







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新软件测试全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注软件测试)

正文
output
城市:XX市
小区:四季家园二区
pandas#
- 提取城市名称,由于城市名称的字数相同,可以直接切片截取前三个。
df[“城市”] = df[“地址”].str[:3]
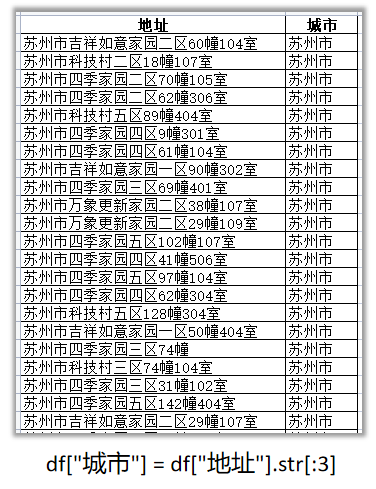
提取城市
- 提取小区名,稍有点复杂。因为小区名称长度是不一样长的。可以利用字符串处理的天花板:
正则表达式。详细处理方法,见下文五、正则表达式示例1。
点我免费领取全套软件测试(自动化测试)视频资料(备注“csdn000”)视频资料(备注“csdn000”)")
四、补齐数
有时候,我们在电脑中按文件名排序的时候,你可能会遇到下面的情况:
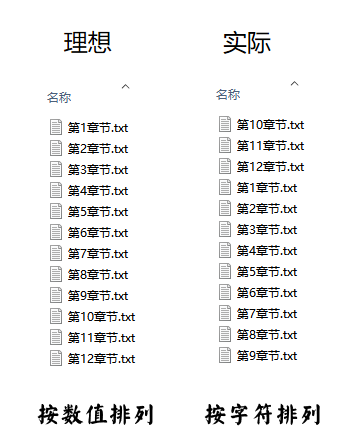
数值排序和字符排序
在不同系统中,我们希望是按数值排序,但偏偏系统却是按字符排序的,如某些车载播放器中。比较好的解决方法就是在前面添加0,补齐数据位数。数据量大的时候,手动修改很麻烦,Python字符串处理的zfill()函数就可以解决这个问题。
Pytho
myStr = “1章节”
print(myStr.zfill(4)) # 整个字符串补齐到4位
output
01章节
pandas#
df[“新文件名”] = “第”+df[“文件名”].str[1:].str.zfill(8)

image-20220330005403437
配合os.rename()便可以批量重命名。关键代码如下
df.apply(lambda x: os.rename( path + x[“文件名”], path + x[“新文件名”]), axis=1)
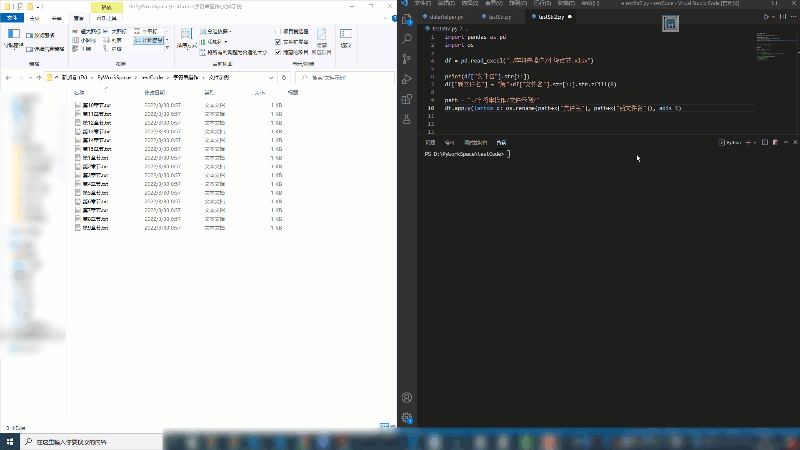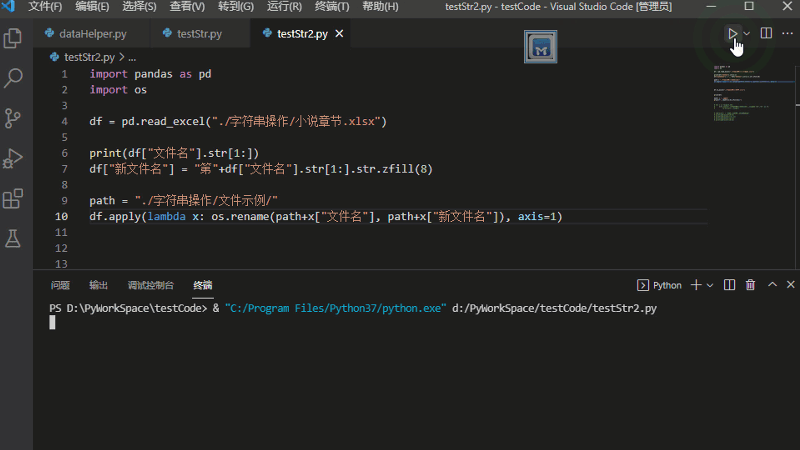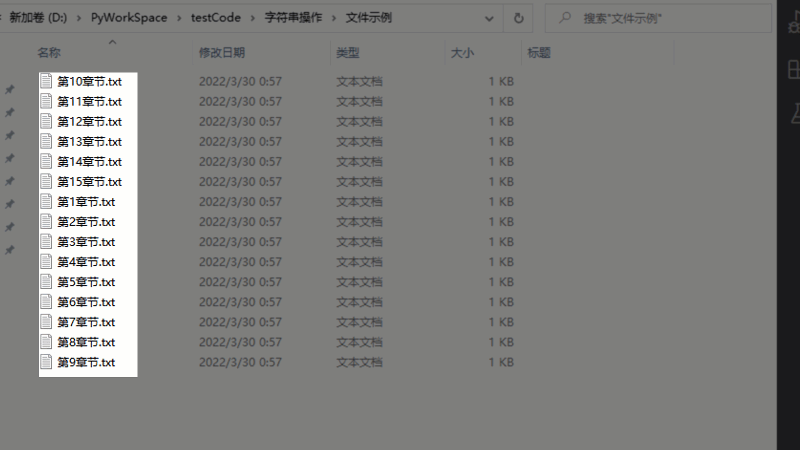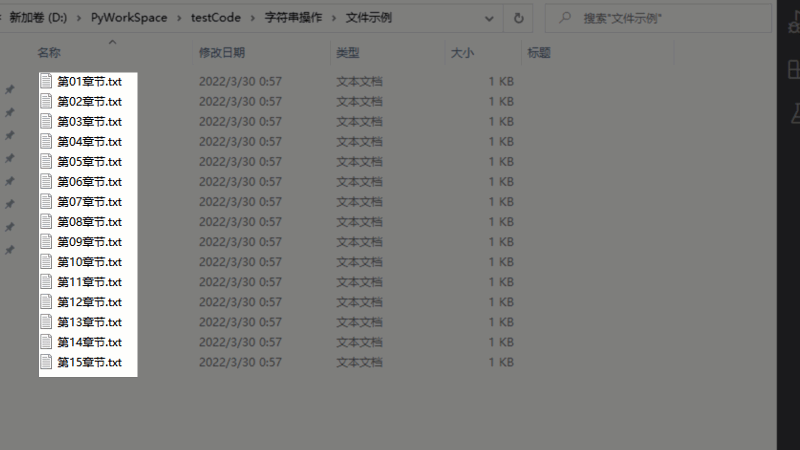
批量重命名演示
五、正则表达式
遇到复杂的字符串处理需求时,Python有优势就可以体现出来了。因为python和pandas有一个超强的字符串处理武器:正则表达式。正则表达式可以匹配字符串的格式特点,如电子邮箱的地址格式、网址的地址格式、电话号码格式等。如何写好正则表达式,这是一门精深的学问,本文介绍几个正则表达式的常用案例,浅尝辄止。
注:Python默认不支持正则表达式语法,而pandas直接支持正则表达式语法,这里重点介绍pandas处理表格数据。
1.提取长度不一样的小区名
思路:
- 提取上面小区名,可以归纳一下地址中小区名的格式特点:
苏州市之后,幢号数字之前的中文字符。 Series的str.extract(),可用正则从字符数据中抽取匹配的数据;
## 匹配中文字符的正则表达式: [\u4e00-\u9fa5]
pattern = r’苏州市([\u4e00-\u9fa5]+)[0-9]+幢’
df[“小区”] = df[“地址”].str.extract(pattern, expand=False)
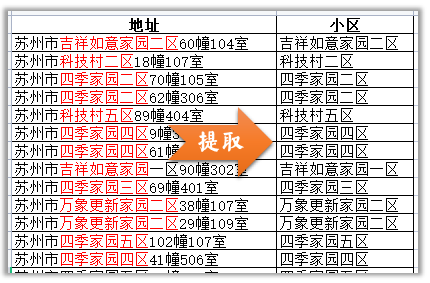
提取小区名
2.提取几幢几室
思路:几幢几室,格式都是数字+幢和数字+室
- 数字可以用
[0-9]或\d来匹配; +表示1个或多个。
pattern = r’([0-9]+)幢’
df[“幢号”] = df[“地址”].str.extract(pattern, expand=False)
pattern = r’(\d+)室’
df[“室号”] = df[“地址”].str.extract(pattern, expand=False)
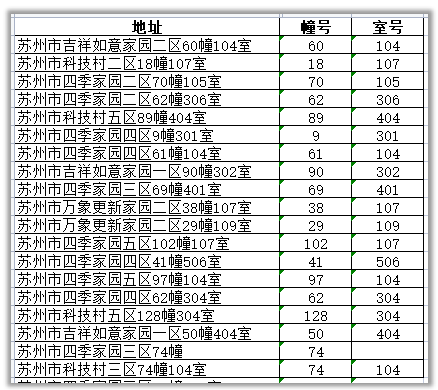
提取幢号室号
六、apply函数
apply 函数:可以对DateFrame进行逐行或逐列进行处理。
1.增加一列,将幢号按照奇偶数分类
将幢号为奇数的为A区,偶数的为B区
# 定义处理的函数,共apply函数调用,传入的参数为一个Series对象
def my_func(series):
if (series[“幢号”]) % 2 != 0:
return “A区”
else:
return “B区”
df[“幢号分类”] = df.apply(my_func, axis=1)
上述代码中apply函数,有两个参数
- 第一个参数:处理逻辑的函数名。主要传入名称,这里为
my_func; - 第二个参数:
axis = 1,表示按列处理。即传入的是每一行的Series。
output
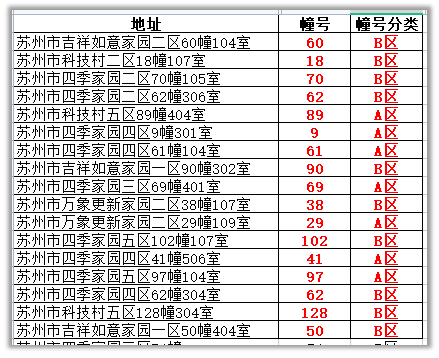
apply映射分类
2.增加一列,字典映射
def my_func2(series):
# 映射字典,key为小区名,value为小区称号
my_dict = {
‘吉祥如意家园’: ‘最佳好运小区’,
‘科技村’: ‘最佳科创小区’,
‘四季家园’: ‘最佳风光小区’,
‘万象更新家园’: ‘最佳风采小区’,
}
# 每一行小区名称,切片截取至倒数第2个,即-2
nameKey = series[‘小区’][:-2]
return my_dict[nameKey]
df[“小区称号”] = df.apply(my_func2, axis=1)
output

apply匹配映射
结语
本文演示的字符串操作:替换、分列、切片截取、补齐数据、正则表达式、apply()函数常见于数据分析的数据清洗环节,替换、分列、切片截取在Excel中也很容易实现,正则表达式可以说是Python处理复杂字符串问题的一大利器,apply()函数可以实现自定义函数处理表格型的数据,十分灵活、威力巨大。由于篇幅有限,正则表达式、apply()函数本文就点到为止,今后值得整理更多相关案例。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注软件测试)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注软件测试)
[外链图片转存中…(img-omxmF9xj-1713464211881)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









