







如何自学黑客&网络安全
黑客零基础入门学习路线&规划
初级黑客
1、网络安全理论知识(2天)
①了解行业相关背景,前景,确定发展方向。
②学习网络安全相关法律法规。
③网络安全运营的概念。
④等保简介、等保规定、流程和规范。(非常重要)
2、渗透测试基础(一周)
①渗透测试的流程、分类、标准
②信息收集技术:主动/被动信息搜集、Nmap工具、Google Hacking
③漏洞扫描、漏洞利用、原理,利用方法、工具(MSF)、绕过IDS和反病毒侦察
④主机攻防演练:MS17-010、MS08-067、MS10-046、MS12-20等
3、操作系统基础(一周)
①Windows系统常见功能和命令
②Kali Linux系统常见功能和命令
③操作系统安全(系统入侵排查/系统加固基础)
4、计算机网络基础(一周)
①计算机网络基础、协议和架构
②网络通信原理、OSI模型、数据转发流程
③常见协议解析(HTTP、TCP/IP、ARP等)
④网络攻击技术与网络安全防御技术
⑤Web漏洞原理与防御:主动/被动攻击、DDOS攻击、CVE漏洞复现
5、数据库基础操作(2天)
①数据库基础
②SQL语言基础
③数据库安全加固
6、Web渗透(1周)
①HTML、CSS和JavaScript简介
②OWASP Top10
③Web漏洞扫描工具
④Web渗透工具:Nmap、BurpSuite、SQLMap、其他(菜刀、漏扫等)
恭喜你,如果学到这里,你基本可以从事一份网络安全相关的工作,比如渗透测试、Web 渗透、安全服务、安全分析等岗位;如果等保模块学的好,还可以从事等保工程师。薪资区间6k-15k
到此为止,大概1个月的时间。你已经成为了一名“脚本小子”。那么你还想往下探索吗?
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:282G全网最全的网络安全资料包评论区留言即可领取!
7、脚本编程(初级/中级/高级)
在网络安全领域。是否具备编程能力是“脚本小子”和真正黑客的本质区别。在实际的渗透测试过程中,面对复杂多变的网络环境,当常用工具不能满足实际需求的时候,往往需要对现有工具进行扩展,或者编写符合我们要求的工具、自动化脚本,这个时候就需要具备一定的编程能力。在分秒必争的CTF竞赛中,想要高效地使用自制的脚本工具来实现各种目的,更是需要拥有编程能力.
如果你零基础入门,笔者建议选择脚本语言Python/PHP/Go/Java中的一种,对常用库进行编程学习;搭建开发环境和选择IDE,PHP环境推荐Wamp和XAMPP, IDE强烈推荐Sublime;·Python编程学习,学习内容包含:语法、正则、文件、 网络、多线程等常用库,推荐《Python核心编程》,不要看完;·用Python编写漏洞的exp,然后写一个简单的网络爬虫;·PHP基本语法学习并书写一个简单的博客系统;熟悉MVC架构,并试着学习一个PHP框架或者Python框架 (可选);·了解Bootstrap的布局或者CSS。
8、超级黑客
这部分内容对零基础的同学来说还比较遥远,就不展开细说了,附上学习路线。

网络安全工程师企业级学习路线

如图片过大被平台压缩导致看不清的话,评论区点赞和评论区留言获取吧。我都会回复的
视频配套资料&国内外网安书籍、文档&工具
当然除了有配套的视频,同时也为大家整理了各种文档和书籍资料&工具,并且已经帮大家分好类了。

一些笔者自己买的、其他平台白嫖不到的视频教程。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
"Attempting to start secure cluster, skipping datanodes. " \
"Run start-secure-dns.sh as root to complete startup."
else
#执行hadoop-daemons.sh 调用bin/hdfs指令 启动datanode守护线程
“
H
A
D
O
O
P
P
R
E
F
I
X
/
s
b
i
n
/
h
a
d
o
o
p
−
d
a
e
m
o
n
s
.
s
h
"
−
−
c
o
n
f
i
g
"
HADOOP_PREFIX/sbin/hadoop-daemons.sh" \ --config "
HADOOPPREFIX/sbin/hadoop−daemons.sh" −−config"HADOOP_CONF_DIR”
–script “$bin/hdfs” start datanode $dataStartOpt
fi
#---------------------------------------------------------
secondary namenodes (if any)
SECONDARY_NAMENODES= ( ( (HADOOP_PREFIX/bin/hdfs getconf -secondarynamenodes 2>/dev/null)
if [ -n “
S
E
C
O
N
D
A
R
Y
N
A
M
E
N
O
D
E
S
"
]
;
t
h
e
n
e
c
h
o
"
S
t
a
r
t
i
n
g
s
e
c
o
n
d
a
r
y
n
a
m
e
n
o
d
e
s
[
SECONDARY_NAMENODES" ]; then echo "Starting secondary namenodes [
SECONDARYNAMENODES"];thenecho"Startingsecondarynamenodes[SECONDARY_NAMENODES]”
#执行hadoop-daemons.sh 调用bin/hdfs指令 启动secondarynamenode守护线程
“
H
A
D
O
O
P
P
R
E
F
I
X
/
s
b
i
n
/
h
a
d
o
o
p
−
d
a
e
m
o
n
s
.
s
h
"
−
−
c
o
n
f
i
g
"
HADOOP_PREFIX/sbin/hadoop-daemons.sh" \ --config "
HADOOPPREFIX/sbin/hadoop−daemons.sh" −−config"HADOOP_CONF_DIR”
–hostnames “
S
E
C
O
N
D
A
R
Y
N
A
M
E
N
O
D
E
S
"
−
−
s
c
r
i
p
t
"
SECONDARY_NAMENODES" \ --script "
SECONDARYNAMENODES" −−script"bin/hdfs” start secondarynamenode
fi
…
…省略细节…
…
eof
在start-dfs.sh脚本中,先执行hdfs-config.sh脚本加载环境变量,然后通过hadoop-daemons.sh脚本又调用bin/hdfs指令来分别开启namenode、datanode以及secondarynamenode等守护进程。
如此我们也能发现,其实直接执行hadoop-daemons.sh脚本,配合其用法,也应该可以启动HDFS等相关守护进程。
#### 4、sbin/hadoop-daemons.sh
在所有的从节点上运行hadoop指令
Run a Hadoop command on all slave hosts.
#hadoop-daemons.sh脚本的用法,
usage=“Usage: hadoop-daemons.sh [–config confdir] [–hosts hostlistfile] [start|stop] command args…”
if no args specified, show usage
if [ $# -le 1 ]; then
echo $usage
exit 1
fi
bin=dirname "${BASH_SOURCE-$0}"
bin=cd "$bin"; pwd
DEFAULT_LIBEXEC_DIR="
b
i
n
"
/
.
.
/
l
i
b
e
x
e
c
H
A
D
O
O
P
L
I
B
E
X
E
C
D
I
R
=
bin"/../libexec HADOOP_LIBEXEC_DIR=
bin"/../libexecHADOOPLIBEXECDIR={HADOOP_LIBEXEC_DIR:-$DEFAULT_LIBEXEC_DIR}
#调用hadoop-config.sh加载环境比那里
. $HADOOP_LIBEXEC_DIR/hadoop-config.sh
#调用sbin/slaves.sh脚本 加载配置文件,然后使用hadoop-daemon.sh脚本读取配置文件
exec “$bin/slaves.sh” --config
H
A
D
O
O
P
C
O
N
F
D
I
R
c
d
"
HADOOP_CONF_DIR cd "
HADOOPCONFDIRcd"HADOOP_PREFIX" ; “$bin/hadoop-daemon.sh” --config
H
A
D
O
O
P
C
O
N
F
D
I
R
"
HADOOP_CONF_DIR "
HADOOPCONFDIR"@"
参考hadoop-daemons.sh的使用方法,不难发现直接使用hadoop-daemons.sh脚本,然后配合指令,就可以启动相关守护线程,如:
* [hadoop-daemons.sh](https://bbs.youkuaiyun.com/forums/4f45ff00ff254613a03fab5e56a57acb) start namenode #启动主节点
* [hadoop-daemons.sh](https://bbs.youkuaiyun.com/forums/4f45ff00ff254613a03fab5e56a57acb) start datanode #启动从节点
* [hadoop-daemons.sh](https://bbs.youkuaiyun.com/forums/4f45ff00ff254613a03fab5e56a57acb) start secondarynamenode #启动第二主节点
在这个脚本中,我们可以看到内部执行了slaves.sh脚本读取环境变量,然后再调用了hadoop-daemon.sh脚本读取相关配置信息并执行了hadoop指令。
#### 5、sbin/slaves.sh
Run a shell command on all slave hosts.
Environment Variables
HADOOP_SLAVES File naming remote hosts.
Default is ${HADOOP_CONF_DIR}/slaves.
HADOOP_CONF_DIR Alternate conf dir. Default is ${HADOOP_PREFIX}/conf.
HADOOP_SLAVE_SLEEP Seconds to sleep between spawning remote commands.
HADOOP_SSH_OPTS Options passed to ssh when running remote commands.
使用方法
usage=“Usage: slaves.sh [–config confdir] command…”
if no args specified, show usage
if [ $# -le 0 ]; then
echo $usage
exit 1
fi
bin=dirname "${BASH_SOURCE-$0}"
bin=cd "$bin"; pwd
DEFAULT_LIBEXEC_DIR="
b
i
n
"
/
.
.
/
l
i
b
e
x
e
c
H
A
D
O
O
P
L
I
B
E
X
E
C
D
I
R
=
bin"/../libexec HADOOP_LIBEXEC_DIR=
bin"/../libexecHADOOPLIBEXECDIR={HADOOP_LIBEXEC_DIR:-$DEFAULT_LIBEXEC_DIR}
. $HADOOP_LIBEXEC_DIR/hadoop-config.sh #读取环境变量
if [ -f “
H
A
D
O
O
P
C
O
N
F
D
I
R
/
h
a
d
o
o
p
−
e
n
v
.
s
h
"
]
;
t
h
e
n
.
"
{HADOOP_CONF_DIR}/hadoop-env.sh" ]; then . "
HADOOPCONFDIR/hadoop−env.sh"];then."{HADOOP_CONF_DIR}/hadoop-env.sh” #读取环境变量
fi
Where to start the script, see hadoop-config.sh
(it set up the variables based on command line options)
if [ “
H
A
D
O
O
P
S
L
A
V
E
N
A
M
E
S
"
!
=
′
′
]
;
t
h
e
n
S
L
A
V
E
N
A
M
E
S
=
HADOOP_SLAVE_NAMES" != '' ] ; then SLAVE_NAMES=
HADOOPSLAVENAMES"!=′′];thenSLAVENAMES=HADOOP_SLAVE_NAMES
else
SLAVE_FILE=KaTeX parse error: Expected '}', got 'EOF' at end of input: …HADOOP_SLAVES:-{HADOOP_CONF_DIR}/slaves}
SLAVE_NAMES=
(
c
a
t
"
(cat "
(cat"SLAVE_FILE” | sed ‘s/#.*KaTeX parse error: Expected group after '^' at position 5: //;/^̲/d’)
fi
start the daemons
for slave in $SLAVE_NAMES ; do
ssh $HADOOP_SSH_OPTS $slave
"
"
"{@// /\ }"
2>&1 | sed “s/^/KaTeX parse error: Expected 'EOF', got '&' at position 11: slave: /" &̲ if [ "HADOOP_SLAVE_SLEEP” != “” ]; then
sleep $HADOOP_SLAVE_SLEEP
fi
done
这个脚本也就是加载环境变量,然后通过ssh连接从节点。
#### 6、sbin/hadoop-daemon.sh
#!/usr/bin/env bash
Runs a Hadoop command as a daemon. 以守护进程的形式运行hadoop命令
…
…、
使用方法 command就是hadoop指令,下面有判读
usage=“Usage: hadoop-daemon.sh [–config ] [–hosts hostlistfile] [–script script] (start|stop) <args…>”
…
…
#使用hadoop-config.sh加载环境变量
DEFAULT_LIBEXEC_DIR="
b
i
n
"
/
.
.
/
l
i
b
e
x
e
c
H
A
D
O
O
P
L
I
B
E
X
E
C
D
I
R
=
bin"/../libexec HADOOP_LIBEXEC_DIR=
bin"/../libexecHADOOPLIBEXECDIR={HADOOP_LIBEXEC_DIR:-$DEFAULT_LIBEXEC_DIR}
. $HADOOP_LIBEXEC_DIR/hadoop-config.sh
#使用hadoop-env.sh加载环境变量
if [ -f “
H
A
D
O
O
P
C
O
N
F
D
I
R
/
h
a
d
o
o
p
−
e
n
v
.
s
h
"
]
;
t
h
e
n
.
"
{HADOOP_CONF_DIR}/hadoop-env.sh" ]; then . "
HADOOPCONFDIR/hadoop−env.sh"];then."{HADOOP_CONF_DIR}/hadoop-env.sh”
fi
…
…
case $startStop in
(start)
[ -w "$HADOOP_PID_DIR" ] || mkdir -p "$HADOOP_PID_DIR"
if [ -f $pid ]; then
if kill -0 `cat $pid` > /dev/null 2>&1; then
echo $command running as process `cat $pid`. Stop it first.
exit 1
fi
fi
if [ "$HADOOP_MASTER" != "" ]; then
echo rsync from $HADOOP_MASTER
rsync -a -e ssh --delete --exclude=.svn --exclude='logs/*' --exclude='contrib/hod/logs/*' $HADOOP_MASTER/ "$HADOOP_PREFIX"
fi
hadoop_rotate_log $log
echo starting $command, logging to $log
cd "$HADOOP_PREFIX"
#判断command是什么指令,然后调用bin/hdfs指令 读取配置文件,执行相关指令
case
c
o
m
m
a
n
d
i
n
n
a
m
e
n
o
d
e
∣
s
e
c
o
n
d
a
r
y
n
a
m
e
n
o
d
e
∣
d
a
t
a
n
o
d
e
∣
j
o
u
r
n
a
l
n
o
d
e
∣
d
f
s
∣
d
f
s
a
d
m
i
n
∣
f
s
c
k
∣
b
a
l
a
n
c
e
r
∣
z
k
f
c
)
i
f
[
−
z
"
command in namenode|secondarynamenode|datanode|journalnode|dfs|dfsadmin|fsck|balancer|zkfc) if [ -z "
commandinnamenode∣secondarynamenode∣datanode∣journalnode∣dfs∣dfsadmin∣fsck∣balancer∣zkfc)if[−z"HADOOP_HDFS_HOME" ]; then
hdfsScript=“
H
A
D
O
O
P
P
R
E
F
I
X
"
/
b
i
n
/
h
d
f
s
e
l
s
e
h
d
f
s
S
c
r
i
p
t
=
"
HADOOP_PREFIX"/bin/hdfs else hdfsScript="
HADOOPPREFIX"/bin/hdfselsehdfsScript="HADOOP_HDFS_HOME”/bin/hdfs
fi
nohup nice -n $HADOOP_NICENESS $hdfsScript --config $HADOOP_CONF_DIR
c
o
m
m
a
n
d
"
command "
command"@" > “$log” 2>&1 < /dev/null &
;;
(*)
nohup nice -n $HADOOP_NICENESS $hadoopScript --config $HADOOP_CONF_DIR
c
o
m
m
a
n
d
"
command "
command"@" > “$log” 2>&1 < /dev/null &
;;
esac
…
…
esac
在hadoop-daemon.sh脚本中,同样读取了环境变量,然后依据传入的参数$@(上一个脚本中)来判断要启动的hadoop的守护线程($command),最后调用bin/hdfs指令 读取配置信息 并启动hadoop的守护线程。
#### 7、bin/hdfs
这是一个指令,而非shell脚本。我们可以发现,在启动hadoop集群时,不管使用什么脚本,最终都指向了bin/hdfs这个指令,那么这个指令里到底是什么呢,我们来看一下,就明白了。
bin=which $0
bin=dirname ${bin}
bin=cd "$bin" > /dev/null; pwd
DEFAULT_LIBEXEC_DIR=“$bin”/…/libexec
HADOOP_LIBEXEC_DIR=KaTeX parse error: Expected '}', got 'EOF' at end of input: …P_LIBEXEC_DIR:-DEFAULT_LIBEXEC_DIR}
. $HADOOP_LIBEXEC_DIR/hdfs-config.sh
#除了上面继续加载环境变化外,这个函数其实就是提示我们在使用什么
#比如namenode -format 是格式化DFS filesystem
#再比如 namenode 说的是运行一个DFS namenode
我们往下看
function print_usage(){
echo “Usage: hdfs [–config confdir] [–loglevel loglevel] COMMAND”
echo " where COMMAND is one of:"
echo " dfs run a filesystem command on the file systems supported in Hadoop."
echo " classpath prints the classpath"
echo " namenode -format format the DFS filesystem"
echo " secondarynamenode run the DFS secondary namenode"
echo " namenode run the DFS namenode"
echo " journalnode run the DFS journalnode"
echo " zkfc run the ZK Failover Controller daemon"
echo " datanode run a DFS datanode"
echo " dfsadmin run a DFS admin client"
echo " haadmin run a DFS HA admin client"
echo " fsck run a DFS filesystem checking utility"
echo " balancer run a cluster balancing utility"
echo " jmxget get JMX exported values from NameNode or DataNode."
echo " mover run a utility to move block replicas across"
echo " storage types"
echo " oiv apply the offline fsimage viewer to an fsimage"
echo " oiv_legacy apply the offline fsimage viewer to an legacy fsimage"
echo " oev apply the offline edits viewer to an edits file"
echo " fetchdt fetch a delegation token from the NameNode"
echo " getconf get config values from configuration"
echo " groups get the groups which users belong to"
echo " snapshotDiff diff two snapshots of a directory or diff the"
echo " current directory contents with a snapshot"
echo " lsSnapshottableDir list all snapshottable dirs owned by the current user"
echo " Use -help to see options"
echo " portmap run a portmap service"
echo " nfs3 run an NFS version 3 gateway"
echo " cacheadmin configure the HDFS cache"
echo " crypto configure HDFS encryption zones"
echo " storagepolicies list/get/set block storage policies"
echo " version print the version"
echo “”
echo “Most commands print help when invoked w/o parameters.”
There are also debug commands, but they don’t show up in this listing.
}
if [ $# = 0 ]; then
print_usage
exit
fi
COMMAND=$1
shift
case $COMMAND in
usage flags
–help|-help|-h)
print_usage
exit
;;
esac
Determine if we’re starting a secure datanode, and if so, redefine appropriate variables
if [ “KaTeX parse error: Expected 'EOF', got '&' at position 26: …= "datanode" ] &̲& [ "EUID” -eq 0 ] && [ -n “
H
A
D
O
O
P
S
E
C
U
R
E
D
N
U
S
E
R
"
]
;
t
h
e
n
i
f
[
−
n
"
HADOOP_SECURE_DN_USER" ]; then if [ -n "
HADOOPSECUREDNUSER"];thenif[−n"JSVC_HOME” ]; then
if [ -n "
H
A
D
O
O
P
S
E
C
U
R
E
D
N
P
I
D
D
I
R
"
]
;
t
h
e
n
H
A
D
O
O
P
P
I
D
D
I
R
=
HADOOP_SECURE_DN_PID_DIR" ]; then HADOOP_PID_DIR=
HADOOPSECUREDNPIDDIR"];thenHADOOPPIDDIR=HADOOP_SECURE_DN_PID_DIR
fi
if [ -n "$HADOOP_SECURE_DN_LOG_DIR" ]; then
HADOOP_LOG_DIR=$HADOOP_SECURE_DN_LOG_DIR
HADOOP_OPTS="$HADOOP_OPTS -Dhadoop.log.dir=$HADOOP_LOG_DIR"
fi
HADOOP_IDENT_STRING=$HADOOP_SECURE_DN_USER
HADOOP_OPTS="$HADOOP_OPTS -Dhadoop.id.str=$HADOOP_IDENT_STRING"
starting_secure_dn="true"
else
echo “It looks like you’re trying to start a secure DN, but $JSVC_HOME”
“isn’t set. Falling back to starting insecure DN.”
fi
fi
Determine if we’re starting a privileged NFS daemon, and if so, redefine appropriate variables
if [ “KaTeX parse error: Expected 'EOF', got '&' at position 22: …D" == "nfs3" ] &̲& [ "EUID” -eq 0 ] && [ -n “
H
A
D
O
O
P
P
R
I
V
I
L
E
G
E
D
N
F
S
U
S
E
R
"
]
;
t
h
e
n
i
f
[
−
n
"
HADOOP_PRIVILEGED_NFS_USER" ]; then if [ -n "
HADOOPPRIVILEGEDNFSUSER"];thenif[−n"JSVC_HOME” ]; then
if [ -n "
H
A
D
O
O
P
P
R
I
V
I
L
E
G
E
D
N
F
S
P
I
D
D
I
R
"
]
;
t
h
e
n
H
A
D
O
O
P
P
I
D
D
I
R
=
HADOOP_PRIVILEGED_NFS_PID_DIR" ]; then HADOOP_PID_DIR=
HADOOPPRIVILEGEDNFSPIDDIR"];thenHADOOPPIDDIR=HADOOP_PRIVILEGED_NFS_PID_DIR
fi
if [ -n "$HADOOP_PRIVILEGED_NFS_LOG_DIR" ]; then
HADOOP_LOG_DIR=$HADOOP_PRIVILEGED_NFS_LOG_DIR
HADOOP_OPTS="$HADOOP_OPTS -Dhadoop.log.dir=$HADOOP_LOG_DIR"
fi
HADOOP_IDENT_STRING=$HADOOP_PRIVILEGED_NFS_USER
HADOOP_OPTS="$HADOOP_OPTS -Dhadoop.id.str=$HADOOP_IDENT_STRING"
starting_privileged_nfs="true"
else
echo “It looks like you’re trying to start a privileged NFS server, but”
“$JSVC_HOME isn’t set. Falling back to starting unprivileged NFS server.”
fi
fi
停停停,对就是这
我们可以看到,通过相应的hadoop指令,在加载相应的class文件
然后在jvm运行此程序。别忘记了,hadoop是用java语言开发的
if [ “KaTeX parse error: Expected 'EOF', got '#' at position 93: …e.NameNode' #̲namenode守护线程对应的…HADOOP_OPTS
H
A
D
O
O
P
N
A
M
E
N
O
D
E
O
P
T
S
"
e
l
i
f
[
"
HADOOP_NAMENODE_OPTS" elif [ "
HADOOPNAMENODEOPTS"elif["COMMAND” = “zkfc” ] ; then
CLASS=‘org.apache.hadoop.hdfs.tools.DFSZKFailoverController’
HADOOP_OPTS=“$HADOOP_OPTS
H
A
D
O
O
P
Z
K
F
C
O
P
T
S
"
e
l
i
f
[
"
HADOOP_ZKFC_OPTS" elif [ "
HADOOPZKFCOPTS"elif["COMMAND” = “secondarynamenode” ] ; then
CLASS=‘org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode’ #SecondaryNameNode守护线程对应的CLASS字节码
HADOOP_OPTS=“$HADOOP_OPTS
H
A
D
O
O
P
S
E
C
O
N
D
A
R
Y
N
A
M
E
N
O
D
E
O
P
T
S
"
e
l
i
f
[
"
HADOOP_SECONDARYNAMENODE_OPTS" elif [ "
HADOOPSECONDARYNAMENODEOPTS"elif["COMMAND” = “datanode” ] ; then
CLASS=‘org.apache.hadoop.hdfs.server.datanode.DataNode’ #DataNode守护线程对应的CLASS字节码
if [ “
s
t
a
r
t
i
n
g
s
e
c
u
r
e
d
n
"
=
"
t
r
u
e
"
]
;
t
h
e
n
H
A
D
O
O
P
O
P
T
S
=
"
starting_secure_dn" = "true" ]; then HADOOP_OPTS="
startingsecuredn"="true"];thenHADOOPOPTS="HADOOP_OPTS -jvm server
H
A
D
O
O
P
D
A
T
A
N
O
D
E
O
P
T
S
"
e
l
s
e
H
A
D
O
O
P
O
P
T
S
=
"
HADOOP_DATANODE_OPTS" else HADOOP_OPTS="
HADOOPDATANODEOPTS"elseHADOOPOPTS="HADOOP_OPTS -server
H
A
D
O
O
P
D
A
T
A
N
O
D
E
O
P
T
S
"
f
i
e
l
i
f
[
"
HADOOP_DATANODE_OPTS" fi elif [ "
HADOOPDATANODEOPTS"fielif["COMMAND” = “journalnode” ] ; then
CLASS=‘org.apache.hadoop.hdfs.qjournal.server.JournalNode’
HADOOP_OPTS=“$HADOOP_OPTS $HADOOP_JOURNALNODE_OPTS”
…
…省略很多…
…
Check to see if we should start a secure datanode
if [ “
s
t
a
r
t
i
n
g
s
e
c
u
r
e
d
n
"
=
"
t
r
u
e
"
]
;
t
h
e
n
i
f
[
"
starting_secure_dn" = "true" ]; then if [ "
startingsecuredn"="true"];thenif["HADOOP_PID_DIR” = “” ]; then
HADOOP_SECURE_DN_PID=“/tmp/hadoop_secure_dn.pid”
else
HADOOP_SECURE_DN_PID=“$HADOOP_PID_DIR/hadoop_secure_dn.pid”
fi
JSVC=$JSVC_HOME/jsvc
if [ ! -f $JSVC ]; then
echo "JSVC_HOME is not set correctly so jsvc cannot be found. jsvc is required to run secure datanodes. "
echo "Please download and install jsvc from http://archive.apache.org/dist/commons/daemon/binaries/ "
“and set JSVC_HOME to the directory containing the jsvc binary.”
exit
fi
if [[ !
J
S
V
C
O
U
T
F
I
L
E
]
]
;
t
h
e
n
J
S
V
C
O
U
T
F
I
L
E
=
"
JSVC_OUTFILE ]]; then JSVC_OUTFILE="
JSVCOUTFILE]];thenJSVCOUTFILE="HADOOP_LOG_DIR/jsvc.out"
fi
if [[ !
J
S
V
C
E
R
R
F
I
L
E
]
]
;
t
h
e
n
J
S
V
C
E
R
R
F
I
L
E
=
"
JSVC_ERRFILE ]]; then JSVC_ERRFILE="
JSVCERRFILE]];thenJSVCERRFILE="HADOOP_LOG_DIR/jsvc.err"
fi
#运行 java字节码文件
exec “KaTeX parse error: Expected group after '_' at position 26: … -Dproc_̲COMMAND -outfile “
J
S
V
C
O
U
T
F
I
L
E
"
−
e
r
r
f
i
l
e
"
JSVC_OUTFILE" \ -errfile "
JSVCOUTFILE" −errfile"JSVC_ERRFILE”
-pidfile “
H
A
D
O
O
P
S
E
C
U
R
E
D
N
P
I
D
"
−
n
o
d
e
t
a
c
h
−
u
s
e
r
"
HADOOP_SECURE_DN_PID" \ -nodetach \ -user "
HADOOPSECUREDNPID" −nodetach −user"HADOOP_SECURE_DN_USER”
-cp “$CLASSPATH”
$JAVA_HEAP_MAX
H
A
D
O
O
P
O
P
T
S
o
r
g
.
a
p
a
c
h
e
.
h
a
d
o
o
p
.
h
d
f
s
.
s
e
r
v
e
r
.
d
a
t
a
n
o
d
e
.
S
e
c
u
r
e
D
a
t
a
N
o
d
e
S
t
a
r
t
e
r
"
HADOOP_OPTS \ org.apache.hadoop.hdfs.server.datanode.SecureDataNodeStarter "
HADOOPOPTS org.apache.hadoop.hdfs.server.datanode.SecureDataNodeStarter"@”
elif [ “
s
t
a
r
t
i
n
g
p
r
i
v
i
l
e
g
e
d
n
f
s
"
=
"
t
r
u
e
"
]
;
t
h
e
n
i
f
[
"
starting_privileged_nfs" = "true" ] ; then if [ "
startingprivilegednfs"="true"];thenif["HADOOP_PID_DIR” = “” ]; then
HADOOP_PRIVILEGED_NFS_PID=“/tmp/hadoop_privileged_nfs3.pid”
else
HADOOP_PRIVILEGED_NFS_PID=“$HADOOP_PID_DIR/hadoop_privileged_nfs3.pid”
fi
JSVC=$JSVC_HOME/jsvc
if [ ! -f $JSVC ]; then
echo "JSVC_HOME is not set correctly so jsvc cannot be found. jsvc is required to run privileged NFS gateways. "
echo "Please download and install jsvc from http://archive.apache.org/dist/commons/daemon/binaries/ "
“and set JSVC_HOME to the directory containing the jsvc binary.”
exit
fi
if [[ !
J
S
V
C
O
U
T
F
I
L
E
]
]
;
t
h
e
n
J
S
V
C
O
U
T
F
I
L
E
=
"
JSVC_OUTFILE ]]; then JSVC_OUTFILE="
JSVCOUTFILE]];thenJSVCOUTFILE="HADOOP_LOG_DIR/nfs3_jsvc.out"
fi
if [[ !
J
S
V
C
E
R
R
F
I
L
E
]
]
;
t
h
e
n
J
S
V
C
E
R
R
F
I
L
E
=
"
JSVC_ERRFILE ]]; then JSVC_ERRFILE="
JSVCERRFILE]];thenJSVCERRFILE="HADOOP_LOG_DIR/nfs3_jsvc.err"
fi
#运行 java字节码文件
exec “KaTeX parse error: Expected group after '_' at position 26: … -Dproc_̲COMMAND -outfile “
J
S
V
C
O
U
T
F
I
L
E
"
−
e
r
r
f
i
l
e
"
JSVC_OUTFILE" \ -errfile "
JSVCOUTFILE" −errfile"JSVC_ERRFILE”
-pidfile “
H
A
D
O
O
P
P
R
I
V
I
L
E
G
E
D
N
F
S
P
I
D
"
−
n
o
d
e
t
a
c
h
−
u
s
e
r
"
HADOOP_PRIVILEGED_NFS_PID" \ -nodetach \ -user "
HADOOPPRIVILEGEDNFSPID" −nodetach −user"HADOOP_PRIVILEGED_NFS_USER”
-cp “$CLASSPATH”
$JAVA_HEAP_MAX
H
A
D
O
O
P
O
P
T
S
o
r
g
.
a
p
a
c
h
e
.
h
a
d
o
o
p
.
h
d
f
s
.
n
f
s
.
n
f
s
3.
P
r
i
v
i
l
e
g
e
d
N
f
s
G
a
t
e
w
a
y
S
t
a
r
t
e
r
"
HADOOP_OPTS \ org.apache.hadoop.hdfs.nfs.nfs3.PrivilegedNfsGatewayStarter "
HADOOPOPTS org.apache.hadoop.hdfs.nfs.nfs3.PrivilegedNfsGatewayStarter"@”
else
#运行 java字节码文件
run it
exec “KaTeX parse error: Expected group after '_' at position 13: JAVA" -Dproc_̲COMMAND $JAVA_HEAP_MAX $HADOOP_OPTS
C
L
A
S
S
"
CLASS "
CLASS"@”
fi
看完懂了吗?在这个指令中,加载了各个守护线程对应的CLASS字节码文件,然后在JVM上来运行相应的守护线程。
hadoop的另一个指令bin/hadoop,内部也调用了bin/hdfs指令,感兴趣的话,可以自己看看,我就不展示出来了。至于跟yarn有关的脚本和指令也是相同的逻辑关系,我也不一一展示了。
## 学习路线:
这个方向初期比较容易入门一些,掌握一些基本技术,拿起各种现成的工具就可以开黑了。不过,要想从脚本小子变成黑客大神,这个方向越往后,需要学习和掌握的东西就会越来越多以下是网络渗透需要学习的内容:
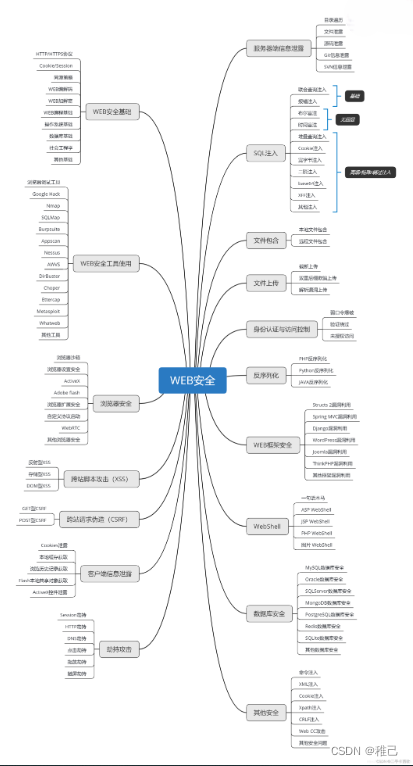
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以点击这里获取](https://bbs.youkuaiyun.com/forums/4f45ff00ff254613a03fab5e56a57acb)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**

















 5532
5532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









