







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
+ 掌握定时调度的使用方式
13:Airflow常用命令
-
目标:了解AirFlow的常用命令
-
实施
- 列举当前所有的dag
airflow dags list- 暂停某个DAG
airflow dags pause dag_name- 启动某个DAG
airflow dags unpause dag_name- 删除某个DAG
airflow dags delete dag_name- 执行某个DAG
airflow dags trigger dag_name- 查看某个DAG的状态
airflow dags state dag_name- 列举某个DAG的所有Task
airflow tasks list dag_name -
小结
- 了解AirFlow的常用命令
14:邮件告警使用
-
目标:了解AirFlow中如何实现邮件告警
-
路径
- step1:AirFlow配置
- step2:DAG配置
-
实施
-
原理:自动发送邮件的原理:邮件第三方服务
- 发送方账号:配置文件中配置
smtp_user = 12345678910@163.com # 秘钥id:需要自己在第三方后台生成 smtp_password = 自己生成的秘钥 # 端口 smtp_port = 25 # 发送邮件的邮箱 smtp_mail_from = 12345678910@163.com- 接收方账号:程序中配置
default_args = { 'owner': 'airflow', 'email': ['jiangzonghai@itcast.cn'], 'email_on_failure': True, 'email_on_retry': True, 'retries': 1, 'retry_delay': timedelta(minutes=1), } -
AirFlow配置:airflow.cfg
# 发送邮件的代理服务器地址及认证:每个公司都不一样 smtp_host = smtp.163.com smtp_starttls = True smtp_ssl = False # 发送邮件的账号 smtp_user = 12345678910@163.com # 秘钥id:需要自己在第三方后台生成 smtp_password = 自己生成的秘钥 # 端口 smtp_port = 25 # 发送邮件的邮箱 smtp_mail_from = 12345678910@163.com # 超时时间 smtp_timeout = 30 # 重试次数 smtp_retry_limit = 5- 关闭Airflow
# 统一杀掉airflow的相关服务进程命令 ps -ef|egrep 'scheduler|flower|worker|airflow-webserver'|grep -v grep|awk '{print $2}'|xargs kill -9 # 下一次启动之前 rm -f /root/airflow/airflow-*- 程序配置
default_args = { 'email': ['jiangzonghai@itcast.cn'], 'email\_on\_failure': True, 'email\_on\_retry': True }- 启动Airflow
airflow webserver -D airflow scheduler -D airflow celery flower -D airflow celery worker -D- 模拟错误

-
-
小结
- 了解AirFlow中如何实现邮件告警
15:一站制造中的调度
-
目标:了解一站制造中调度的实现
-
实施
- ODS层 / DWD层:定时调度:每天00:05开始运行
- dws(11)
- dws耗时1小时
- 从凌晨1点30分开始执行
- dwb(16)
- dwb耗时1.5小时
- 从凌晨3点开始执行
- st(10)
- st耗时1小时
- 从凌晨4点30分开始执行
- dm(1)
- dm耗时0.5小时
- 从凌晨5点30分开始执行
-
小结
- 了解一站制造中调度的实现
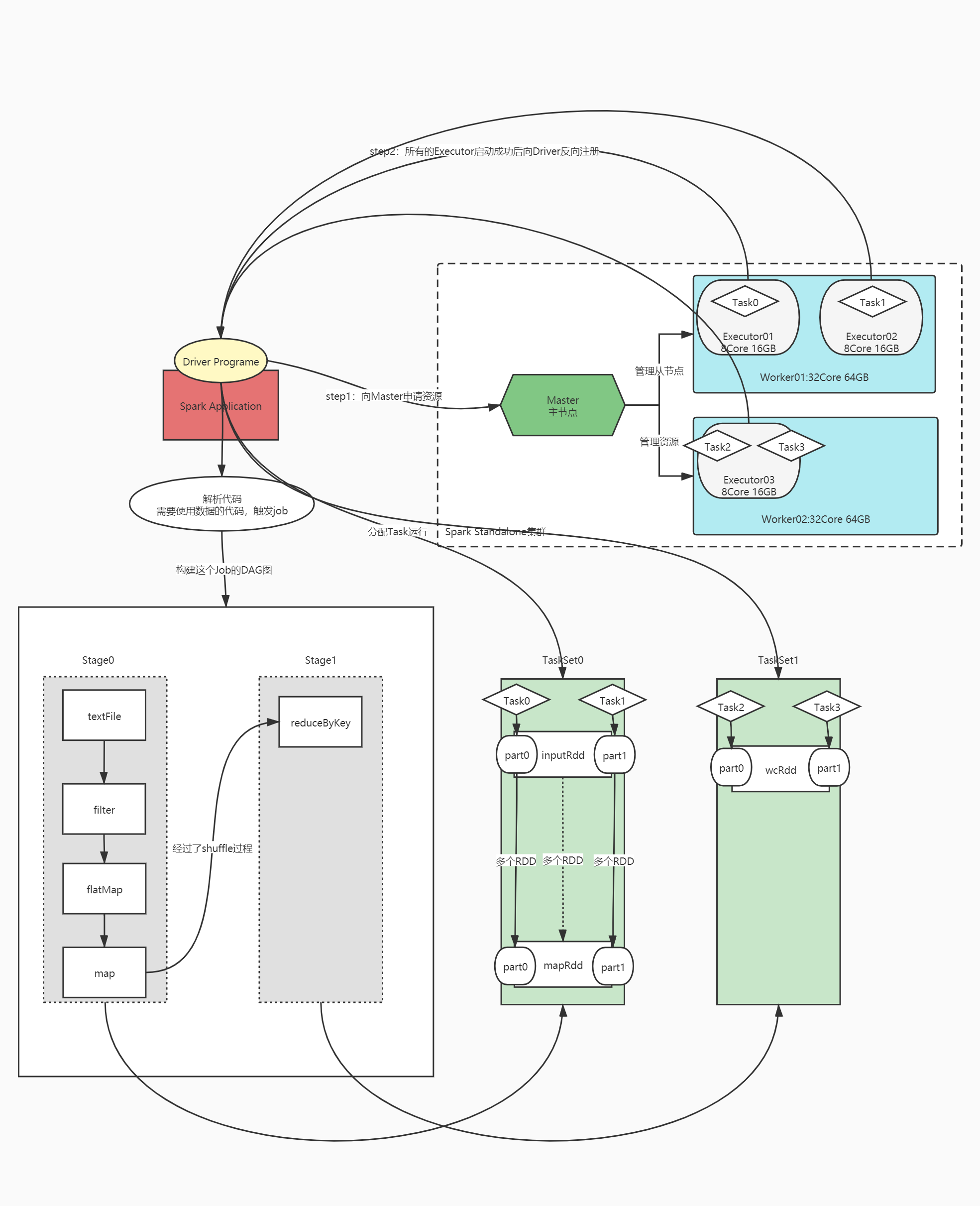
16:回顾:Spark核心概念
-
什么是分布式计算?
- 分布式程序:MapReduce、Spark、Flink程序
- 多进程:一个程序由多个进程来共同实现,不同进程可以运行在不同机器上
- 每个进程所负责计算的数据是不一样,都是整体数据的某一个部分
- 自己基于MapReduce或者Spark的API开发的程序:数据处理的逻辑
- 分逻辑
- MR
- ·MapTask进程:分片规则:基于处理的数据做计算
- 判断:文件大小 / 128M > 1.1
- 大于:按照每128M分
- 小于:整体作为1个分片
- 大文件:每128M作为一个分片
- 一个分片就对应一个MapTask
- 判断:文件大小 / 128M > 1.1
- ReduceTask进程:指定
- ·MapTask进程:分片规则:基于处理的数据做计算
- Spark
- Executor:指定
- 分布式资源:YARN、Standalone资源容器
- 将多台机器的物理资源:CPU、内存、磁盘从逻辑上合并为一个整体
- YARN:ResourceManager、NodeManager【8core8GB】
- 每个NM管理每台机器的资源
- RM管理所有的NM
- Standalone:Master、Worker
- 实现统一的硬件资源管理:MR、Flink、Spark on YARN
- 分布式程序:MapReduce、Spark、Flink程序
-
Spark程序的组成结构?
- Application:程序
- 进程:一个Driver、多个Executor
- 运行:多个Job、多个Stage、多个Task
-
什么是Standalone?
- Spark自带的集群资源管理平台
-
为什么要用Spark on YARN?
- 为了实现资源统一化的管理,将所有程序都提交到YARN运行
-
Master和Worker是什么?
- 分布式主从架构:Hadoop、Hbase、Kafka、Spark……
- 主:管理节点:Master
- 接客
- 管理从节点
- 管理所有资源
- 主:管理节点:Master
- 分布式主从架构:Hadoop、Hbase、Kafka、Spark……

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
-1715732742007)]
[外链图片转存中…(img-EZwP3ldD-1715732742008)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









