








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
-
目标:阅读连接代码及实现连接代码测试
-
路径
- step1:连接代码讲解
- step2:连接代码测试
-
实施
-
为什么要获取连接?
- Python连接Oracle:获取表的元数据
- 表的信息:TableMeta
- 表名
- 表的注释
- list:[列的信息]
- 列的信息:ColumnMeta
- 列名
- 列的注释
- 列的类型
- 类型长度
- 类型精度
-
Python连接HiveServer或者Spark的ThriftServer:提交SQL语句
-
连接代码讲解
-
step1:怎么获取连接?
- Oracle:安装Python操作Oracle库包:cx_Oracle
cx_Oracle.connect(ORACLE_USER, ORACLE_PASSWORD, dsn)- Hive/SparkSQL:安装Python操作Hive库包:PyHive
hive.Connection(host=SPARK_HIVE_HOST, port=SPARK_HIVE_PORT, username=SPARK_HIVE_UNAME, auth=‘CUSTOM’, password=SPARK_HIVE_PASSWORD)
+ step2:连接时需要哪些参数? - Oracle:主机名、端口、用户名、密码、SID - Hive:主机名、端口、用户名、密码 + step3:如果有100个代码都需要构建Hive连接,怎么解决呢? - 将所有连接参数写入一个配置文件:resource/config.txt - 通过配置文件的工具类获取配置:ConfigLoader + step4:在ODS层建101张表,表名怎么动态获取呢? - 读取表名文件:将每张表的名称都存储在一个列表中 + step5:ODS层的表分为全量表与增量表,怎么区分呢? - 通过对@符号的分割,将全量表和增量表的表名存储在不同的列表中
-
-
连接代码测试
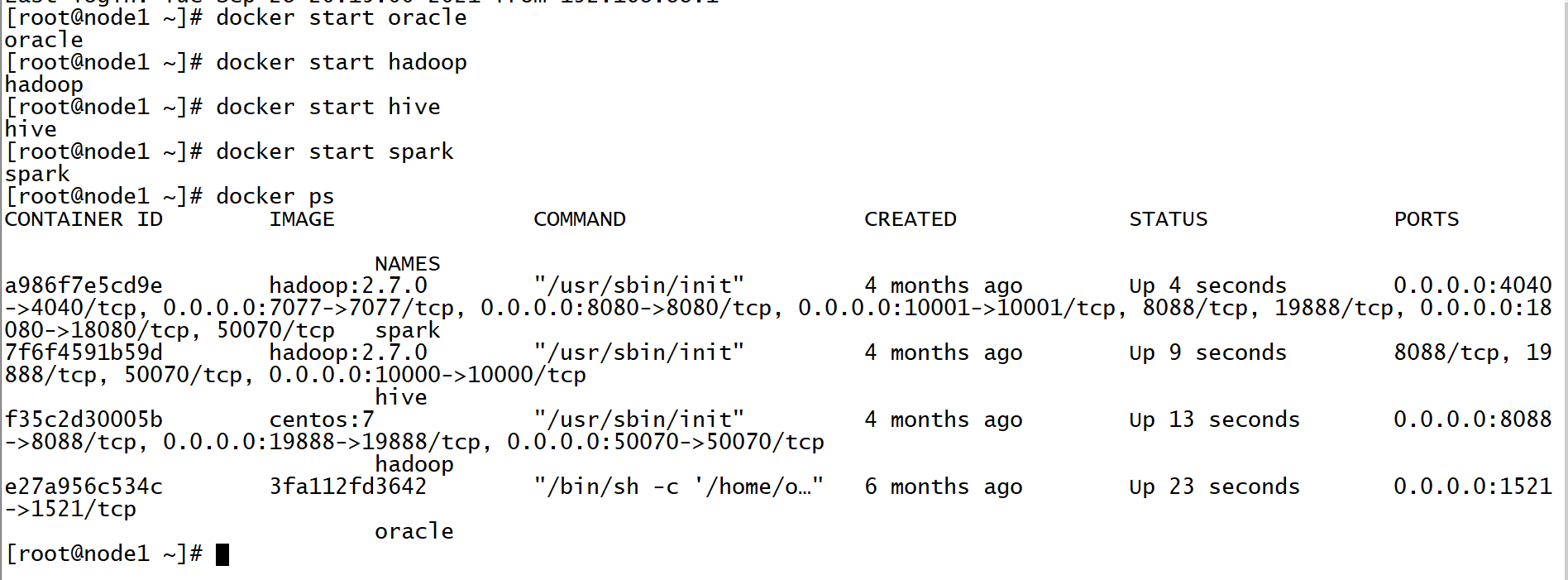
- 启动虚拟运行环境
-
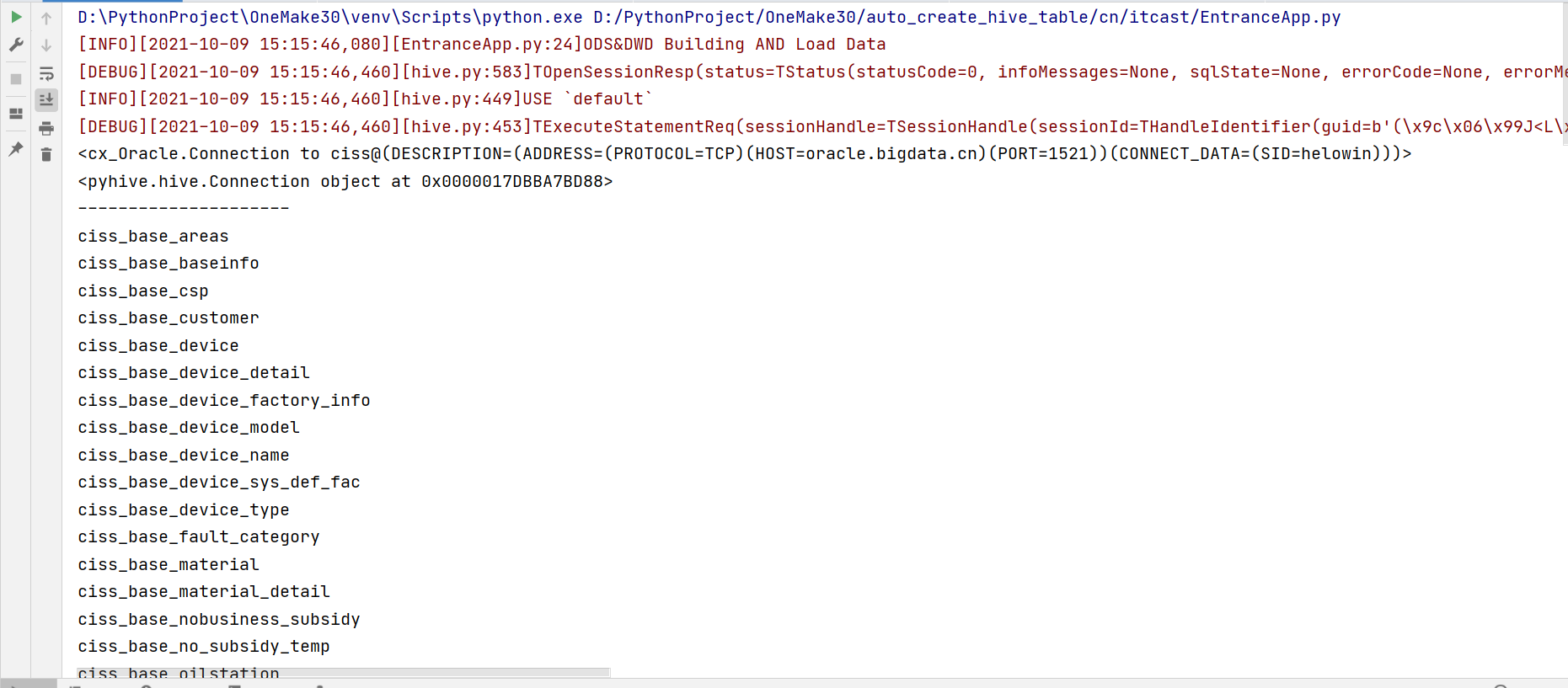
运行测试代码
- 注释掉第2 ~ 第6阶段的内容
- 取消测试代码的注释
- 执行代码观察结果
-
-
小结
- 阅读连接代码及实现连接代码测试
03:ODS层构建:建库代码及测试
-
目标:阅读ODS建库代码及实现测试
-
路径
- step1:代码讲解
- step2:代码测试
-
实施
-
代码讲解
- step1:ODS层的数据库名称叫什么?
one_make_ods-
step2:如何使用PyHive创建数据库?
- 第一步:先获取连接
- 第二步:拼接SQL语句,从连接对象中获取一个游标
- 第三步:使用游标执行SQL语句
- 第四步:释放资源
-
代码测试
- 注释掉第3 ~ 第6阶段的内容
- 运行代码,查看结果
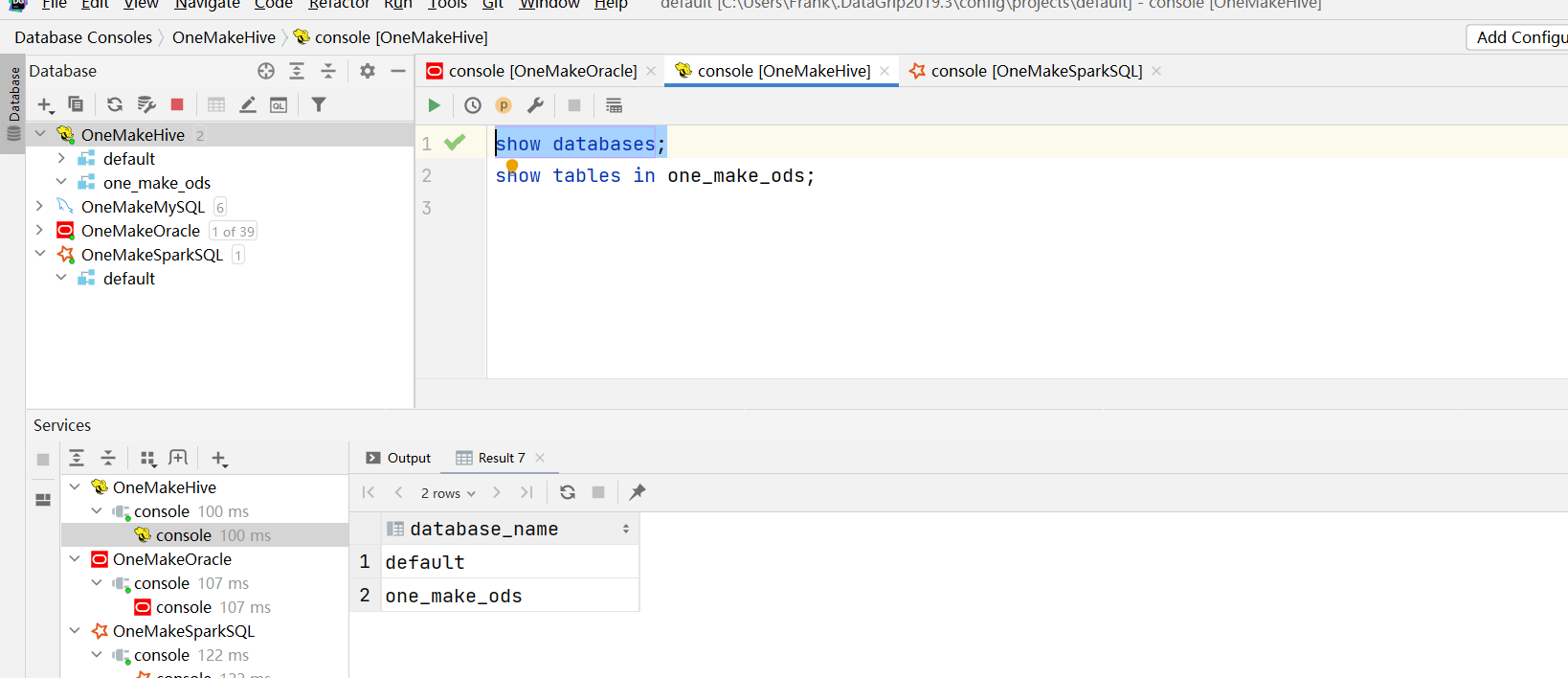
-
-
小结
- 阅读ODS建库代码及实现测试
04:ODS层构建:建表代码及测试
-
目标:阅读ODS建表代码及实现测试
-
路径
- step1:代码讲解
- step2:代码测试
-
实施
-
代码讲解
- step1:表名怎么获取?
tableNameList【full_list,incr_list】 full_list:全量表名的列表 incr_list:增量表名的列表- step2:建表的语句是什么,哪些是动态变化的?
create external table 数据库名称.表名 comment '表的注释' partitioned by ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat' location '这张表在HDFS上的路径' TBLPROPERTIES ('这张表的Schema文件在HDFS上的路径')* 表名 * 表的注释 * 表的HDFS地址 * Schema文件的HDFS地址-
step3:怎么获取表的注释?
- 从Oracle中获取:从系统表中获取某张表的信息和列的信息
select columnName, dataType, dataScale, dataPercision, columnComment, tableComment from ( select column_name columnName, data_type dataType, DATA_SCALE dataScale, DATA_PRECISION dataPercision, TABLE_NAME from all_tab_cols where 'CISS_CSP_WORKORDER' = table_name) t1 left join ( select comments tableComment,TABLE_NAME from all_tab_comments WHERE 'CISS_CSP_WORKORDER' = TABLE_NAME) t2 on t1.TABLE_NAME = t2.TABLE_NAME left join ( select comments columnComment, COLUMN_NAME from all_col_comments WHERE TABLE_NAME='CISS_CSP_WORKORDER') t3 on t1.columnName = t3.COLUMN_NAME;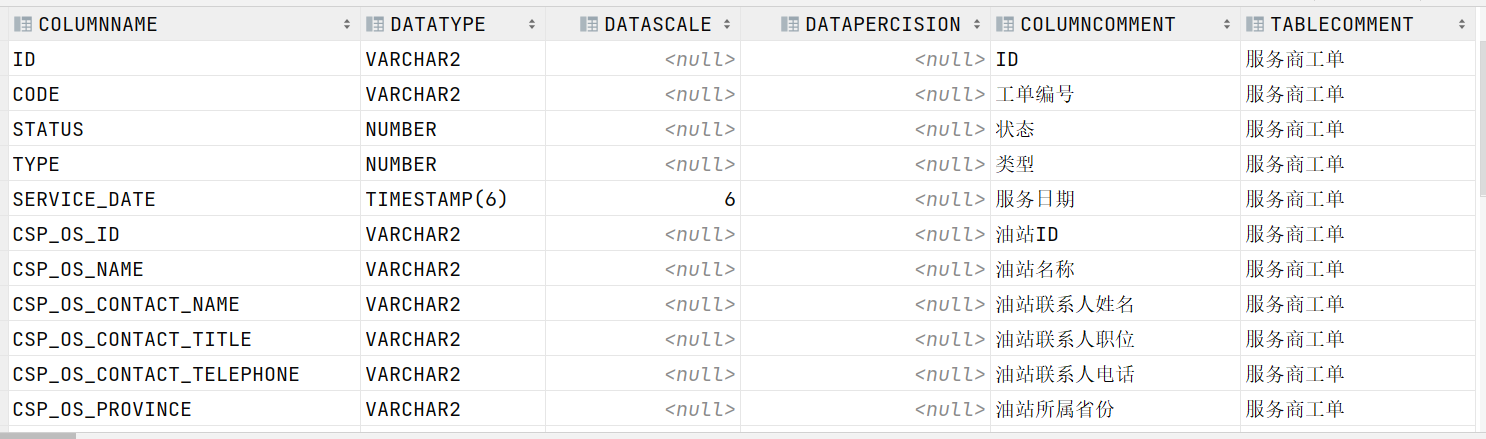
-
step4:全量表与增量表有什么区别?
- 区别1:表名不一样
- full_table_list
- incr_table_list
- 区别2:路径不一样
/data /dw /ods /one_make /full /Oracle库名.表名/data /dw /ods /one_make /incr /Oracle库名.表名
- 区别1:表名不一样
-
step5:如何实现自动化建表?
- 自动化创建全量表
- 获取全量表名
- 调用建表方法:数据库名称、表名、全量标记
- 通过Oracle工具类获取表的信息【表的名称、表的注释、字段信息等】
- 拼接建表语句
- 执行SQL语句
- 自动化创建增量表
- 获取增量表名
- 调用建表方法:数据库名称、表名、增量标记
- 通过Oracle工具类获取表的信息【表的名称、表的注释、字段信息等】
- 拼接建表语句
- 执行SQL语句
- 自动化创建全量表
-
代码测试
- 注释掉第4~ 第6阶段的内容
- 运行代码,查看结果
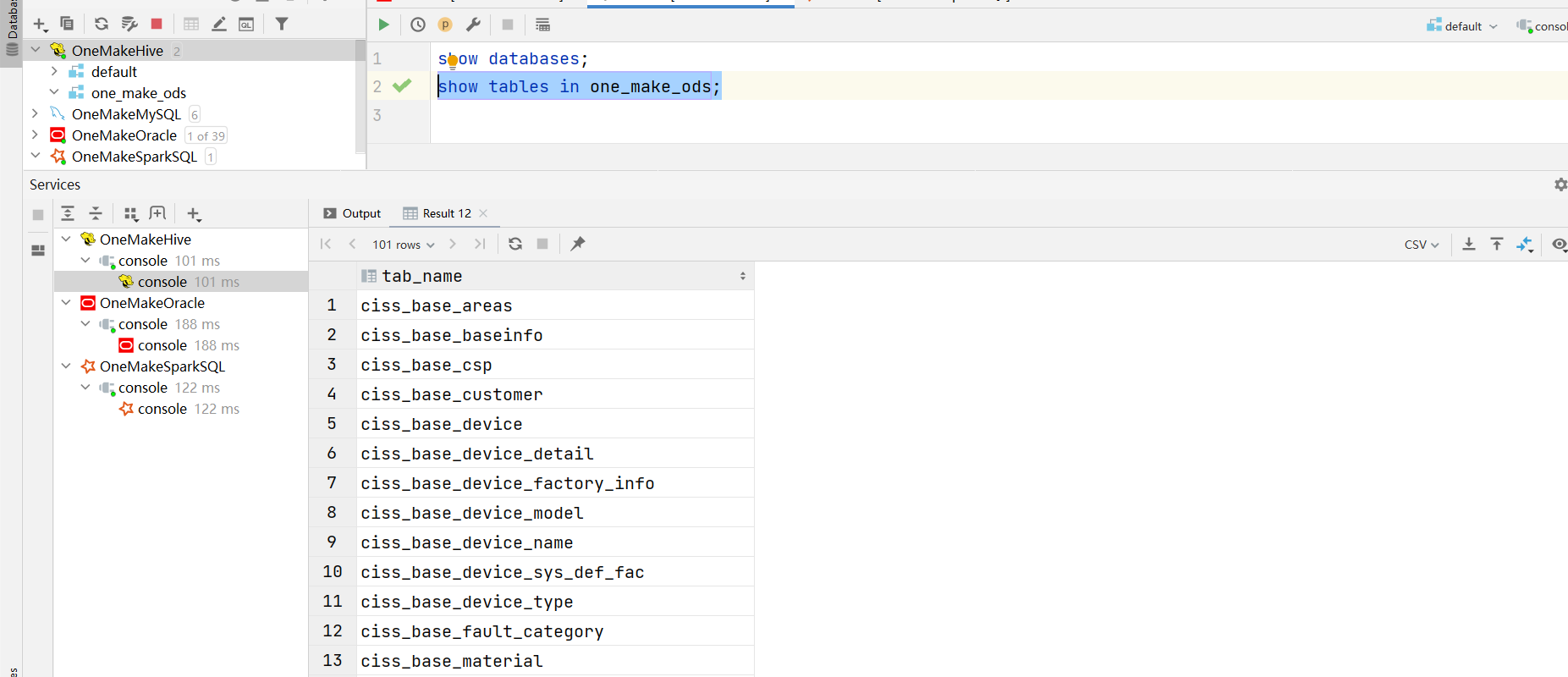
-
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
2356308)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









