








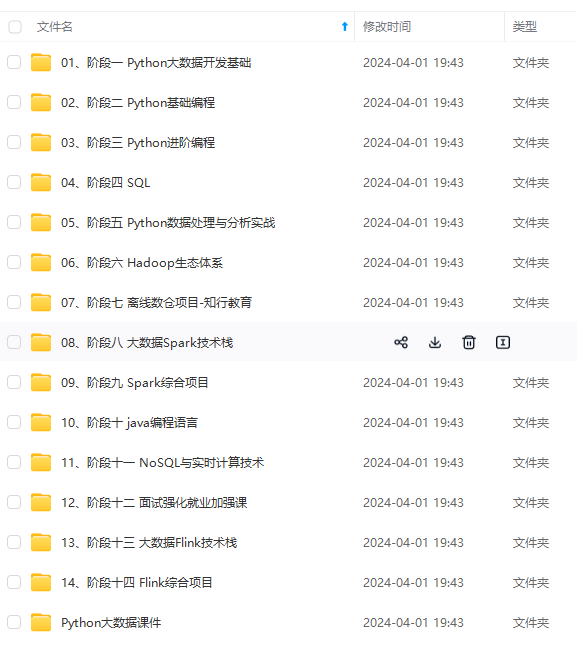
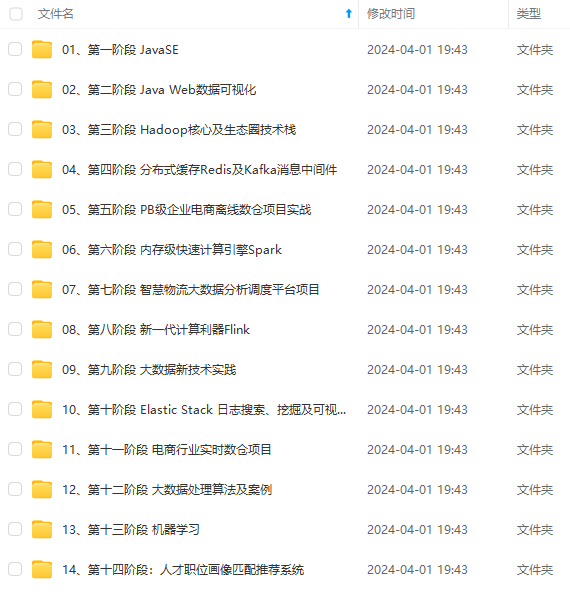
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
使用说明
排序键的相关说明:
在建表语句中,排序键必须定义在其他列之前。
排序键可以通过 DUPLICATE KEY 显式定义。本示例中排序键为 event_time 和 event_type。
如果未指定,则默认选择表的前三列作为排序键。
明细模型中的排序键可以为部分或全部维度列。
建表时,支持为指标列创建 BITMAP、Bloom Filter 等索引。
4.2 聚合模型(Aggregate key)
建表时,支持定义排序键和指标列,并为指标列指定聚合函数。当多条数据具有相同的排序键时,指标列会进行聚合。在分析统计和汇总数据时,聚合模型能够减少查询时所需要处理的数据,提升查询效率。
适用场景
适用于分析统计和汇总数据。比如:
通过分析网站或 APP 的访问流量,统计用户的访问总时长、访问总次数。
广告厂商为广告主提供的广告点击总量、展示总量、消费统计等。
通过分析电商的全年交易数据,获得指定季度或者月份中,各类消费人群的爆款商品。
在这些场景中,数据查询和导入,具有以下特点:
多为汇总类查询,比如 SUM、MAX、MIN等类型的查询。
不需要查询原始的明细数据。
旧数据更新不频繁,只会追加新的数据。
原理
从数据导入至数据查询阶段,聚合模型内部同一排序键的数据会多次聚合,聚合的具体时机和机制如下:
数据导入阶段:数据按批次导入至聚合模型时,每一个批次的数据形成一个版本。在一个版本中,同一排序键的数据会进行一次聚合。
后台文件合并阶段 (Compaction) :数据分批次多次导入至聚合模型中,会生成多个版本的文件,多个版本的文件定期合并成一个大版本文件时,同一排序键的数据会进行一次聚合。
查询阶段:所有版本中同一排序键的数据进行聚合,然后返回查询结果。
注意
建表时必须使用 DISTRIBUTED BY HASH 子句指定分桶键。分桶键的更多说明,请参见分桶。
自 2.5.7 版本起,StarRocks 支持在建表和新增分区时自动设置分桶数量 (BUCKETS),您无需手动设置分桶数量。
使用说明
排序键的相关说明:
在建表语句中,排序键必须定义在其他列之前。
排序键可以通过 AGGREGATE KEY 显式定义。
如果 AGGREGATE KEY 未包含全部维度列(除指标列之外的列),则建表会失败。
如果不通过 AGGREGATE KEY 显示定义排序键,则默认除指标列之外的列均为排序键。
排序键必须满足唯一性约束,必须包含全部维度列,并且列的值不会更新。
指标列:
通过在列名后指定聚合函数,定义该列为指标列。一般为需要汇总统计的数据。
聚合函数:
指标列使用的聚合函
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2550
2550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









