






首先把 LGBMClassifier 换成CatBoostClassifier模型,通过修改模型参数,在一定程度上可以提高精度,但是比较吃电脑配置,而且精度提高不大,其次,将几种模型融合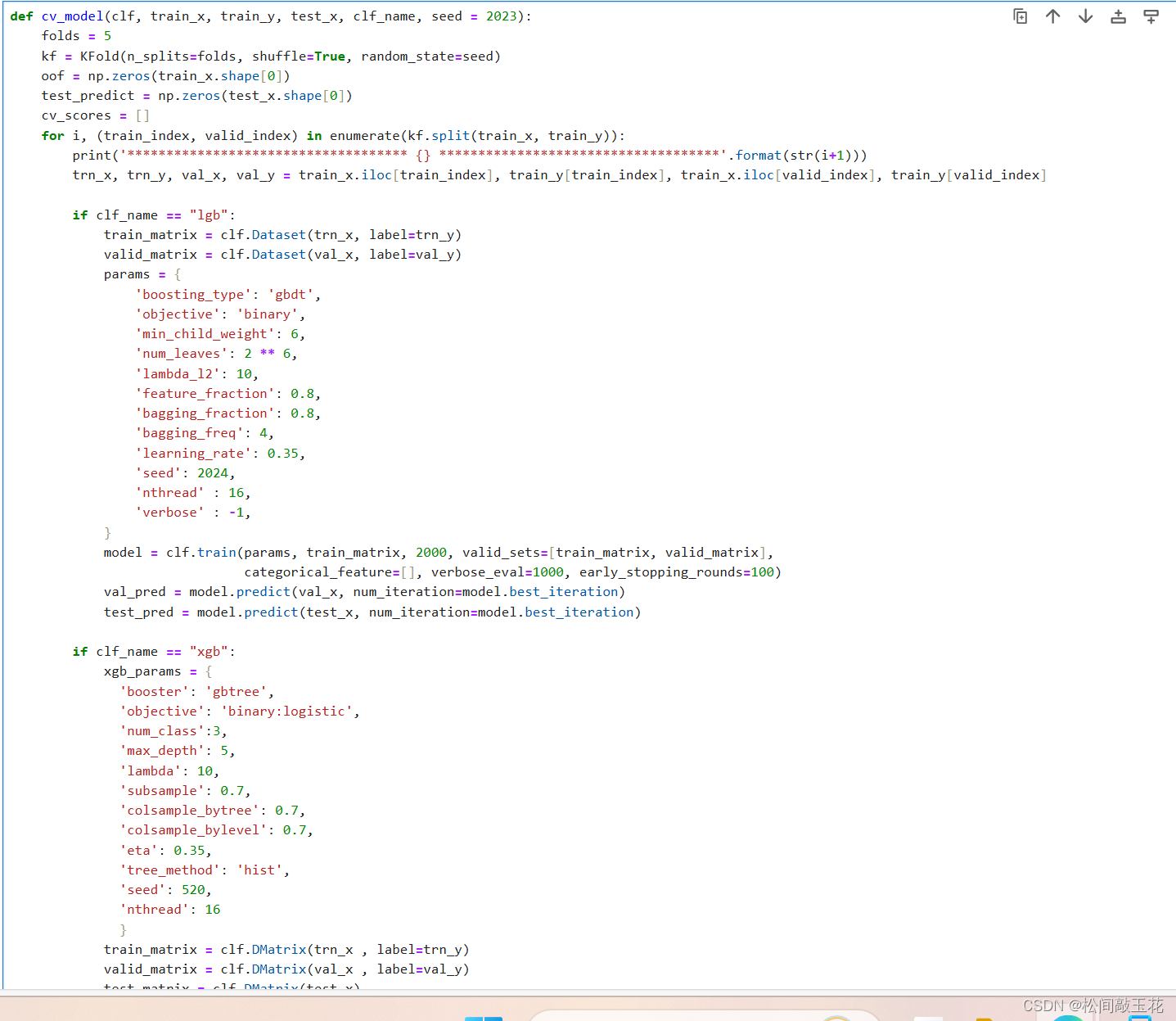
用于交叉验证并训练多个机器学习模型(LightGBM、XGBoost、CatBoost)的函数,最后进行模型融合的过程,并且还包括一些数据处理和保存结果的部分。
1. 首先定义了一个名为cv_model的函数,用于交叉验证和训练不同的机器学习模型。
2. 函数参数包括要使用的分类器(clf)、训练数据(train_x、train_y)、测试数据(test_x)、分类器名称(clf_name)以及随机种子(seed)等。
3. 在函数中,使用KFold进行五折交叉验证,将训练数据分成训练集和验证集。
4. 根据传入的分类器名称,分别对LightGBM、XGBoost和CatBoost进行模型训练和预测。
5. 对于每个模型,使用相应的参数进行训练,并获取在验证集上的预测结果和在测试集上的预测结果。
6. 将每个模型在验证集上的预测结果加权平均得到最终的oof(out of fold)预测结果,将每个模型在测试集上的预测结果加权平均得到最终的测试集预测结果。
7. 最后,计算每个模型的F1分数,并将F1分数存储在cv_scores列表中,并返回oof和测试集预测结果。
8. 在代码的后面部分,通过调用cv_model函数分别使用LightGBM、XGBoost和CatBoost进行交叉验证和训练。
9. 最后,将三个模型的测试集预测结果进行简单的平均融合,得到最终的预测结果final_test。
10. 在接下来的代码中,包括了数据处理的部分和用LightGBM模型进行训练、预测并保存结果的部分。
在接下来的代码中:
- 通过导入相关库,如pandas和numpy,以及从lightgbm模块中导入LGBMClassifier类。
- 读取训练集和测试集数据,其中训练集数据来自名为'traindata-new.xlsx'的文件,测试集数据来自名为'testdata-new.xlsx'的文件。
- 进行特征工程,删除了训练集中的'DC50 (nM)'和'Dmax (%)'两列数据,并对object类型的数据进行了简单处理。
- 加载LGBMClassifier模型,进行了训练,并对测试集进行预测。
最后,将预测结果保存为submit.csv文件,包括'test'中的'uuid'列和预测的'Label'列,并保存到本地。
当然可以根据自己的选择去更自主的融合三种模型


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









