







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
• 分布式资源调度框架:YARN实现集群资源管理以及作业的调度
集群规划
HDFS: NameNode和DataNodes ==> NN DN
YARN: ResourceManager,NodeManager ==> RM NM
| node1 | node2 | node3 |
|---|---|---|
| NN RN DN NM | DN NM | DN NM |
2.基础环境准备
要搭建Hadoop集群,Java环境是必不可少的,而且集群的每台机器必须具有,这一步我们进行Java的安装以及环境配置。
版本说明:Java的版本为JDK8,使用的Hadoop版本为2.7,集群的环境使用Linux Centos7,集群共三台机器,分别为node1,node2,node3。使用到的安装包也可以联系我备注相关安装包获取。更改主机名字的命令为
hostnamectl set-hostname xxxx
首先使用连接工具连接上我们的Linux,将JDK8的安装包进行上传,这里是建议创建一个文件夹,将上传的文件进行统一管理。上传好准备好的JDK安装包jdk-8u212-linux-x64.tar.gz,这里是我是放在了app目录下,上传好之后进行解压操作。命令如下
tar -xf jdk-8u212-linux-x64.tar.gz -C /app
解压好之后,将bin目录进行环境变量配置。编辑配置文件,增加下面的配置。
vi /etc/profile

添加后,在命令行输入java -version,出现如下信息,即为成功。

3.关闭防火墙
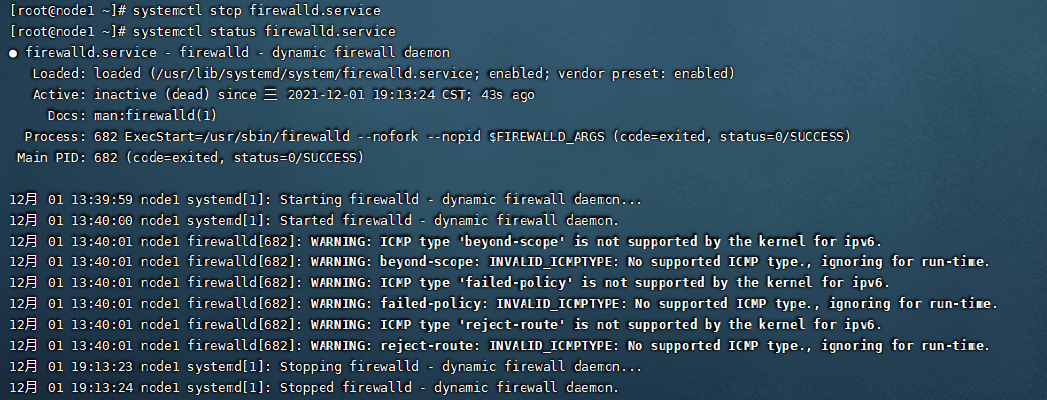
关闭防火墙是为了可以让本地的机器也可以通过Web网页进行访问我们的集群资源。这一步没有做的话,运行集群的时候可能会出现集群不可访问的状况。直接使用如下命令进行关闭。
systemctl stop firewalld.service
4.配置IP地址映射
这一步对三台主机的IP地址进行映射,可以方便我们后续的配置,同时也方便对集群进行通信,三台机器同样操作。配置如下,可以根据自己的主机IP做 对应的修改,如下图

5.添加Hadoop用户,并给与权限
在集群的搭建过程中,其实使用Root用户也是可以的,而且更加的方便。但是一般不会这样做,而是建立单独的Hadoop用户进行操作,这样也增加了集群的安全性。操作如下:
首先给三台机器增加hadoop用户,在三台机器进行同样的操作。

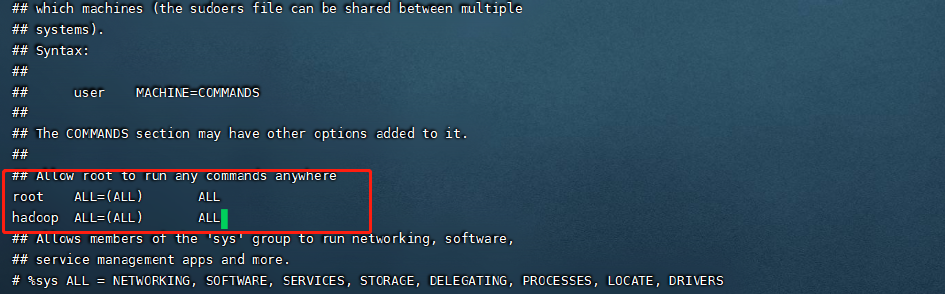
编辑配置文件,添加如下这一行,给与权限方便后面的操作
vi /etc/sudores
6.集群免密登录
免密登录是比较重要的一步,在这一步我们主要对集群的三台机器进行免密的配置。大家都知道,使用ssh命令登录到其他主机的时候,我们需要输入密码,验证通过后才可以登录。如果不进行配置的话再集群在集群启动的时候会频繁的提示密码输出,免密操作如下:
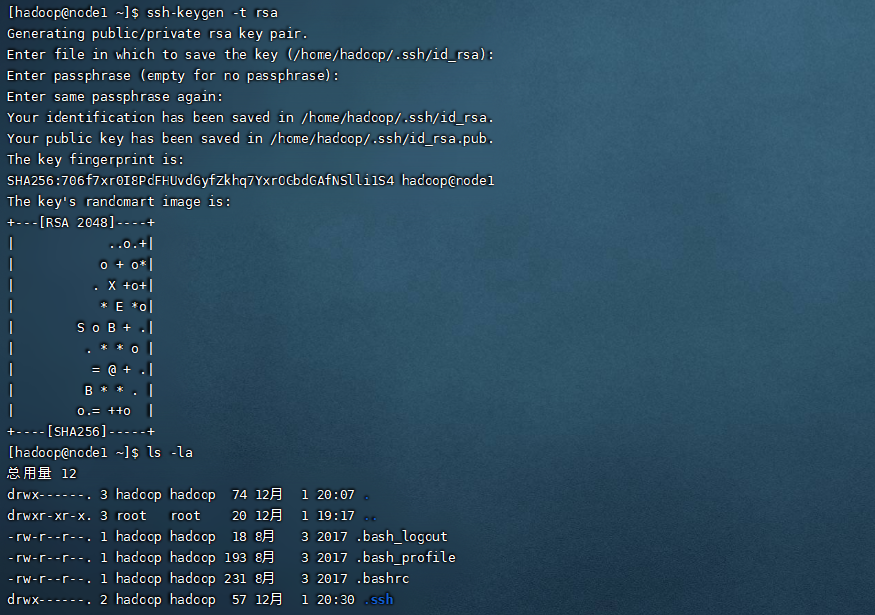
免密登录 这里要在hadoop用户下操作,运行命令 ssh-keygen -t rsa,在主节点node1上运行命令,会产生一个密钥,接下来要把这个密钥分发给其他的机器,这样就实现集群间的免密访问。
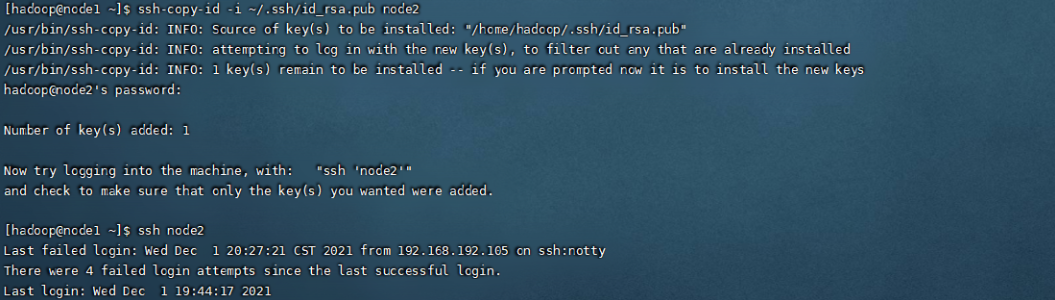
密钥的Copy,可以看到,运行之后再登录node2就不需要输入密码了
ssh-copy-id -i ~/.ssh/id_rsa.pub node1
ssh-copy-id -i ~/.ssh/id_rsa.pub node2
ssh-copy-id -i ~/.ssh/id_rsa.pub node3
7.Hadoop安装包解压与配置文件修改
我们使用的Hadoop版本为2.7,虽然现在出了3.0的版本,但博主推荐的话为了稳定还是使用2.7的版本。上传好之后进行解压,解压命令参考上面的JDK安装解压,之后把Hadoop的bin目录同样加入环境变量让系统可以识别。下面进行配置文件修改,这一步也比较重要,根据自己系统的情况,我会把对应配置文件的配置Copy供大家参考,需要修改的配置文件如下,位于hadoop安装包下面的etc下面的hadoop目录
hadoop-env.sh
export JAVA_HOME=/app/jdk1.8
core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://node1:8020</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/app/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/app/tmp/dfs/data</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
//注意这个文件可以会没有,需要拷贝文件修改。 cp mapred-site.xml.template mapred-site.xml
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
</configuration>
slaves
node1
node2
node3
到这里全部配置文件修改完成
8.集群文件分发
在node1配置好的基础环境,三台机器需要环境同步,之后将配置好的hadoop安装包进行分发给集群的其他机器。只用scp命令快捷完成。在node1上操作,之后可以在其他集群看到安装包被同步到对应的目录下
scp -r hadoop-2.7 node2:/app
scp -r hadoop-2.7 node3:/app
9.格式化NameNode
集群启动前需要格式化集群的环境,在node1上运行如下命令
最后
不知道你们用的什么环境,我一般都是用的Python3.6环境和pycharm解释器,没有软件,或者没有资料,没人解答问题,都可以免费领取(包括今天的代码),过几天我还会做个视频教程出来,有需要也可以领取~
给大家准备的学习资料包括但不限于:
Python 环境、pycharm编辑器/永久激活/翻译插件
python 零基础视频教程
Python 界面开发实战教程
Python 爬虫实战教程
Python 数据分析实战教程
python 游戏开发实战教程
Python 电子书100本
Python 学习路线规划

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









