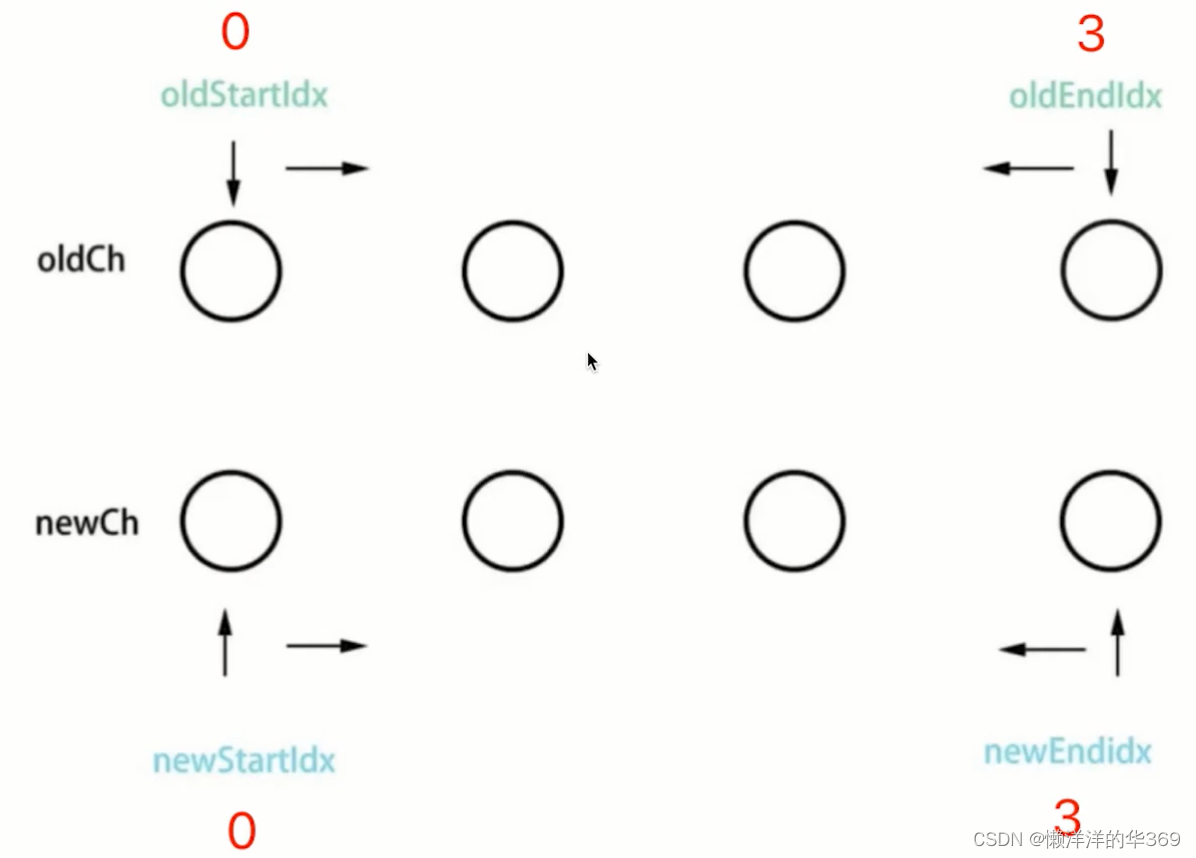
**Vue3 - 最长递增子序列**
此处使用双端算法,将oldChildren的最长递增子序列是[0,1,2,3,4,7]对应的元素,移动F添加H;
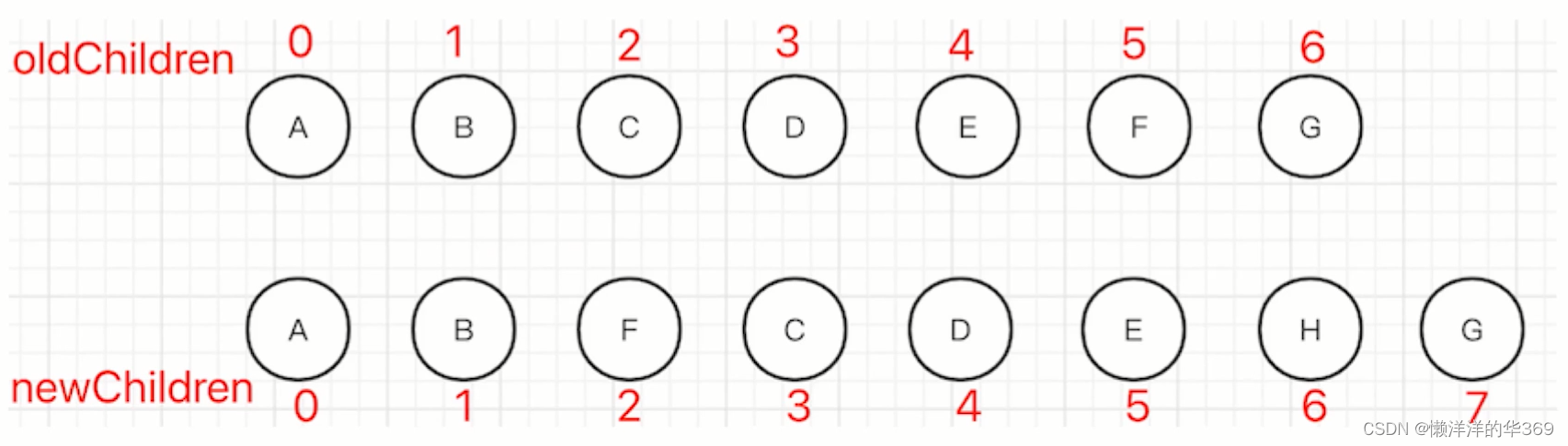
扩展1: Vue3使用diff算法相对于Vue2的优势
* 最长递增子序列算法 Vue3.0的diff算法采用了最长递增子序列算法,能够减少不必要的DOM操作,提升性能。
* 静态标记 Vue3.0中,编译器会对静态节点进行标记,在更新时可以直接跳过这些静态节点,减少DOM操作,提升性能。
* 缓存数组 Vue3.0中每次更新时会将新旧 VNode 数组缓存起来,只对数组中不同的VNode进行比对,减少比对次数,提升性能。
* 动态删除操作 Vue3.0中,对于动态删除操作,采用了异步队列的方式进行,能够将多个删除操作合并为一个,减少DOM操作,提升性能。 总的来说,Vue 3.0的diff算法相比Vue 2.0更加高效,能够减少不必要的DOM操作,提升应用的性能。
参考:
[Vue2、Vue3 和 React 中 Diff 算法的区别\_19.vue2和vue3和react的diff算法区别?-优快云博客文章浏览阅读566次。DOM diff 本质上就是在数据响应式的场景下,降低了用户对 DOM 的直接操作。Vue2、Vue3 和 React 底层都有用到 DOM diff,它们的相同点呢,都是同级比对,复杂度差不多;那不同点呢,一个是节点移动的方向。比如 React 是从左向右移动,而 Vue2 是双端 diff,也就是指针是两边向中间移动的。而 Vue3 在 Vue2 双端 diff 的基础上,加上了最长递增子序列优化算法。\_19.vue2和vue3和react的diff算法区别?https://blog.youkuaiyun.com/qq\_38290251/article/details/133247855](https://blog.youkuaiyun.com/qq_38290251/article/details/133247855 "Vue2、Vue3 和 React 中 Diff 算法的区别_19.vue2和vue3和react的diff算法区别?-优快云博客")
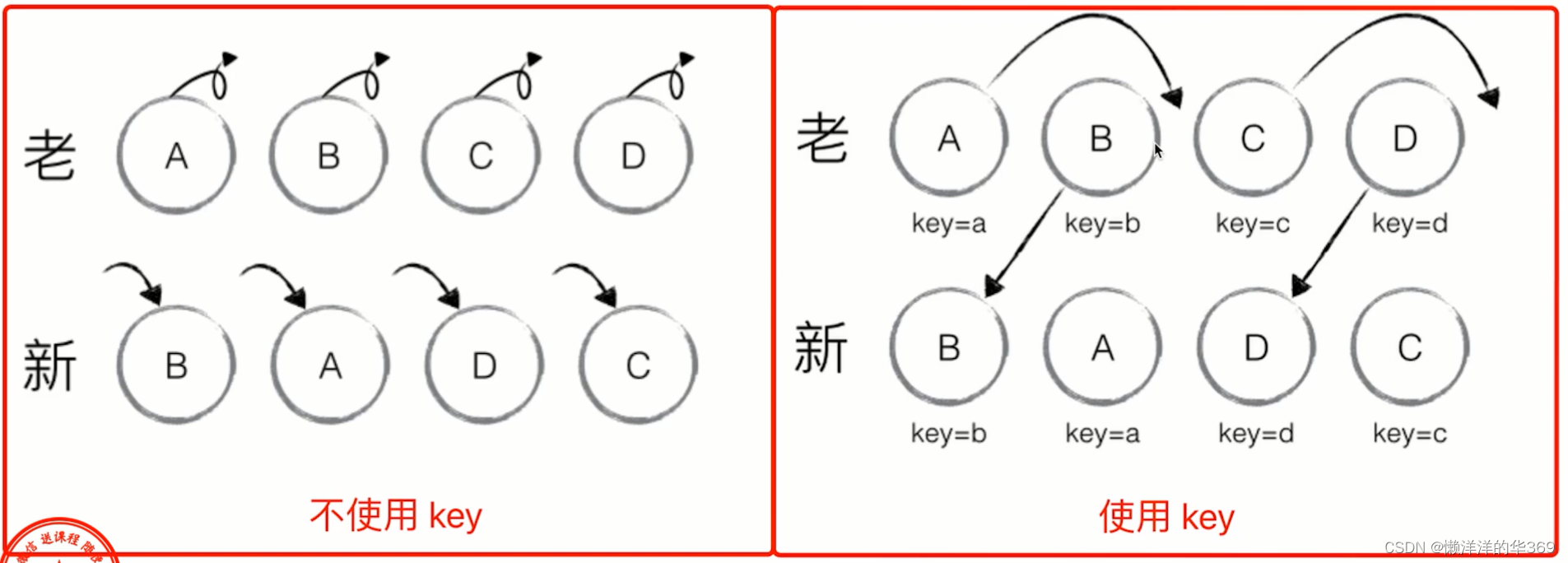
扩展2:Vue React为何循环时必须使用key?
vdom diff 算法会根据key判断元素是否要删除;匹配了key,则只移动元素 - 性能较好;未匹配key, 则删除重建 - 性能差
以React key 为例,没有可以则重建,由可以匹配后移动即可
#### 10. Vue-router的MemoryHistory(abstract)是什么?
Vue-router的三种模式
Hash模式:
在 Hash 模式下,URL中会带有#符号,例如 [http://yourdomain.com/#/about;]( ) 优点是兼容性好,因为不同浏览器对 hash 支持较好; 缺点是 URL 中带有 # 符号,可能不够美观。
History模式:
在 History 模式下,URL 不带有#符号,看起来更加干净,例如 [http://yourdomain.com/about;]( ) 这种模式需要服务器端配置支持,以处理直接访问这些 URL 时的情况。否则会导致 404 错误; 可以通过调用 router.pushState 使用 HTML5 History API 来实现历史记录导航。
MenmoryHistory(V4之前叫做abstract history)
Memory History 模式是一种基于内存的路由管理方式,不会改变浏览器的 URL,也不会与浏览器历史记录交互。它主要用于非浏览器环境下,比如服务器端渲染(SSR)或者单元测试中
const router = new VueRouter({
mode: ‘abstract’,
routes: [
{ path: ‘/home’, component: Home },
{ path: ‘/about’, component: About }
]
})
/**
- 通过设置 mode:‘abstract’, Vue Router将以内存中的方式管理路由,而不会影响浏览器的URL。这种模式适用
- 于需要在非浏览器环境中进行路由管理的情况,例如在服务器端渲染时预先加载路由等场景
最后
本人分享一下这次字节跳动、美团、头条等大厂的面试真题涉及到的知识点,以及我个人的学习方法、学习路线等,当然也整理了一些学习文档资料出来是给大家的。知识点涉及比较全面,包括但不限于前端基础,HTML,CSS,JavaScript,Vue,ES6,HTTP,浏览器,算法等等
前端视频资料:
bstract’, Vue Router将以内存中的方式管理路由,而不会影响浏览器的URL。这种模式适用
- 于需要在非浏览器环境中进行路由管理的情况,例如在服务器端渲染时预先加载路由等场景
最后
本人分享一下这次字节跳动、美团、头条等大厂的面试真题涉及到的知识点,以及我个人的学习方法、学习路线等,当然也整理了一些学习文档资料出来是给大家的。知识点涉及比较全面,包括但不限于前端基础,HTML,CSS,JavaScript,Vue,ES6,HTTP,浏览器,算法等等
[外链图片转存中…(img-4Y98dF08-1715677559932)]
前端视频资料:
[外链图片转存中…(img-PIHQazpq-1715677559933)]


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









