






说明,我公司项目的需求:1、通过在线Markdown编辑器写文章,将文章显示到浏览器2、 再将在线文章下载到本地保留基本样式。因为有如上需求,所以就有了上图的流程。如果你的需求跟我不一样,我也希望本篇文章能给你一些参考。
2.2、使用到的核心框架
(1)前端
marked.js
editormd.js
vue.css (这个样式文档是我从typora软件中获取的,网上直接找不到)
(2)Java
itextpdf
springboot
jsoup
上述前端框架在文档末尾会附上下载链接
2.3、Markdown转HTML
此过程更多的是前端框架完成,使用的是editormd.js (文末附上地址)。相对比较简单,我就不进行代码展示了(毕竟我们的核心是转PDF),给大家看看效果图:
2.3.1、编辑Markdown前端代码
1、初始化Markdown在线编辑器
- HTML代码
<html>
<head>
<link rel="stylesheet" href="css/editormd.css"/>
<script src="js/editormd.js"></script>
</head>
<body>
<div id="test-editormd">
<textarea style="display:none;"></textarea>
</div>
</body>
</html>
- Javascript代码
**var** testEditor = editormd("test-editormd", { width: "100%", height: "75%", markdown : "" , htmlDecode : "style,script,iframe", // you can filter tags decode emoji : true, taskList : true, tex : true, // 默认不解析 flowChart : true, // 默认不解析 sequenceDiagram : true, // 默认不解析 });
上述代码就是初始化Markdown在线编辑器的代码了,一会将Markdown格式的文档转换成HTML需要用到这个editormd,所以先初始化。
上述是Markdown的编辑状态,显示纯阅览模式的代码如下。
2.3.2 纯预览状态(此状态也就是Markdown转HTML的状态)
- HTML代码
<html>
<head>
<link rel="stylesheet" href="css/editormd.css"/>
<link rel="stylesheet" href="css/vue.css"/>
<script src="js/editormd.js"></script>
</head>
<body>
<div id="test-editormd">
<textarea style="display:none;"></textarea>
</div>
</body>
</html>
- JavaScript代码
**var** testEditormdView = editormd.markdownToHTML("test-editormd", {
gfm:**true**,
breaks:**true**,
markdown : data , //此处的data就是Markdown格式的字符串
htmlDecode : "style,script,iframe", // you can filter tags decode
tocDropdown : **true**,
tocTitle : "目录 Table of Contents",
emoji : **true**,
taskList : **true**,
tex : **true**, // 默认不解析
flowChart : **true**, // 默认不解析
sequenceDiagram : **true**, // 默认不解析
});
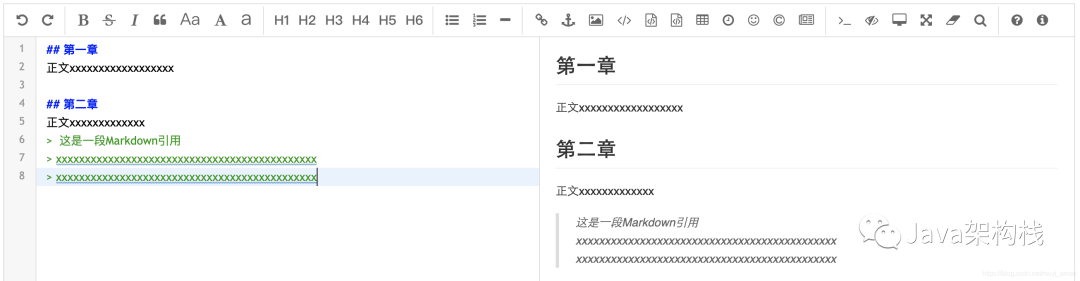
- 上述data变量的内容如下:
- 效果图如下:
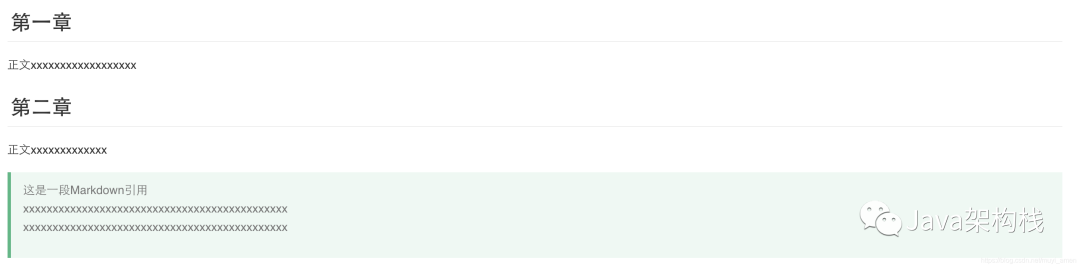
上图,因为我引用了vue.css,所以展示如typora中的Vue风格的样式。
- 获取上述HTML的源码
**var** mdHtmlContent =testEditormdView[0].innerHTML; //获取到了源码
mdHtmlContent的内容如下:
<h2 id = "h2-u7B2Cu4E00u7AE0" >
< a name = "第一章" class= "reference-link" ></a>
<span class="header-link octicon octicon-link"></span>
第一章
</h2>
<p > 正文xxxxxxxxxxxxxxxxxx </p>
<h2 id = "h2-u7B2Cu4E8Cu7AE0" >
<a name = "第二章" class= "reference-link" > </a>
<span class="header-link octicon octicon-link">
</span > 第二章 < /h2>
<p> 正文xxxxxxxxxxxxx </p>
<blockquote>
<p> 这是一段Markdown引用 < br > xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx <br> xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx </p>
</blockquote>
上述由Markdown转换成HTML的源码,大家会发现一个问题:没有html、head、body标签。这个需要手动拼接一下。为什么要手动拼接,此处重点解释,否则后面BUG成堆:
1、因为我们获取的是Markdown转HTML后的源码,而不是整个网页的源码。其实,想获取整个网页的源码也是非常简单,但是建议不要获取整个网页的源码。因为整个网页可能有很多js代码、或者注释、或者莫名其妙多出来的东西;这些都会导致一会转pdf时发现异常。为了减少这样的BUG,最好只获取Markdown转成HTML部分的源码。
2、纯净的HTML源文件,有利于我们后面转PDF时指定PDF需要的css样式。
3、保持纯净,有利于BUG的调试。
至此,我们完成了Markdown转换成HTML的过程。效果图:
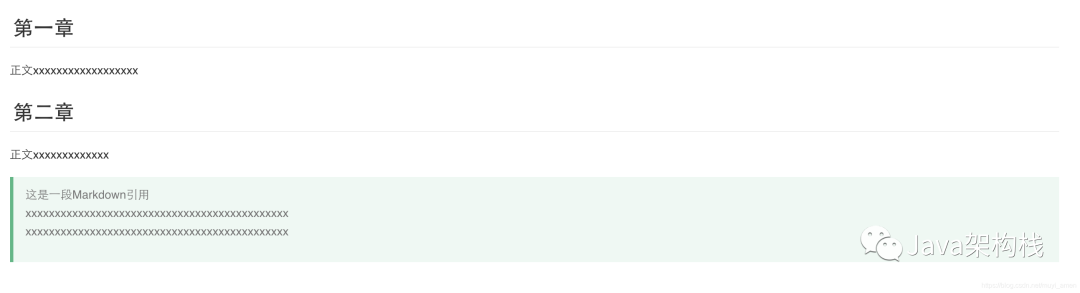
2.4、HTML转PDF
HTML转PDF用到的是jsoup和itextpdf框架。主要是在Java后端完成。流程图如下:
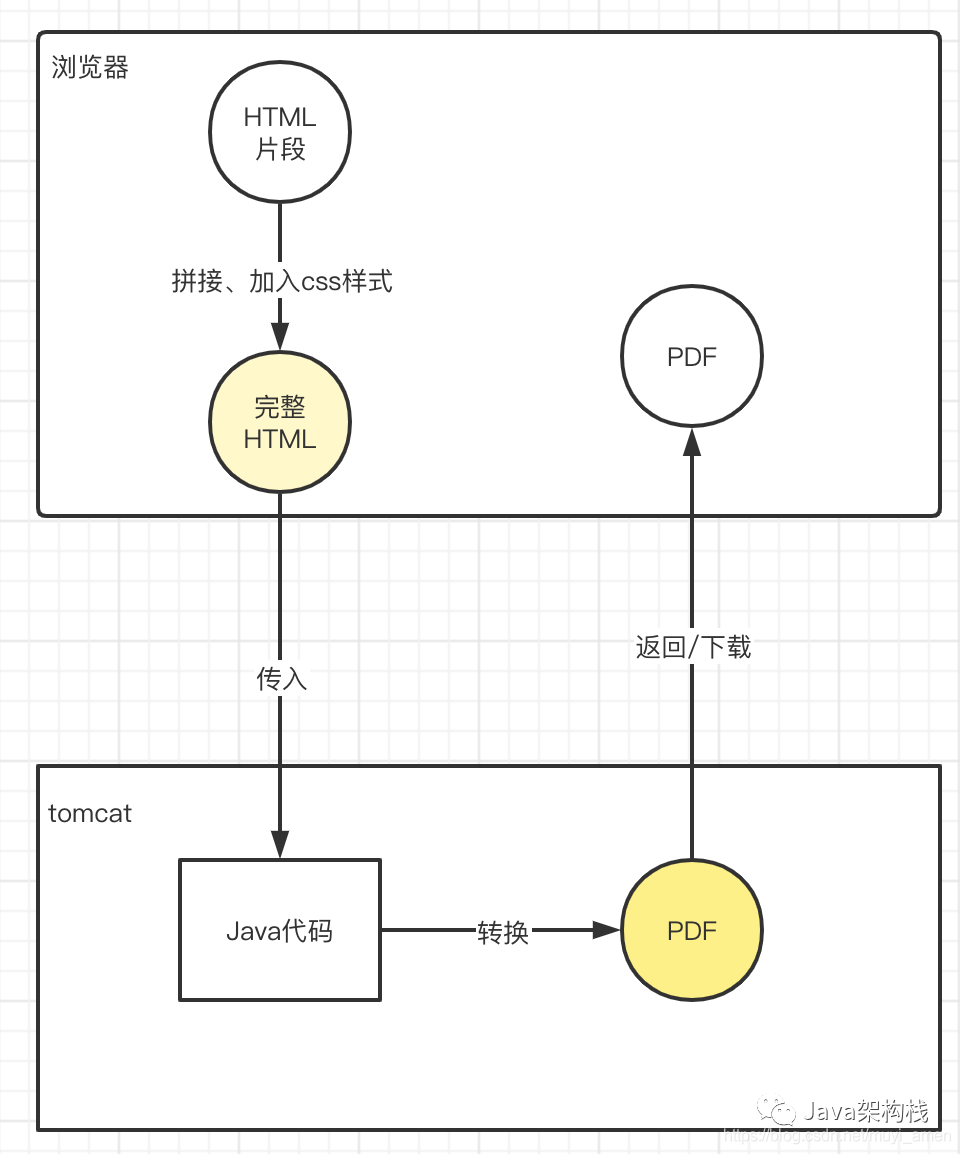
如上图,有两个过程需要处理,才能转换成完整样式的PDF:
1、将2.3节获取到的非完整HTML编程完整HTML,此过程较简单,就是字符串拼接就行。
2、后台Java代码完成PDF转换,此过程解决中文不显示、样式等问题。
2.4.1、拼接完整HTML,并设置CSS样式
此处一定要设置CSS样式,以便导出的PDF的样式更好看。此处CSS样式的指定,将会解决一个问题:
- 图片超宽问题
**var** htmlContent = `<!DOCTYPE html>
<html lang="zh">
<head><meta charset="utf-8" /></head>
<style type="text/css">
body{
width: 100%;
}
body > *:first-child {
margin-top: 0 !important;
}
body > *:last-child {
margin-bottom: 0 !important;
}
a {
color: #42b983;
/*font-weight: 600;*/
padding: 0 2px;
text-decoration: none;
}
h1,
h2,
h3,
h4,
h5,
h6 {
position: relative;
margin-top: 15px;
margin-bottom: 10px;
font-weight: bold;
line-height: 1.4;
cursor: text;
}
h1:hover a.anchor,
h2:hover a.anchor,
h3:hover a.anchor,
h4:hover a.anchor,
h5:hover a.anchor,
h6:hover a.anchor {
text-decoration: none;
}
h1 tt,
h1 code {
font-size: inherit !important;
}
h2 tt,
h2 code {
font-size: inherit !important;
}
h3 tt,
h3 code {
font-size: inherit !important;
}
h4 tt,
h4 code {
font-size: inherit !important;
}
h5 tt,
h5 code {
font-size: inherit !important;
}
h6 tt,
h6 code {
font-size: inherit !important;
}
h2 a,
h3 a {
color: #34495e;
}
h1 {
padding-bottom: .4rem;
font-size: 30px;
line-height: 1.3;
}
h2 {
font-size: 26px;
line-height: 1.225;
margin: 35px 0 15px;
padding-bottom: 0.5em;
border-bottom: 1px solid #ddd;
}
h3 {
font-size: 22px;
line-height: 1.43;
margin: 20px 0 7px;
}
h4 {
font-size: 20px;
}
h5 {
font-size: 18px;
}
h6 {
font-size: 16px;
color: #555;
}
p
blockquote,
ul,
li,
ol,
dl,
table {
margin: 10px 0px;
}
.quote{
border-left: 4px solid #42b983;
color: #888;
background-color: rgba(66, 185, 131, .2);
margin-top: 15px;
padding: 10px;
}
.on-focus-mode blockquote {
border-left-color: rgba(85, 85, 85, 0.12);
}
//此处指定table最大宽度,用来解决超宽问题
table,
td,
tr,
img,
th {
width: 100%;
}
</style>
<body style="font-size:12.0pt; font-family:SimHei">`+ mdHtmlContent +`</body>
</html>`
拼接过程的具体的代码如下:
(1)重点:解决中文不显示的问题
上述css中有如下图这样一个配置,非常重要。用来解决中文不显示的问题。

详细说明:
a、font-family中指定的SimHei是黑体字体。只能写英文。中文无效
b、下面的java代码中,会导入SimHei的字体包。同时满足上述条件,才能正常显示中文
(2)上述css样式指定了img、table的最大宽度为100%,就可以解决超宽问题。
效果如下:我的需求是在table中有一张图片,因为图片过大导致table超宽,效果图如下:
如上,图片由一大半没有正常显示,越界了。设置img和table最大宽度之后,就正常了,效果如下:

2.4.2、通过form表达,将上述htmlContent传入后台
伪代码如下(怎么传都行,我下面只是给出一个范例伪代码):
<form id=“form1” action="/pdf" method="get">
<input id="html" type="hidden" value=""/>
</form>
<script>
//js代码
$("#html").val(htmlContent); //此处的htmlContent就是2.4.1拼接之后的完整的HTML。
$("#form1").submit();
</script>
说明:此处是form表单请求。不能使用ajax,因为是要完成下载或者预览,后台返回的是文件流。
2.4.3、Java代码将html转成pdf。
- 后台接收浏览器传入的HTML,PdfController类
//html:传入的html源文件
//filename:文件名称,可以自定义,仅仅用来显示下载过程中的文件名称。
//resp,Servlet响应,给前端返回的文件流就靠此类完成了。
@RequestMapping("/pdf/{filename}")
**public** **void** **htmlToPdf**(String html, @PathVariable("filename") String filename,HttpServletResponse resp) **throws** IOException {
//TODO,这里就要开始进行HTML转PDF了。分成两步执行:
//1、解决HTML标签没有关闭,导致的转换异常
//2、转换PDF
}
接收到前端传递过来的HTML之后,就要进行PDF转换了,分成两步完成:
1、解决HTML标签没有关闭,导致的转换异常
2、转换PDF
2.4.4、解决HTML标签没有关闭的异常
解决此问题用到了jsoup,所以需要导包。
- 导包
<dependency>
<groupId>org.j
**作者徽是vip1024c**
soup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>
如果HTML标签没有闭合,则会出现异常。比如< p></ p>·这属于闭合标签,< link rel=“” href=“”>这属于没有闭合标签。在网上上类似这样没有闭合的标签还有很多,没有闭合的标签就会导致如下错误:
com.itextpdf.tool.xml.exceptions.RuntimeWorkerException: Invalid nested tag p found, expected closing tag img.
at com.itextpdf.tool.xml.XMLWorker.endElement(XMLWorker.java:134)
at com.itextpdf.tool.xml.parser.XMLParser.endElement(XMLParser.java:396)
at com.itextpdf.tool.xml.parser.state.ClosingTagState.process(ClosingTagState.java:70)
at com.itextpdf.tool.xml.parser.XMLParser.parseWithReader(XMLParser.java:236)
at com.itextpdf.tool.xml.parser.XMLParser.parse(XMLParser.java:214)
at com.itextpdf.tool.xml.parser.XMLParser.parse(XMLParser.java:203)
at com.itextpdf.tool.xml.XMLWorkerHelper.parseXHtml(XMLWorkerHelper.java:236)
at com.itextpdf.tool.xml.XMLWorkerHelper.parseXHtml(XMLWorkerHelper.java:210)
at com.lhjz.portal.pdf.PDFUtil.htmlToPdf(PDFUtil.java:57)
at com.lhjz.portal.controller.HomeController.htmlToPdf(HomeController.java:579)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.springframework.web.method.support.InvocableHandlerMethod.doInvoke(InvocableHandlerMethod.java:205)
at org.springframework.web.method.support.InvocableHandlerMethod.invokeForRequest(InvocableHandlerMethod.java:133)
at org.springframework.web.servlet.mvc.method.annotation.ServletInvocableHandlerMethod.invokeAndHandle(ServletInvocableHandlerMethod.java:97)
at org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.invokeHandlerMethod(RequestMappingHandlerAdapter.java:827)
at org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.handleInternal(RequestMappingHandlerAdapter.java:738)
at org.springframework.web.servlet.mvc.method.AbstractHandlerMethodAdapter.handle(AbstractHandlerMethodAdapter.java:85)
at org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:967)
at org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:901)
at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:970)
at org.springframework.web.servlet.FrameworkServlet.doPost(FrameworkServlet.java:872)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:661)
at org.springframework.web.servlet.FrameworkServlet.service(FrameworkServlet.java:846)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:742)
因为,不知道哪些标签闭合了,哪些标签没有闭合。所以可以采用jsoup来统一处理,规范HTML所有标签的格式,代码如下:
写在最后
在结束之际,我想重申的是,学习并非如攀登险峻高峰,而是如滴水穿石般的持久累积。尤其当我们步入工作岗位之后,持之以恒的学习变得愈发不易,如同在茫茫大海中独自划舟,稍有松懈便可能被巨浪吞噬。然而,对于我们程序员而言,学习是生存之本,是我们在激烈市场竞争中立于不败之地的关键。一旦停止学习,我们便如同逆水行舟,不进则退,终将被时代的洪流所淘汰。因此,不断汲取新知识,不仅是对自己的提升,更是对自己的一份珍贵投资。让我们不断磨砺自己,与时代共同进步,书写属于我们的辉煌篇章。
需要完整版PDF学习资源私我


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









