







 本文介绍了Spark SQL的基础配置和使用,包括编译问题解决、环境搭建、Standalone模式、本地IDE配置、HiveContextAPP的使用以及Spark Shell的启动。在Standalone模式下,通过配置spark-env.sh和slaves文件启动master和worker。在遇到编译失败时,需检查环境变量和依赖。在IDE中,设置-Dspark.master=local以本地运行。对于HiveContextAPP,不需要预先安装Hive即可使用,并需引入hive-site.xml配置。
本文介绍了Spark SQL的基础配置和使用,包括编译问题解决、环境搭建、Standalone模式、本地IDE配置、HiveContextAPP的使用以及Spark Shell的启动。在Standalone模式下,通过配置spark-env.sh和slaves文件启动master和worker。在遇到编译失败时,需检查环境变量和依赖。在IDE中,设置-Dspark.master=local以本地运行。对于HiveContextAPP,不需要预先安装Hive即可使用,并需引入hive-site.xml配置。
[hadoop@hadoop001 spark-2.1.0]$ cat pom.xml
[hadoop@hadoop001 spark-2.1.0]$ pwd
/home/hadoop/source/spark-2.1.0
<properties>
<hadoop.version>2.2.0</hadoop.version>
<protobuf.version>2.5.0</protobuf.version>
<yarn.version>${hadoop.version}</yarn.version>
......
</properties>
...............
<profile>
<id>hadoop-2.6</id>
<properties>
<hadoop.version>2.6.4</hadoop.version>
<jets3t.version>0.9.3</jets3t.version>
<zookeeper.version>3.4.6</zookeeper.version>
<curator.version>2.6.0</curator.version>
</properties>
</profile>
路径下执行
[hadoop@hadoop001 spark-2.1.0]$ pwd
/home/hadoop/source/spark-2.1.0
==> ./build/mvn -Pyarn -Phadoop-2.6 -Phive -Phive-thriftserver -Dhadoop.version=2.6.0-cdh5.7.0 -DskipTests clean package
编译可以运行的包
./dev/make-distribution.sh --name 2.6.0-cdh5.7.0 --tgz -Pyarn -Phadoop-2.6 -Phive -Phive-thriftserver -Dhadoop.version=2.6.0-cdh5.7.0
make-distribution.sh
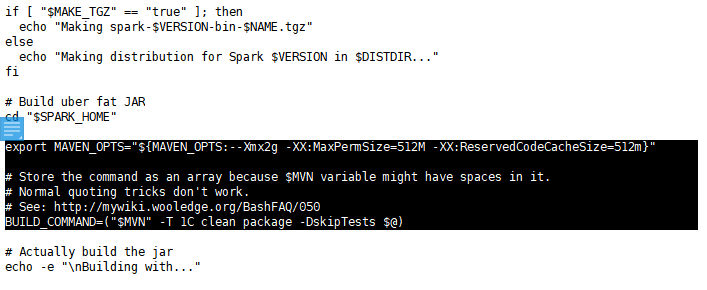
spark-$VERSION-bin-$NAME.tgz
—>spark-2.1.0-bin-2.6.0-cdh5.7.0.tgz
编译失败
Failed to execute goal on project ...: Could not resolve dependencies for project ...
在pom.xml中添加
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
如果scala是2.10
需要添加./dev/change-scala-version.sh 2.10
环境搭建
local
tar -zxvf park-2.1.0-bin-2.6.0-cdh5.7.0.tgz -C ~/app/- 配置环境
SPARK_HOME - source ~./bash_profile
运行
spark-shell --master local[2]
at org.apache.spark.repl.SparkILoop$$anonfun$initializeSpark$1.apply(SparkILoop.scala:37)
at org.apache.spark.repl.SparkILoop$$anonfun$initializeSpark$1.apply(SparkILoop.scala:37)
a)
Caused by: org.datanucleus.exceptions.NucleusException: Attempt to invoke the "BONECP" plugin to create a ConnectionPool gave an error : The specified datastore driver ("com.mysql.jdbc.Driver") was not found in the CLASSPATH. Please check your CLASSPATH specification, and the name of the driver.
at org.datanucleus.store.rdbms.ConnectionFactoryImpl.generateDataSources(ConnectionFactoryImpl.java:259)
java:104)
.............................................
at org.apache.hadoop.hive.ql.metadata.Hive.createMetaStoreClient(Hive.java:3005)
571)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HM 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









