







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
sta = "厨师"
def cake(self):
print("制作手抓饼")
def cook(self):
print("制作传统煎饼果子")
class app(master):
def cook(self):
print(“制作中西方口味融合的煎饼果子”)
print(“师傅”)
shifu = master()
print(shifu.sta)
shifu.cake()
shifu.cook()
print(“徒弟”)
tudi = app()
print(tudi.sta)
tudi.cake()
tudi.cook()
————————————————————————————————————————————
## 继承 练习
问题描述
创建父类`Pet`,在父类中,使用构造方法定义`name`、`age`、`varietie`,`color`四个实例属性,定义两个方法`eat`和`bark`,重写`__str__()`方法,使得打印对象时将对象的属性全部打印输出。
***要求***
创建子类`Dog`类和子类`Cat`类,在两个子类中要求对方法`eat`和方法`bark`进行重写,在子类`Cat`中,重写构造方法,增加实例属性`sex`,重写`__str__()`方法,要求打印输出时在父类的基础上增加`sex`属性。创建宠物店类PetShop,创建实例属性`shopName`和`petList`,属性`petList`的值为宠物列表,定义方法`showPets`,要求该方法打印宠物店名称和宠物列表。
通过`Dog`类、`Cat`类和`PetShop`类创建对象,然后对三个类中的方法进行调用,查看运行结果。
class Pet:
def __init__(self, name, age, variety, color):
self.name = name
self.age = age
self.variety = variety
self.color = color
def cat(self):
print("宠物要吃东西")
def bark(self):
print("宠物会叫唤")
def \_\_str\_\_(self):
return f"名字: {self.name}, 年龄: {self.age}, 品种: {self.variety}, 颜色:{self.color}"
class Dog(Pet):
def eat(self):
print(self.name+“吃骨头”)
def bark(self):
print(self.name+"汪汪叫")
def guardHose(self):
print(self.name+"看家护院")
class Cat(Pet):
def __init__(self, name, age, variety, color, sex):
super(Cat, self).init(name, age, variety, color)
self.sex = sex
def eat(self):
print(self.name+"喜欢吃鱼")
def bark(self):
print(self.name+"会喵喵叫")
def catchMice(self):
print(self.name+"会抓老鼠")
def \_\_str\_\_(self):
str = super(Cat, self).__str__()
str += ',性别:{0}'.format(self.sex)
return str
class PetShop:
def __init__(self, store_name, *pet_list):
self.store_name = store_name
self.pet_list = pet_list
def showPets(self):
if len(self.pet_list) == 0:
print(self.store_name+"暂无宠物")
return
print(f"{self.store\_name}有{len(self.pet\_list)}个宠物,它们分别是:")
for pet in self.pet_list:
print(pet)
dog1 = Dog(‘旺财’, 3, ‘金毛’, ‘黄色’)
dog1.cat()
dog1.bark()
dog1.guardHose()
print(“-------------------------”)
cat1 = Cat(‘嘟嘟’, 2, ‘咖啡’, ‘灰色’, ‘男’)
cat1.eat()
cat1.bark()
cat1.catchMice()
print(“---------------------------”)
dog2 = Dog(‘黑贝’, 3, ‘牧羊犬’, ‘黑色’)
cat2 = Cat(‘糖果’, 3, ‘布偶’, ‘白色’, ‘女’)
petshop = PetShop(‘乐派宠物店’, dog1, dog2, cat1, cat2)
petshop.showPets()
#### 运行效果如下:
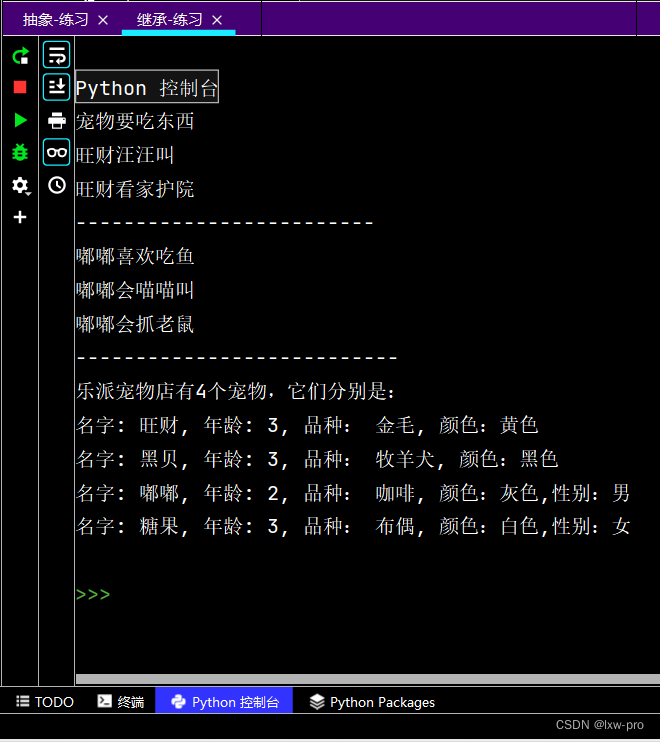
---
### 简单介绍-2
class A:
name = “AA”
def Aprint(self):
print("A类的方法")
class B(A):
def Aprint(self, X):
print(“B类的方法:” + X)
class C(B):
def Aprint(self,name,age):
print("My name is ", name, "I am ", age, “years old!”)
c1 = C()
c1.Aprint(“lxw_pro”, 21) # 调用父类的方法
————————————————————————————————————————————
## 抽象 练习
问题描述
>
> 设计一个宠物口粮花费计算系统(按月计算),其中包括父类Pet,子类Dog、Cat、Pig,提供宠物信息,计算出一个月内该宠物需要多少口粮。其中每只狗狗一天能够吃掉狗粮1KG,狗粮的价格为4元/KG;每只小猫每天能够吃掉0.25KG,猫粮价格为5元/KG,每只宠物猪每天能够吃掉1.5KG猪粮,猪粮的价格为3元/KG。
>
>
>
import abc
class Pet(metaclass=abc.ABCMeta):
def __init__(self, name, age):
self.name = name
self.age = age
@abc.abstractmethod
def mealPay(self):
pass
class Dog(Pet):
def mealPay(self, name):
print(f"我是一只宠物狗,我的名字叫{name}“)
money = 1*4*30
print(f"我每个月的生活费需要{money}元”)
class Cat(Pet):
def mealPay(self, name):
print(f"我是一只宠物猫,我的名字叫{name}“)
money = 0.25*5*30
print(f"我每个月的生活费需要{money}元”)
class Pig(Pet):
def mealPay(self, name):
print(f"我是一只宠物猪猪,我的名字叫{name}“)
money = 1.5*3*30
print(f"我每个月的生活费需要{money}元”)
while True:
print(“宠物月花费计算系统:\n1, 狗狗\n2, 猫猫\n3, 猪猪”)
choice = input(“请输入您的选择:(输入0可退出程序)”)
if choice == ‘0’:
print(“已退出程序!”)
break
if choice == ‘1’:
d1 = Dog(‘大壮’, 3)
d1.mealPay(d1.name)
elif choice == ‘2’:
c1 = Cat(‘圆圆’, 2)
c1.mealPay(c1.name)
elif choice == ‘3’:
p1 = Pig(‘嘟嘟’, 2)
p1.mealPay(p1.name)
else:
print(“您的输入有误,请重新输入:”)
#### 运行效果如下:
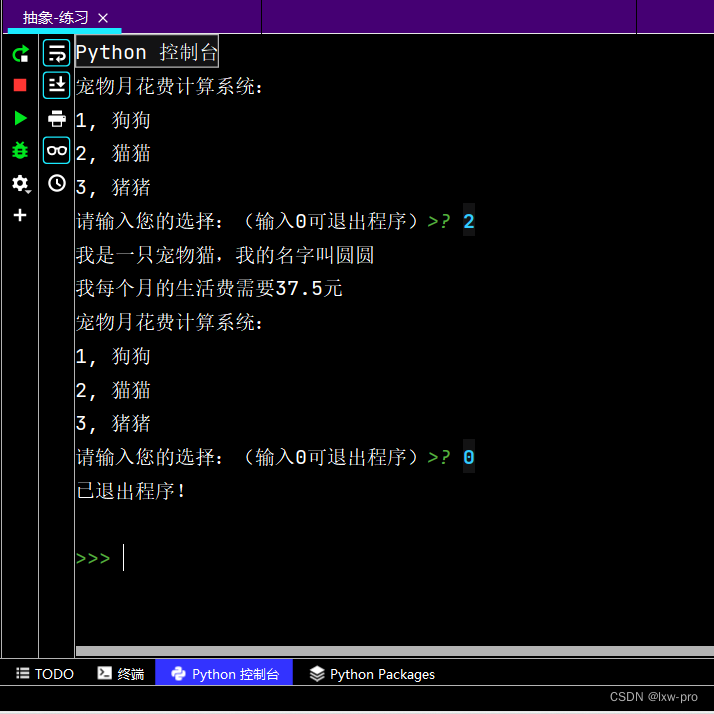
————————————————————————————————————————————
## pandas 每日一练:
-- coding = utf-8 --
@Time : 2022/7/25 14:10
@Author : lxw_pro
@File : pandas-7 练习.py
@Software : PyCharm
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_excel(‘text5.xlsx’)
print(df)
#### 程序运行结果为:
Unnamed: 0 Unnamed: 0.1 project … test_time date time
0 0 00:00:00 Python … 2022-06-20 18:30:20 2022-06-20 18:30:20
1 1 1 Java … 2022-06-18 19:40:20 2022-06-18 19:40:20
2 2 2 C … 2022-06-08 13:33:20 2022-06-08 13:33:20
3 3 3 MySQL … 2021-12-23 11:26:20 2021-12-23 11:26:20
4 4 4 Linux … 2021-12-20 18:20:20 2021-12-20 18:20:20
5 5 5 Math … 2022-07-20 16:30:20 2022-07-20 16:30:20
6 6 6 English … 2022-06-23 15:30:20 2022-06-23 15:30:20
7 7 7 Python … 2022-07-19 09:30:20 2022-07-19 09:30:20
[8 rows x 7 columns]
---
### 31、计算 popularity 列的中位数
zws = np.median(df[‘popularity’])
print(f"popularity列的中位数为:{zws}")
#### 程序运行结果为:
popularity列的中位数为:143.0
---
### 32、绘制成绩水平频率分布直方图
df.popularity.plot(kind=‘hist’)
plt.show()
#### 程序运行效果为:
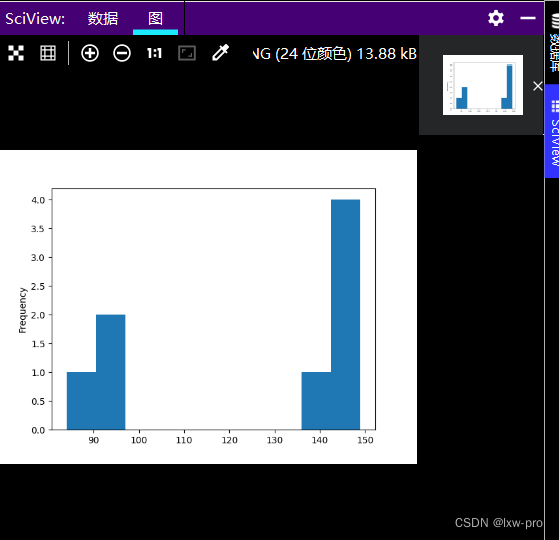
---
### 33、绘制成绩水平密度曲线
df.popularity.plot(kind=‘kde’, xlim=(0, 150))
plt.show()
#### 程序运行效果为:
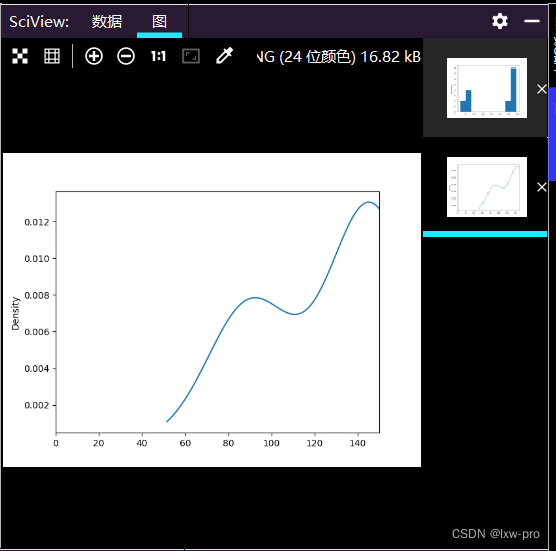
---
### 34、删除最后一列time
`法一`:
del df[‘time’]
print(“删除最后一列time后的表为:\n”, df)
#### 程序运行结果为:
删除最后一列time后的表为:
Unnamed: 0 Unnamed: 0.1 project popularity test_time date
0 0 00:00:00 Python 95 2022-06-20 18:30:20 2022-06-20
1 1 1 Java 92 2022-06-18 19:40:20 2022-06-18
2 2 2 C 145 2022-06-08 13:33:20 2022-06-08
3 3 3 MySQL 141 2021-12-23 11:26:20 2021-12-23
4 4 4 Linux 84 2021-12-20 18:20:20 2021-12-20
5 5 5 Math 148 2022-07-20 16:30:20 2022-07-20
6 6 6 English 146 2022-06-23 15:30:20 2022-06-23
7 7 7 Python 149 2022-07-19 09:30:20 2022-07-19
---
`法二`:
df.drop(columns=[‘date’], inplace=True)
print(“删除列date后的表为:\n”, df)
#### 程序运行结果为:
删除列date后的表为:
Unnamed: 0 Unnamed: 0.1 project popularity test_time
0 0 00:00:00 Python 95 2022-06-20 18:30:20
1 1 1 Java 92 2022-06-18 19:40:20
2 2 2 C 145 2022-06-08 13:33:20
3 3 3 MySQL 141 2021-12-23 11:26:20
4 4 4 Linux 84 2021-12-20 18:20:20
5 5 5 Math 148 2022-07-20 16:30:20
6 6 6 English 146 2022-06-23 15:30:20
7 7 7 Python 149 2022-07-19 09:30:20
---
### 35、将df的第一列与第三列合并为新的一列
df[‘test’] = df[‘project’]+[‘test-time’]
print(“将df第一列与第三列合并为新的一列后的表为:\n”, df)
#### 程序运行结果为:
将df第一列与第三列合并为新的一列后的表为:
Unnamed: 0 Unnamed: 0.1 … test_time test
0 0 00:00:00 … 2022-06-20 18:30:20 Pythontest-time
1 1 1 … 2022-06-18 19:40:20 Javatest-time
2 2 2 … 2022-06-08 13:33:20 Ctest-time
3 3 3 … 2021-12-23 11:26:20 MySQLtest-time
4 4 4 … 2021-12-20 18:20:20 Linuxtest-time
5 5 5 … 2022-07-20 16:30:20 Mathtest-time
6 6 6 … 2022-06-23 15:30:20 Englishtest-time
7 7 7 … 2022-07-19 09:30:20 Pythontest-time
[8 rows x 6 columns]
---
### 36、将project列与popularity列合并为新的一列
df[‘text’] = df[‘project’]+df[‘popularity’].map(str)
print(“将project列于popularity列合并为新的一列后的表为:\n”, df)
#### 程序运行结果为:
将project列于popularity列合并为新的一列后的表为:
Unnamed: 0 Unnamed: 0.1 … test text
0 0 00:00:00 … Pythontest-time Python95
1 1 1 … Javatest-time Java92
2 2 2 … Ctest-time C145
3 3 3 … MySQLtest-time MySQL141
4 4 4 … Linuxtest-time Linux84
5 5 5 … Mathtest-time Math148
6 6 6 … Englishtest-time English146
7 7 7 … Pythontest-time Python149
[8 rows x 7 columns]
---
### 37、计算popularity最大值与最小值之差
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
5 5 5 … Mathtest-time Math148
6 6 6 … Englishtest-time English146
7 7 7 … Pythontest-time Python149
[8 rows x 7 columns]
---
### 37、计算popularity最大值与最小值之差
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)
[外链图片转存中…(img-AUssAl6t-1713362436544)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









