







那么协程有哪些缺点呢?
-
第一个就是协程的应用场景有限,起码在Android的开发中应用场景有限,在Android的开发中CPU密集的场景要比I/O密集的场景多很多,而且很多情况下,I/O密集的场景可以异步处理,在CPU秘籍的场景中,协程并没有多大帮助。
-
协程并不能并发的运行多个线程,只能一次运行一个线程,这是它的优点,可以避免线程安全问题,但这也它的缺点,只能提高单个进程的cpu利用率,不能提高整体的cpu利用率。
-
在协程执行中不能有系统阻塞操作,一旦陷入系统阻塞,协程中所有的线程都会被阻塞
这三个缺点也是比较致命的缺点,所以协程的使用场景和频率不是很多,在Android开发中我们可以通过Koltin体验一下协程的使用。
Linux内核提供了clone()系统调用来创建一个可以共享地址空间的进程,我们可以用它来创建一个轻量级的进程。
int clone(int (*fn)(void * arg), void *stack, int flags, void *arg);
并且Linux的pthread库提供了pthread_create()API函数,用于创建一个线程,pthread_create的库函数调用最终执行了clone()系统调用
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg);
通过这种方式,一个线程绑定了一个轻量级进程。所以通过内核空间实现的线程的方式其实非常的容易,并且内核帮我们进行线程的调度和管理,并不需要我们自己实现。
我们接着再看在Android系统中,一个内核空间线程的实现原理。当我们通过Java的new Thread创建一个线程时,Thread的java对象内部会调用CreateNativeThread的native函数。
void Thread::CreateNativeThread(JNIEnv* env, jobject java_peer, size_t stack_size, bool is_daemon) {
CHECK(java_peer != nullptr);
Thread* self = static_cast<JNIEnvExt*>(env)->self;
if (VLOG_IS_ON(threads)) {
ScopedObjectAccess soa(env);
ArtField* f = jni::DecodeArtField(WellKnownClasses::java_lang_Thread_name);
ObjPtrmirror::String java_name =
f->GetObject(soa.Decodemirror::Object(java_peer))->AsString();
std::string thread_name;
//设置线程名
if (java_name != nullptr) {
thread_name = java_name->ToModifiedUtf8();
} else {
thread_name = “(Unnamed)”;
}
}
Runtime* runtime = Runtime::Current();
……
Thread* child_thread = new Thread(is_daemon);
// Use global JNI ref to hold peer live while child thread starts.
child_thread->tlsPtr_.jpeer = env->NewGlobalRef(java_peer);
stack_size = FixStackSize(stack_size);
// Thread.start is synchronized, so we know that nativePeer is 0, and know that we’re not racing to
// assign it.
env->SetLongField(java_peer, WellKnownClasses::java_lang_Thread_nativePeer,
reinterpret_cast(child_thread));
// 为线程分配JNIEnvExt,JNIEnvExt线程相关的JNI环境
std::string error_msg;
std::unique_ptr child_jni_env_ext(
JNIEnvExt::Create(child_thread, Runtime::Current()->GetJavaVM(), &error_msg));
int pthread_create_result = 0;
if (child_jni_env_ext.get() != nullptr) {
pthread_t new_pthread;
pthread_attr_t attr;
child_thread->tlsPtr_.tmp_jni_env = child_jni_env_ext.get();
CHECK_PTHREAD_CALL(pthread_attr_init, (&attr), “new thread”);
CHECK_PTHREAD_CALL(pthread_attr_setdetachstate, (&attr, PTHREAD_CREATE_DETACHED),
“PTHREAD_CREATE_DETACHED”);
CHECK_PTHREAD_CALL(pthread_attr_setstacksize, (&attr, stack_size), stack_size);
//调用pthread_create函数创建线程
pthread_create_result = pthread_create(&new_pthread,
&attr,
Thread::CreateCallback,
child_thread);
CHECK_PTHREAD_CALL(pthread_attr_destroy, (&attr), “new thread”);
if (pthread_create_result == 0) {
child_jni_env_ext.release();
return;
}
}
// Either JNIEnvExt::Create or pthread_create(3) failed, so clean up.
{
MutexLock mu(self, *Locks::runtime_shutdown_lock_);
runtime->EndThreadBirth();
}
// Manually delete the global reference since Thread::Init will not have been run.
env->DeleteGlobalRef(child_thread->tlsPtr_.jpeer);
child_thread->tlsPtr_.jpeer = nullptr;
delete child_thread;
child_thread = nullptr;
// TODO: remove from thread group?
env->SetLongField(java_peer, WellKnownClasses::java_lang_Thread_nativePeer, 0);
{
std::string msg(child_jni_env_ext.get() == nullptr ?
StringPrintf(“Could not allocate JNI Env: %s”, error_msg.c_str()) :
StringPrintf(“pthread_create (%s stack) failed: %s”,
PrettySize(stack_size).c_str(), strerror(pthread_create_result)));
ScopedObjectAccess soa(env);
soa.Self()->ThrowOutOfMemoryError(msg.c_str());
}
}
CreateNativeThread函数通过调用pthread_create函数来创建线程。pthread_create的实现在Bionic目录的pthread_create对象中。Bionic是Android平台为了使用C/C++进行原生应用程序开发所有提供的POSIX标准C库,如果Bionic也有实现pthread_create兼容Android的线程创建。
/bionic/libc/bionic/pthread_create.cpp
int pthread_create(pthread_t* thread_out, pthread_attr_t const* attr,
void* (start_routine)(void), void* arg) {
ErrnoRestorer errno_restorer;
// Inform the rest of the C library that at least one thread was created.
__isthreaded = 1;
pthread_attr_t thread_attr;
if (attr == NULL) {
pthread_attr_init(&thread_attr);
} else {
thread_attr = *attr;
attr = NULL; // Prevent misuse below.
}
pthread_internal_t* thread = NULL;
void* child_stack = NULL;
int result = __allocate_thread(&thread_attr, &thread, &child_stack);
if (result != 0) {
return result;
}
// Create a lock for the thread to wait on once it starts so we can keep
// it from doing anything until after we notify the debugger about it
//
// This also provides the memory barrier we need to ensure that all
// memory accesses previously performed by this thread are visible to
// the new thread.
thread->startup_handshake_lock.init(false);
thread->startup_handshake_lock.lock();
thread->start_routine = start_routine;
thread->start_routine_arg = arg;
thread->set_cached_pid(getpid());
int flags = CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND | CLONE_THREAD | CLONE_SYSVSEM |
CLONE_SETTLS | CLONE_PARENT_SETTID | CLONE_CHILD_CLEARTID;
void* tls = reinterpret_cast<void*>(thread->tls);
#if defined(i386)
// On x86 (but not x86-64), CLONE_SETTLS takes a pointer to a struct user_desc rather than
// a pointer to the TLS itself.
user_desc tls_descriptor;
__init_user_desc(&tls_descriptor, false, tls);
tls = &tls_descriptor;
#endif
int rc = clone(__pthread_start, child_stack, flags, thread, &(thread->tid), tls, &(thread->tid));
if (rc == -1) {
int clone_errno = errno;
// We don’t have to unlock the mutex at all because clone(2) failed so there’s no child waiting to
// be unblocked, but we’re about to unmap the memory the mutex is stored in, so this serves as a
// reminder that you can’t rewrite this function to use a ScopedPthreadMutexLocker.
thread->startup_handshake_lock.unlock();
if (thread->mmap_size != 0) {
munmap(thread->attr.stack_base, thread->mmap_size);
}
__libc_format_log(ANDROID_LOG_WARN, “libc”, “pthread_create failed: clone failed: %s”, strerror(errno));
return clone_errno;
}
int init_errno = __init_thread(thread);
if (init_errno != 0) {
// Mark the thread detached and replace its start_routine with a no-op.
// Letting the thread run is the easiest way to clean up its resources.
atomic_store(&thread->join_state, THREAD_DETACHED);
__pthread_internal_add(thread);
thread->start_routine = __do_nothing;
thread->startup_handshake_lock.unlock();
return init_errno;
}
// Publish the pthread_t and unlock the mutex to let the new thread start running.
*thread_out = __pthread_internal_add(thread);
thread->startup_handshake_lock.unlock();
return 0;
}
可以看到pthread_create是通过clone的系统调用来创建线程的。
==================================================================
知道了什么是线程,也知道了线程是如何产生的,接下来了解一下线程在使用过程中遇到的安全问题,以及如何解决线程安全问题。
在使用多线程时,不可避免的会遇到线程安全问题,为什么会有线程安全问题呢?主要是这三个原因导致的。
-
原子性
-
可见性
-
顺序性
原子性
前面说过,一个线程对应了一个轻量级进程。而进程之前的切换,是内核采完全公平算法进行切换的,我们无法控制这个过程。所以一个正在运行的线程,可能随时被内核切换,变成非运行状态,一旦我们正在运行的线程发生了切换,就会导致当前线程的执行过程发生中断,这种情况下就会产生线程安全问题。
看一下这样一个简单的函数
int count;
void methodA(){
count = 0;
count = count + 1;
assert count > 1:“产生了线程安全问题”;
}
这个简单的函数在多线程并发的情况下,count就会产生线程安全问题。它再多线程中运行的流程可能如下。
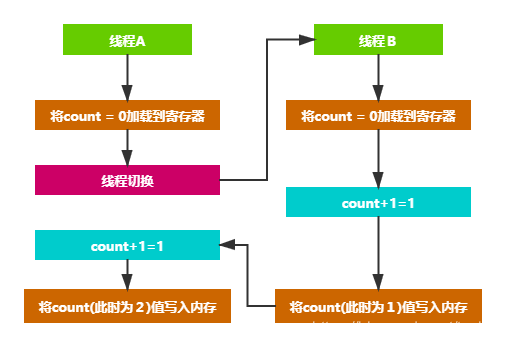
如果函数按照上图的流程执行,就会出现count的值为2的情况,和我们预期的值不一样,导致程序崩溃。
可见性
想要了解什么是可见性,我们先要了解一点计算机硬件的架构知识。硬件层面将存储体系划分为外存、主存、高速缓存和寄存器,后三者又称为内存。为什么要这样设计呢?因为CPU的运行速度是远高于内存的读写速度的,如果CPU直接读写内存,就会出现CPU要浪费很多时间在等待内存的读写上,这一点和前面提到的I/O密集型场景会让CPU造成浪费是一样的道理。为了解决这个问题,于是设计了寄存器,高速缓存和主存三种内存存储器,寄存器是CPU的工作内存,它的读写速度如果是火箭,高速缓存的读写速度就是汽车,而内存的读写速度就是人走路的速度。
再来说一说高速缓存,它也被称为Cache,是位于CPU与主内存间的一种容量较小但速度很高的存储器,一般分为L1,L2,L3三级缓存,在运行速度方面,L1最快、L2次快、L3最慢;容量大小方面,L1最小、L2较大、L3最大,如骁龙865的L2就是512KB,L3是4MB。
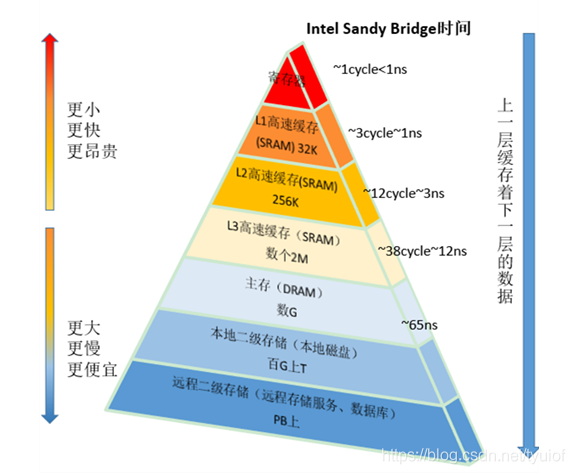
CPU在读数据会先在最快的寄存器寻找需要的数据,找不到再去L1,L2,L3最后到L4一次寻找。写数据时,也会先将数据写道寄存器,然后再同步到L1,L2或者L3中的Cache,最后再同步到内存中。在这种架构下,多核CPU就会产生数据不一致的情况。
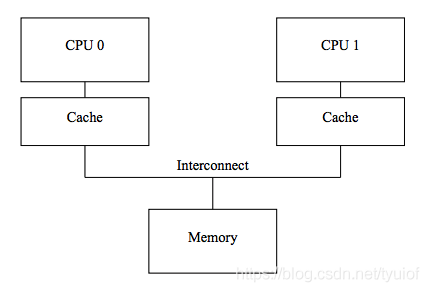
为什么会产生不一致的情况呢?以上面双核的架构运行这个函数为例。
int a = 0;
void methodA(){
a = a+1 ;
printf(a);
}
这个函数被CPU0中的线程A和CPU1中的线程B同时执行,将两个线程都执行完毕后,a的值应该是2,因为被加1了两次,但是在这种存储架构下,就会出现a的值为1的情况。
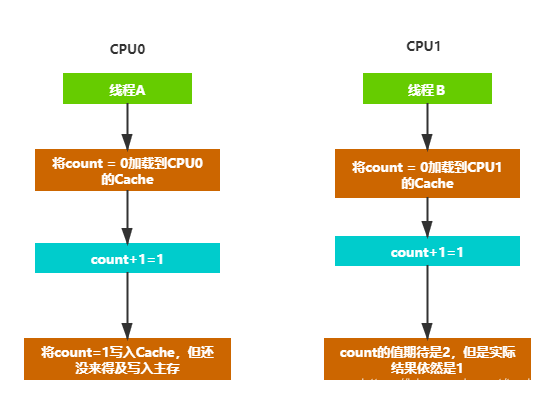
会出现这个问题的原因就是可见性,CPU0对a的操作,不能让其他的线程立刻可见,所以就出现了线程的安全性问题。
顺序性
为了性能优化,虚拟机和CPU都会对指令重排序,这样就会导致我们的程序执行的顺序实际编码的顺序不一致。
这里举一个我们用的非常频繁的例子:单例,来说明顺序性导致的线程安全问题。这是一个双重检查单例模式的实现,在大部分情况下,程序都能正常运行,一旦发生顺序问题,就可以导致程序崩溃。
public class Singleton {
private static Singleton instance;
private Singleton(){
}
public static Singleton getInstance(){
if(instance==null){
synchronized(Singleton.class){
if(instance==null){
instance = new Singleton();
}
}
}
return instance;
}
}
new Singleton的创建过程分为:分配内存,在内存中初始化Instance,然M的地址赋值给Instance这三步,如果这三步的顺序被重排,按照如下执行。
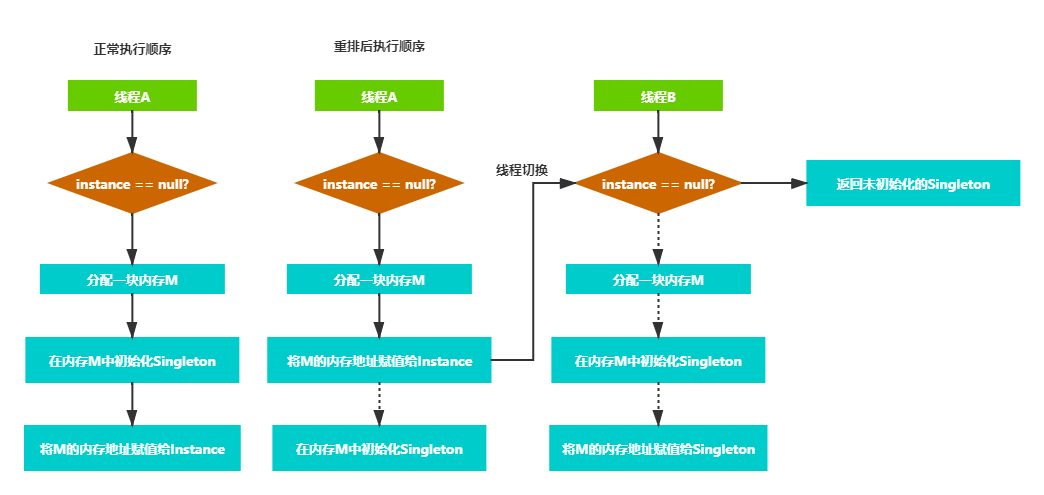
可以看到,如果先把M的地址赋值给Instance这一步先执行,此时切换了线程B,线程B会判断instance不会空,然后返回未初始化的Singlenton,导致程序崩溃。
通过前面一节的讲解,我们已经知道了产生线程安全的原因,那么如何解决线程安全呢?主要有两个解决方案
-
确保任何时候,都只能有一个线程进入共享的程序段(临界区)
-
确保各个线程之间没有共享的资源(临界资源)
互斥或者同步可以实现任何时候,都只有一个线程能进入到临界区,线程本地变量如LocalThread可以实现线程间没有临界资源。下面详细介绍一下互斥,同步,线程本地变量这三种实现线程安全的方法。
互斥
这里首先介绍一下实现互斥的几种常用的方式
-
屏蔽中断
-
软件实现的锁变量
-
软件实现的互斥算法
-
硬件指令
屏蔽中断
屏蔽中断是单核处理器系统中,实现互斥最简单的办法。某个线程进入临界区后立即屏蔽所有中断,屏蔽中断后,CPU便无法进行线程的切换,没有线程的切换,也就不会导致多个线程进入临界区引起的并发问题,当这个线程离开临界区时,再将中断打开。
但是这个方案有两个明显的缺点
-
用户进程不能拥有屏蔽中断的权利,如果用户进程拥有屏蔽中断的权利,那么随便一个恶意软件无限屏蔽中断就可以让系统无响应。所以只有系统进程才能使用这种方式实现互斥。
-
在多核处理器中,屏蔽中断只能屏蔽自己线程所处的CPU,而无法屏蔽其他CPU,这种情况下即使屏蔽也中断,依然还会有其他线程能进入临界区
因为这两个明显的缺点,屏蔽中断并不是一个比较好的互斥的方式
软件实现的锁变量
软件实现的锁变量是很多新手程序员常用的实现互斥的方式。我们经常会在程序中看到通过boolean或者int类型的变量来实现if else的判断,比如当值为true时,进入if的逻辑,false时,进入else的逻辑。
在前面已经说过,原子性是产生线程安全的原因之一,但是boolean或者int这些常用的基本类型的赋值操作是不具备原子性的,所以通过软件实现的锁变量用在临界区的互斥上,依然会导致多个线程都能进入临界区产生线程安全问题。
因此,软件实现的锁变量,也不是一个比较好的互斥的方式。
软件实现的互斥算法
比较有名的互斥算法是Peterson算法,这里简单的介绍一下这个算法的实现。
int turn;
int flat[2] = {false};
void engerRegion(int threadId){
flag[threadId] = true;
turn = 1 - threadId;
while(flat[threadId] == true&& turn == (1 - threadId)){};
//临界区
……
//退出临界区
flag[threadId] = false;
}
现在有两个线程P0和P1,当P0进入到临界区之前,会将flag[0]置为true,并将标志位turn设置为1(1-线程号0),然后通过while循环判断另一个线程的flag标志是否为trueflag[1] == true以及turn变量是否等于另一个线程号turn==1,如果是的话则说明另一个线程在临界区,会进入while循环等待,如果不是,则说明另一个线程没在临界区,可以进入临界区。
为什么这个算法能实现互斥呢?有这两种场景
- P0和P1同时都在执行这段代码
在这种情况下,线程P0将turn置为了1,这个时候线程P1又将turn置为了0。当线程P0进入while判断,对P0来说,这个时候flag[1-线程号]也就是flag[1] 为true,但是turn却是flase,不满足while循环的条件,所以P0会进入临界区。但是P1在while判断时,flag[0]为true,并且turn为0,满足while的条件,于是会一直循环,直到p0退出临界区。
- 只有一个线程在执行这段代码
在这种情况下,如果是P0在执行这段代码,while循环的判断中,flag[1]是false,不满足while循环的判断,于是P0会进入临界区。
可以看到,不管是同时只有一个线程在执行这段代码,还是同时两个线程都执行这段代码,都能保证只有一个线程进入临界区。这个时候会有人问,如果是三个线程,四个线程或者多个线程的情况呢?这就是Peterson算法的缺点,它只能满足两个线程的互斥,但是基于Peterson衍生出来的Filger算法能满足多个线程的互斥,Filger主要是将flag和turn进行了扩展,思路都是一样的,这里就不详讲了,它的实现如下。
// initialization
level[N] = { -1 }; // current level of processes 0…N-1
waiting[N-1] = { -1 }; // the waiting process of each level 0…N-2
// code for process #i
for(l = 0; l < N-1; ++l) {
level[i] = l;
waiting[l] = i;
while(waiting[l] == i &&
(there exists k ≠ i, such that level[k] ≥ l)) {
// busy wait
}
}
// critical section
level[i] = -1; // exit section
通过互斥算法可以实现互斥,但是软件实现的互斥在性能上不太好,特别是在大量的并发情况下,通过while循环遍历的方式,性能会更差。所以互斥算法也不是比较好的互斥的方式。
硬件指令
屏蔽中断,软件锁变量和互斥算法都不是很好的实现互斥的方式,那么有没有实现互斥的最好的办法呢?有,那就是硬件支持的互斥。
从早期处理器支持的:测试并设置(Test-and-Set), 获取并增加(Fetch-and-Increment),交换(Swap)。到现代处理器才开始支持的:比较并交换(Compare-and-Swap),加载链接/条件存储(Load-Linked/Store-Conditional)。这五种指令都是通过硬件支持的原子操作,通过这五种方式,我们就能比较完美的实现互斥。
硬件指令原子性的原理都是通过lock指令将内存总线锁住,以禁止其他CPU在本指令结束之前访问内存,内存总线只有一条,并且是独占的,不管多核还是单核,同一时间,只有一个CPU能占用总线。
这里详细介绍一下测试并设置(TAS)和比较并交换(CAS),加载链接/条件存储(LL/SC)**这两个硬件指令,因为这两个是用的最多的两个指令。
测试并设置(TAS)
TAS指令会向某个内存地址(这个内存地址只有1bit,所以值非0即1)写入值1,并且返回这块内存地址存的原始值。TAS指令是原子的,这是由实现TAS指令的硬件保证的(这里的硬件可以是CPU,也可以是实现了TAS的其他硬件),我们看一下如何通过TAS实现自旋锁。
byte lock = 0 //shared state
void engerRegion(){
//获取锁
while(test_and_set(lock)==1){}
// 临界区代码
……
//释放锁
lock = 0 //release
}
在while循环中,通过test_and_set对lock进行操作,如果lock返回值为1,说明已经有其他线程将lock的值设置成了1,所以会在while中不断的循环,知道其他线程退出临界区,将lock设置成了1,这次,这个线程就可以进入临界区,并且重新将lock设置成了1。通过空转循环检测的锁被称为自旋锁,TAS是Linux系统中实现自旋锁最常用的一种方式。
但是TAS也有一些缺点
-
第一点是TAS的值非0即1,这就导致通过TAS实现的锁只有两种状态,它用来实现互斥是很合适的,但是在一些更复杂的条件判断中,仅仅只通过互斥可能会满足不了要求。
-
第二个涉及到了TAS保证可见性的处理,当TAS每次将lock写为1时,都需要发送缓存一致性协议(缓存一致性协议后面会详细讲)通知其他Cache lock值已经失效,而发送协议需要占用总线流量,所以TAS在总线流量占用是比较大的。
比较并交换(CAS)
CAS指通过将某个内存中的值与指定数据进行比较,当数值一样时将内存中的数据替换为新的值,CAS的逻辑比TAS要复杂很多,所以这里通过代码模拟CAS的过程。
boolean cas(long lock, long oldValue, long newValue)
{
if(lock != oldValue)
return false;
lock = newValue;
return true;
}
lock是我们的锁,当他和和指定的值oldValue不等时,CAS返回失败;如果相等时,CAS成功,将lock设置成新值。虽然这里面的步骤很多,但是整个流程由硬件支持的原子性操作。CAS的汇编指令是cmpxchg,它的实现如下。
#define LOCK_IF_MP(mp) __asm cmp mp, 0 \
__asm je L0 \
__asm _emit 0xF0 \
__asm L0:
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) {
// alternative for InterlockedCompareExchange
int mp = os::is_MP();
__asm {
mov edx, dest
mov ecx, exchange_value
mov eax, compare_value
LOCK_IF_MP(mp) // 如果是多处理器的话,则需要添加Lock锁住总线
cmpxchg dword ptr [edx], ecx
}
}
通过cmpxchg的汇编可以看到,如果是多处理器情况,会在指令添加lock前缀,lock是对原子性,可见性和顺序性的保证。
Intel的手册对lock前缀的说明如下:
-
确保对内存的读改写操作原子执行。在Pentium及Pentium之前的处理器中,带有lock前缀的指令在执行期间会锁住总线,使得其他处理器暂时无法通过总线访问内存。但这也会带来昂贵的开销。从Pentium 4,Intel Xeon及P6处理器开始,intel在原有总线锁的基础上做了一个很有意义的优化:如果要访问的内存区域(area of memory)在lock前缀指令执行期间已经在处理器内部的缓存中被锁定(即包含该内存区域的缓存行当前处于独占或以修改状态),并且该内存区域被完全包含在单个缓存行(cache line)中,那么处理器将直接执行该指令。由于在指令执行期间该缓存行会一直被锁定,其它处理器无法读/写该指令要访问的内存区域,因此能保证指令执行的原子性。这个操作过程叫做缓存锁定(cache locking),缓存锁定将大大降低lock前缀指令的执行开销,但是当多处理器之间的竞争程度很高或者指令访问的内存地址未对齐时,仍然会锁住总线。
-
禁止该指令与之前和之后的读和写指令重排序。
-
把值数据刷新到内存中。
cmpxchg只在Intel的架构上才支持,ARM架构并不支持CAS,所以在Android系统上的原子操作并不是通过CAS来实现的。
我们接着看一下如何通过CAS实现一个自旋锁。
int lock = 0 //shared state
void engerRegion(){
//获取锁
while(cas(lock,0,1)){}
// 临界区代码
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数初中级Android工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则近万的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Android移动开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Android开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注:Android)

小结
有了这么多优秀的开发工具,可以做出更高质量的Android应用。
当然了,“打铁还需自身硬”,想要写出优秀的代码,最重要的一点还是自身的技术水平,不然用再好的工具也不能发挥出它的全部实力。
在这里我也分享一份大佬自己收录整理的Android学习PDF+架构视频+面试文档+源码笔记,还有高级架构技术进阶脑图、Android开发面试专题资料,高级进阶架构资料这些都是我闲暇还会反复翻阅的精品资料。在脑图中,每个知识点专题都配有相对应的实战项目,可以有效的帮助大家掌握知识点。
总之也是在这里帮助大家学习提升进阶,也节省大家在网上搜索资料的时间来学习,也可以分享给身边好友一起学习
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
收集整理了一份《2024年Android移动开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。**
[外链图片转存中…(img-KWwSxnQ5-1713624496807)]
[外链图片转存中…(img-Ge92EwZL-1713624496809)]
[外链图片转存中…(img-yNfQzzbj-1713624496810)]
[外链图片转存中…(img-hCagbNHb-1713624496811)]
[外链图片转存中…(img-TUnJWHPE-1713624496812)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Android开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注:Android)
小结
有了这么多优秀的开发工具,可以做出更高质量的Android应用。
当然了,“打铁还需自身硬”,想要写出优秀的代码,最重要的一点还是自身的技术水平,不然用再好的工具也不能发挥出它的全部实力。
在这里我也分享一份大佬自己收录整理的Android学习PDF+架构视频+面试文档+源码笔记,还有高级架构技术进阶脑图、Android开发面试专题资料,高级进阶架构资料这些都是我闲暇还会反复翻阅的精品资料。在脑图中,每个知识点专题都配有相对应的实战项目,可以有效的帮助大家掌握知识点。
总之也是在这里帮助大家学习提升进阶,也节省大家在网上搜索资料的时间来学习,也可以分享给身边好友一起学习
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









