







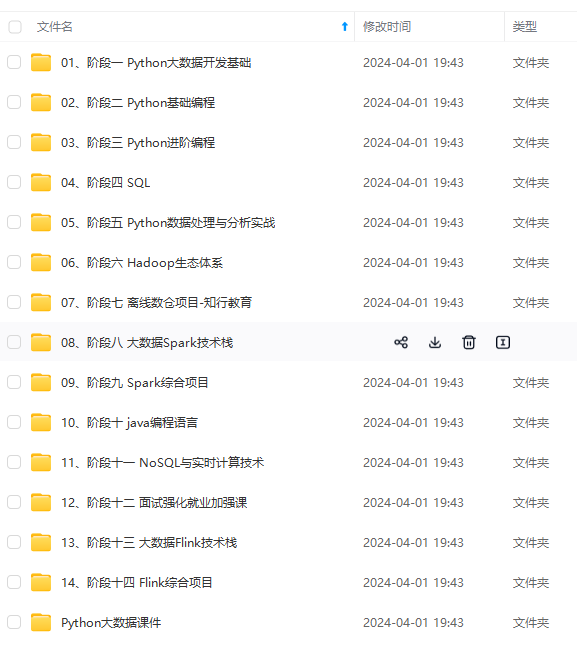
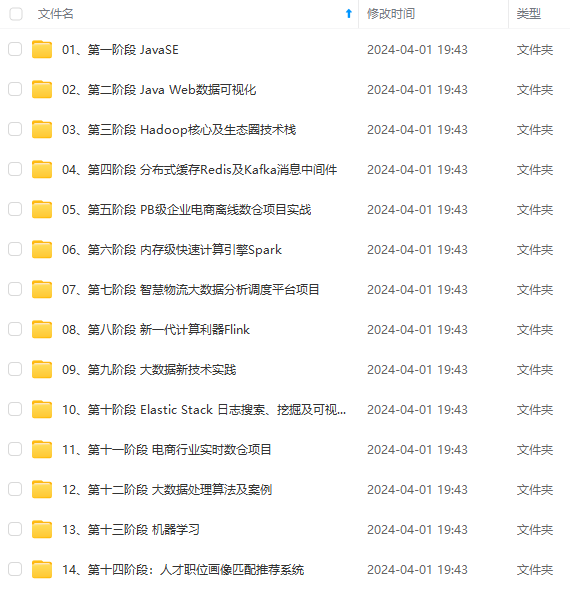
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
- 通用性:Spark支持批处理、交互式查询、实时流处理、机器学习等多种应用场景。
- 容错性:Spark使用弹性分布式数据集(RDD)进行容错,能够自动恢复数据丢失。
Spark的运行架构基于主从结构,包括一个Driver节点和多个Executor节点。Driver节点负责任务的调度和结果的收集,而Executor节点负责实际的数据处理。Spark使用DAG(有向无环图)来优化任务的执行顺序,提高了计算效率。

MapReduce和Spark都是大规模数据处理框架,但它们之间存在一些关键区别:
- 处理速度:Spark使用内存计算,比MapReduce更快。
- 易用性:Spark提供了更丰富的API和更高的编程抽象,使得开发更加简单。
- 容错性:Spark使用RDD进行容错,而MapReduce使用Hadoop的文件系统。
- 应用场景:MapReduce主要用于批处理,而Spark支持批处理、交互式查询、流处理等多种场景。
- 运行架构:MapReduce基于Hadoop YARN,而Spark有自己的运行架构,更加灵活。
- 结构化数据:结构化数据是指具有固定结构或模式的数据,通常存储在关系型数据库中。结构化数据具有明确的行和列,并且每个字段都有预定义的数据类型。
- 非结构化数据:非结构化数据是指没有固定结构或模式的数据,通常存储在文件系统、NoSQL数据库或对象中。非结构化数据包括文本、图像、音频、视频等,其格式和内容多种多样。
以下是一些常见的Linux操作命令实训练习:
-
目录操作:
ls:列出目录内容
pwd:显示当前工作目录
cd:切换目录
mkdir:创建目录
rmdir:删除空目录
cp:复制文件或目录
mv:移动或重命名文件或目录
rm:删除文件或目录 -
-
文件操作:
touch:创建空文件
cat:显示文件内容
echo:显示文本或写入文件
grep:搜索文件内容
head:显示文件开头内容
tail:显示文件末尾内容
find:查找文件或目录 + > > ***麦克阿瑟将军提醒:以上命令为最最最基础命令,将军就不再这里展示了。*** > > > -
-
系统信息:
uname:显示系统信息
df:显示磁盘空间使用情况
du:显示文件或目录的 -

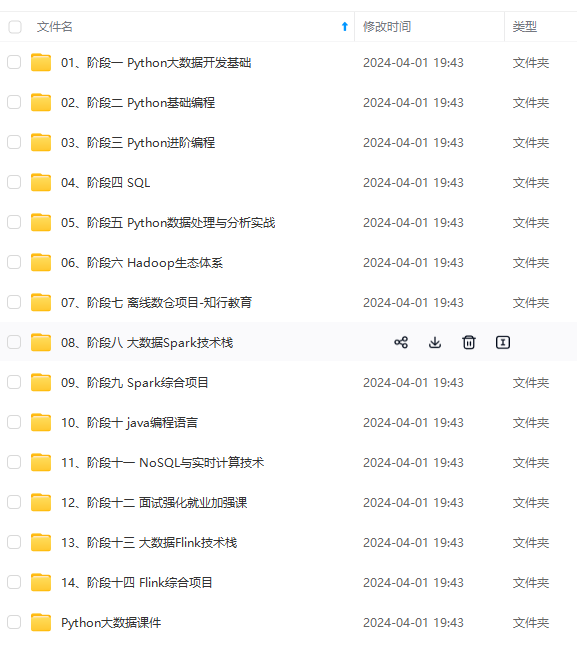
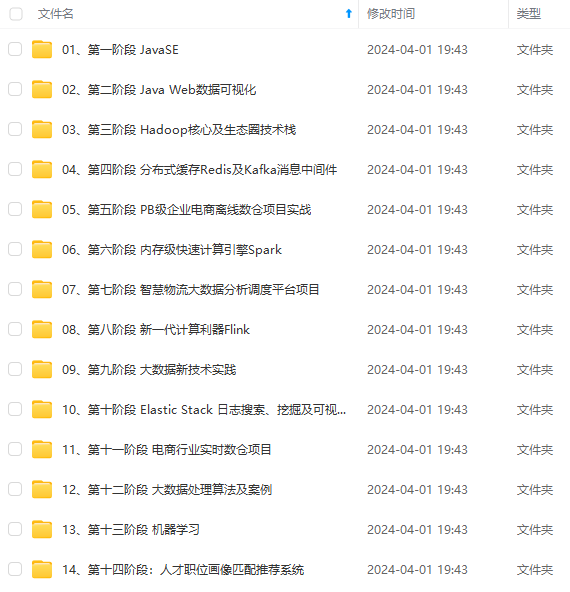
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
义、实战项目、大纲路线、讲解视频,并且后续会持续更新**


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









