







(4)网贷天眼:网贷平台、行业数据。
(5)76676互联网金融门户:网贷、P2P、理财等互金数据。
3.公司年报
(1)巨潮资讯:各种股市咨询,公司股票、财务信息。
(2)SEC.gov:美国证券交易数据
(3)HKEx news披露易:年度业绩报告和年报。
4.创投数据
(1)36氪:最新的投资资讯。
(2)投资潮:投资资讯、上市公司信息。
(3)IT桔子:各种创投数据。
5.社交平台
(1)新浪微博:评论、舆情数据,社交关系数据。
(2)Twitter:舆情数据,社交关系数据。
(3)知乎:优质问答、用户数据。
(4)微信公众号:公众号运营数据。
(5)百度贴吧:舆情数据
(6)Tumblr:各种福利图片、视频。
6.就业招聘
(1)拉勾:互联网行业人才需求数据。
(2)中华英才网:招聘信息数据。
(3)智联招聘:招聘信息数据。
(4)猎聘网:高端职位招聘数据。
7.餐饮食品
(1)美团外卖:区域商家、销量、评论数据。
(2)百度外卖:区域商家、销量、评论数据。
(3)饿了么:区域商家、销量、评论数据。
(4)大众点评:点评、舆情数据。
8.交通旅游
(1)12306:铁路运行数据。
(2)携程:景点、路线、机票、酒店等数据。
(3)去哪儿:景点、路线、机票、酒店等数据。
(4)途牛:景点、路线、机票、酒店等数据。
(5)猫途鹰:世界各地旅游景点数据,来自全球旅行者的真实点评。
类似的还有同程、驴妈妈、途家等
9.电商平台
(1)亚马逊:商品、销量、折扣、点评等数据
(2)淘宝:商品、销量、折扣、点评等数据
(3)天猫:商品、销量、折扣、点评等数据
(4)京东:3C产品为主的商品信息、销量、折扣、点评等数据
(5)当当:图书信息、销量、点评数据。
类似的唯品会、聚美优品、1号店等。
10.影音数据
(1)豆瓣电影:国内最受欢迎的电影信息、评分、评论数据。
(2)时光网:最全的影视资料库,评分、影评数据。
(3)猫眼电影专业版:实时票房数据,电影票房排行。
(4)网易云音乐:音乐歌单、歌手信息、音乐评论数据。
11.房屋信息
(1)58同城房产:二手房数据。
(2)安居客:新房和二手房数据。
(3)Q房网:新房信息、销售数据。
(4)房天下:新房、二手房、租房数据。
(5)小猪短租:短租房源数据。
12.购车租车
(1)网易汽车:汽车资讯、汽车数据。
(2)人人车:二手车信息、交易数据。
(3)中国汽车工业协会:汽车制造商产量、销量数据。
13.新媒体数据
新榜:新媒体平台运营数据。
清博大数据:微信公众号运营榜单及舆情数据。
微问数据:一个针对微信的数据网站。
知微传播分析:微博传播数据。
14.分类信息
(1)58同城:丰富的同城分类信息。
(2)赶集网:丰富的同城分类信息。
如果你是小白,想通过爬虫获得有价值的数据,推荐我们的体系课程——Python爬虫:入门+进阶
三、数据交易平台
由于现在数据的需求很大,也催生了很多做数据交易的平台,当然,出去付费购买的数据,在这些平台,也有很多免费的数据可以获取。
优易数据:由国家信息中心发起,拥有国家级信息资源的数据平台,国内领先的数据交易平台。平台有B2B、B2C两种交易模式,包含政务、社会、社交、教育、消费、交通、能源、金融、健康等多个领域的数据资源。

数据堂:专注于互联网综合数据交易,提供数据交易、处理和数据API服务,包含语音识别、医疗健康、交通地理、电子商务、社交网络、图像识别等方面的数据。

四、网络指数
百度指数:指数查询平台,可以根据指数的变化查看某个主题在各个时间段受关注的情况,进行趋势分析、舆情预测有很好的指导作用。除了关注趋势之外,还有需求分析、人群画像等精准分析的工具,对于市场调研来说具有很好的参考意义。同样的另外两个搜索引擎搜狗、360也有类似的产品,都可以作为参考。

阿里指数:国内权威的商品交易分析工具,可以按地域、按行业查看商品搜索和交易数据,基于淘宝、天猫和1688平台的交易数据基本能够看出国内商品交易的概况,对于趋势分析、行业观察意义不小。

友盟指数:友盟在移动互联网应用数据统计和分析具有较为全面的统计和分析,对于研究移动端产品、做市场调研、用户行为分析很有帮助。除了友盟指数,友盟的互联网报告同样是了解互联网趋势的优秀读物。

爱奇艺指数:爱奇艺指数是专门针对视频的播放行为、趋势的分析平台,对于互联网视频的播放有着全面的统计和分析,涉及到播放趋势、播放设备、用户画像、地域分布、等多个方面。由于爱奇艺庞大的用户基数,该指数基本可以说明实际情况。
微指数:微指数是新浪微博的数据分析工具,微指数通过关键词的热议度,以及行业/类别的平均影响力,来反映微博舆情或账号的发展走势。分为热词指数和影响力指数两大模块,此外,还可以查看热议人群及各类账号的地域分布情况。

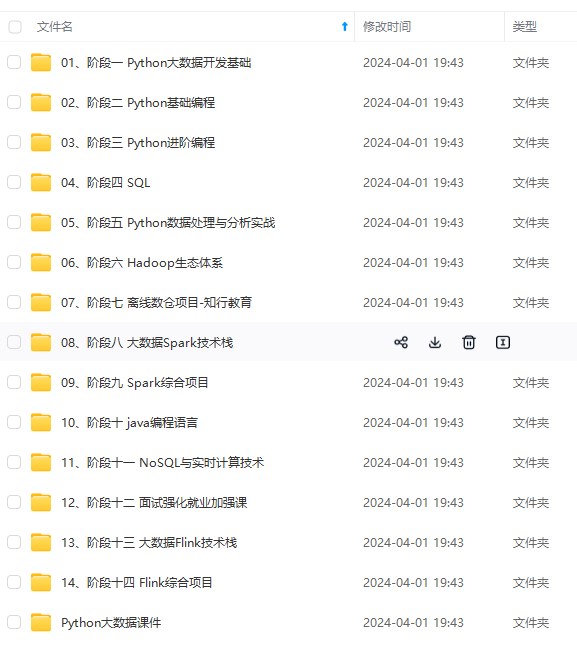
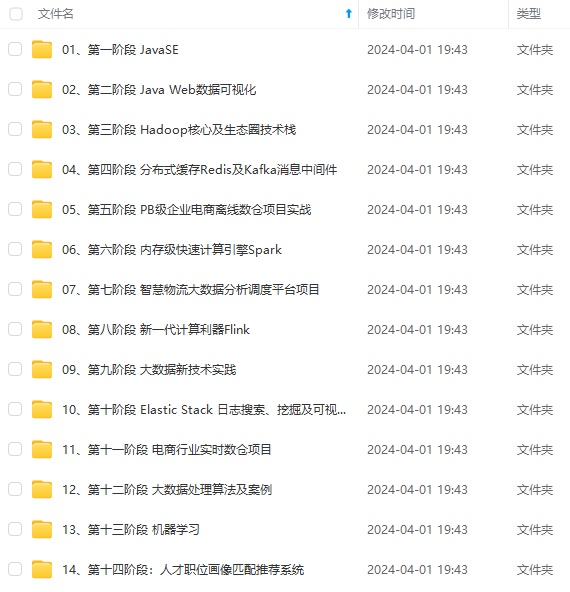
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
[外链图片转存中…(img-BxjDwPsR-1714661809226)]
[外链图片转存中…(img-5WgcBL2e-1714661809227)]
[外链图片转存中…(img-zLLgolQy-1714661809227)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新

















 856
856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









