







最近秋招发放Offer已高一段落。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
喜欢本文记得收藏、关注、点赞。更多实战和面试交流,文末加入我们
技术交流

理解 Transformer
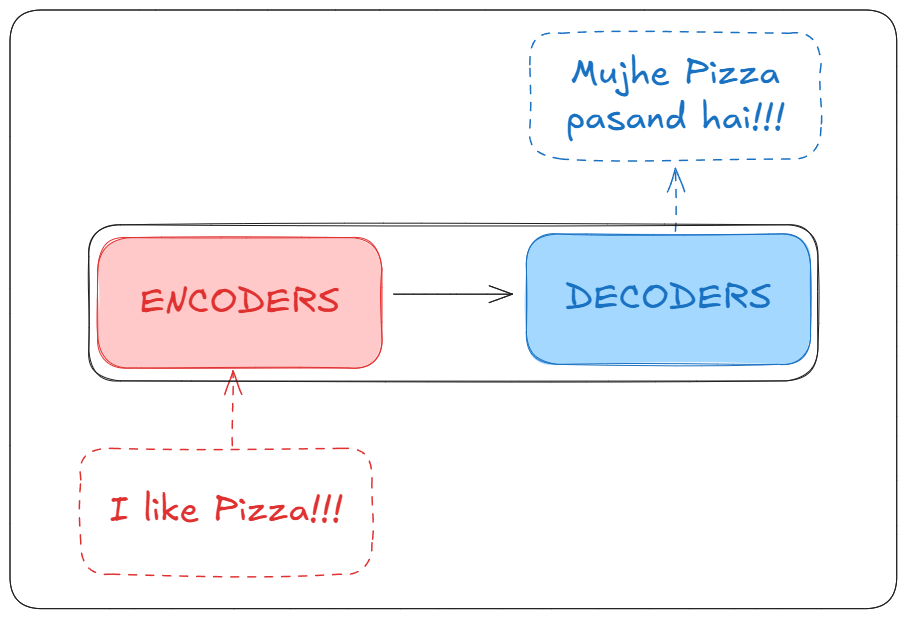
最初的 Transformer 是为机器翻译任务设计的,接下来我们也会进行同样的任务。我们将尝试将“我喜欢披萨”从英语翻译成印地语。
在此之前,简要了解一下我们要讨论的 Transformer 黑盒。我们可以看到,它由编码器(Encoder)和解码器(Decoder)组成。
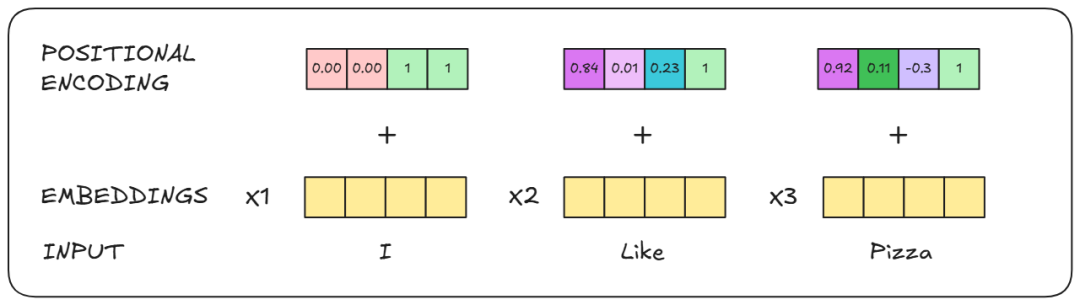
在输入编码器之前,句子“我喜欢披萨”会被分解成各自的单词*,并且每个单词会通过 embeddings 矩阵(与 Transformer 一起训练)进行嵌入处理。

然后,将位置信息添加到这些嵌入向量中。
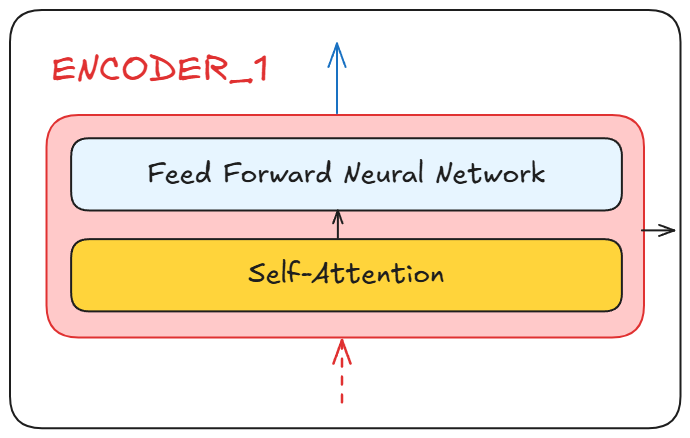
之后,这些嵌入向量会被传入编码器块,编码器的核心作用有两个:
-
应用自注意力机制(Self-Attention),理解单词与其他单词之间的关系;
-
将自注意力分数传递给前馈神经网络。
解码器块接收来自编码器的输出,将其处理后产生输出,并将其送回解码器生成下一个单词。
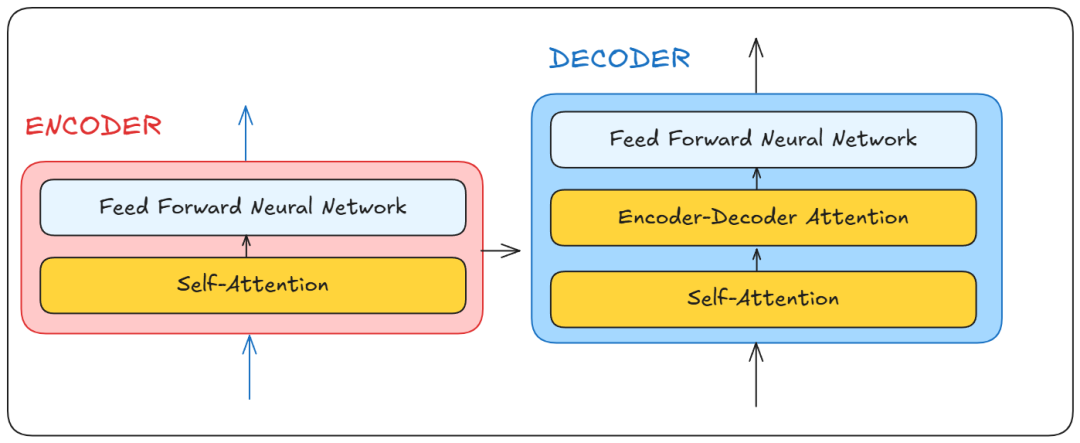
可以这样理解:编码器理解你使用的语言,假设为 X,而解码器理解另一种语言 Y。Y 作为编码器和解码器之间的共同语言,最终产生我们想要的输出。
所以,Y 充当了编码器和解码器之间的中介语言,帮助生成最终的翻译结果。
我们在这里用“单词”来简化理解,现代的大型语言模型(LLM)通常不是直接处理单词,而是处理“token”。
理解自注意力(Self-Attention)
我们都听说过著名的三元组:“Query(查询)”,“Key(键)”和“Value(值)”。我曾经很困惑这些术语是如何产生的:Q、K、V 是与字典有关吗?(或者与传统计算机科学中的映射有关?)还是受某篇论文的启发?如果是的话,他们是如何想到这些的?
首先,让我们通过直观的方式来理解这个概念。
句子(S):“Pramod loves pizza”
问题:Who loves pizza?
你可以根据这个句子提问出许多问题(查询)。每个查询会有一个特定的信息(键),这个键会给你想要的答案(值)。
查询:
Q -> Who loves pizza?
K -> pizza, Pramod, loves (实际情况下,它会包含所有的单词,并且每个单词具有不同的权重)
V -> pizza(值不是直接的答案,而是对答案的矩阵表示)
这其实是一个过于简化的示例,但它帮助我们理解:查询、键和值都可以仅通过句子本身来创建。
接下来我们来理解自注意力是如何应用的,并进一步理解它为何有效。对于接下来的解释,假设 Q、K、V 完全是矩阵,而没有其他复杂的意义。
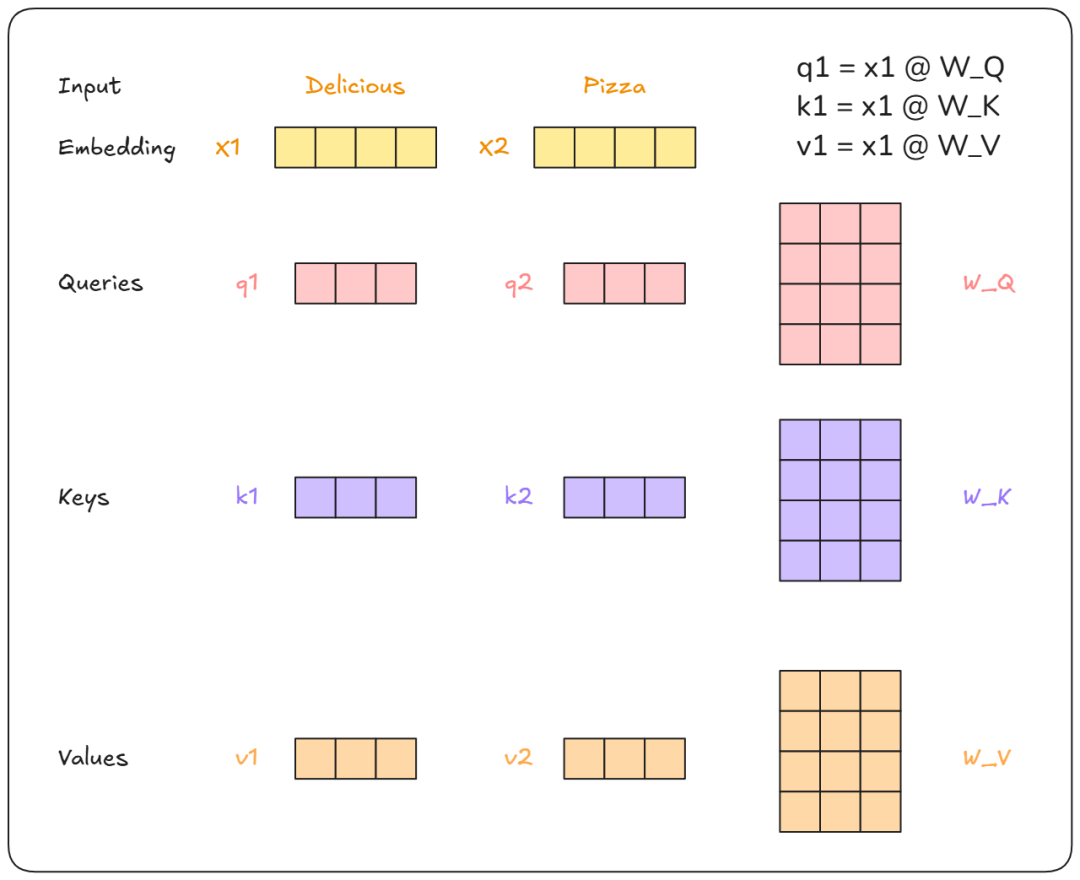
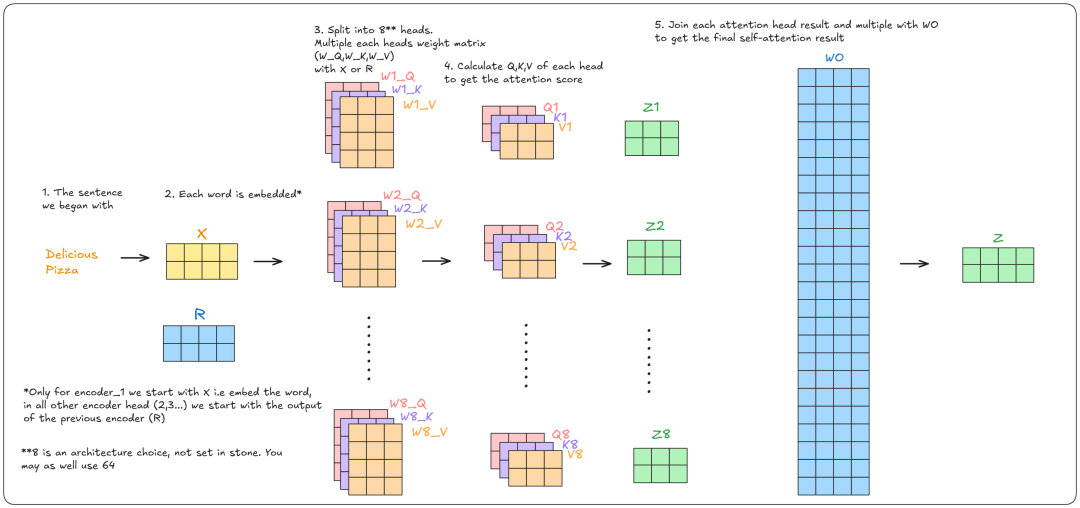
首先,句子“Delicious Pizza”会被转换成嵌入向量。然后,它会与权重矩阵 W_Q、W_K、W_V 相乘,生成 Q、K、V 向量。
这些权重 W_Q、W_K、W_V 与 Transformer 一起训练。需要注意的是,Q、K、V 的维度要小于输入向量 x1、x2。具体来说,x1、x2 是 512 维向量,而 Q、K、V 则是 64 维向量。这是为了加快计算并减少计算量的架构设计。
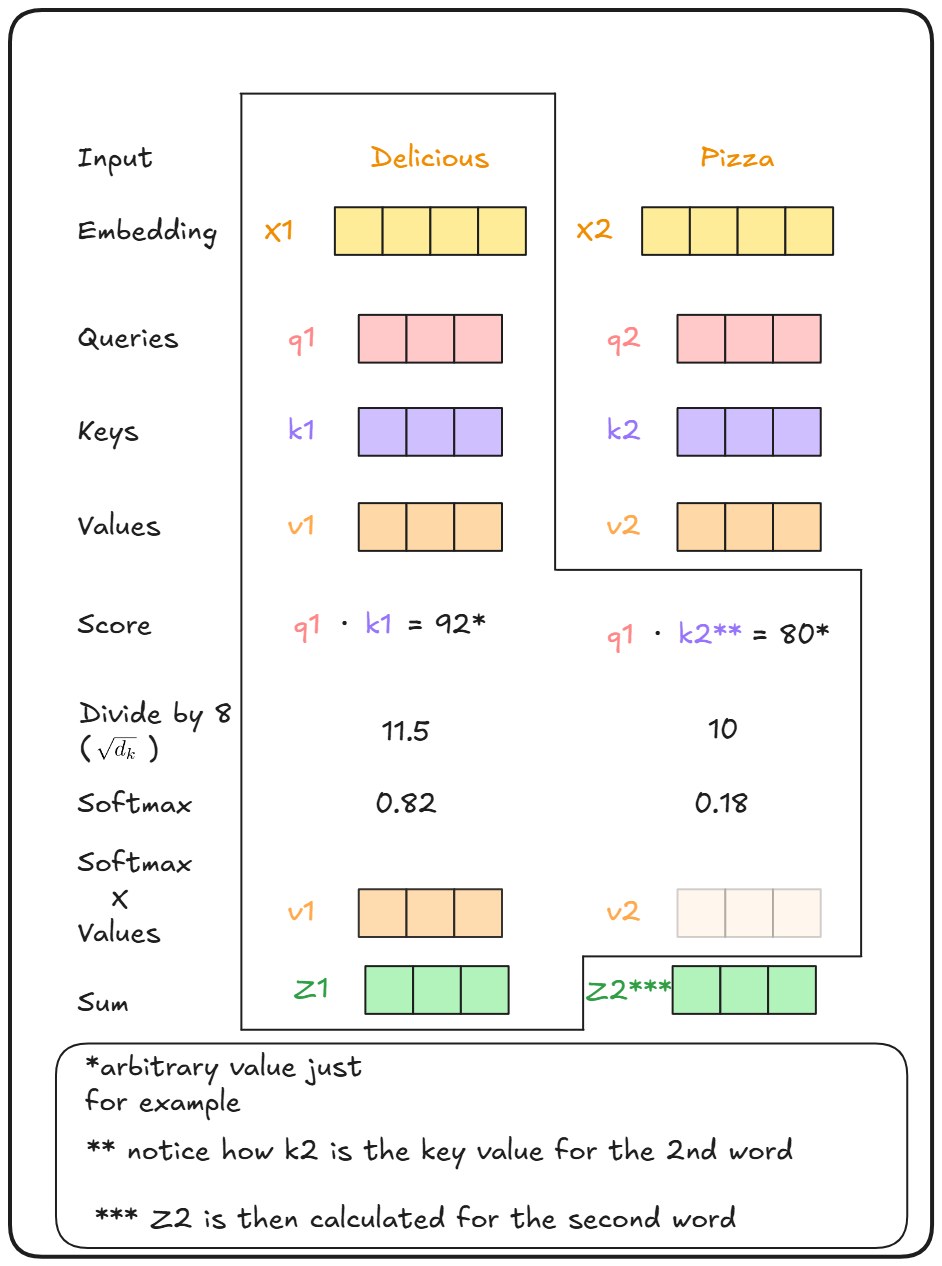
接下来,使用这些 Q、K、V 向量计算注意力分数。
计算第一个单词 “Delicious” 的注意力分数时,我们取该单词的查询向量(q1)和键向量(k1),计算它们的点积。(点积用于衡量两个向量之间的相似度)
然后,我们将结果除以键向量的维度的平方根,这是为了稳定训练。
同样的过程也会应用于第一个单词的查询向量(q1)与所有其他单词的键向量(k1、k2)的点积。
最终,使用所有的值,通过 softmax 操作得到每个分数的概率。
然后,这些分数将与每个单词的值(v1、v2)相乘,直观上来说是为了获得每个单词相对于选择的单词的重要性。对于不太重要的单词,它们的权重会被压低,比如乘以 0.001。
最后,所有的值会求和,得到最终的 Z 向量。
Transformer 的关键在于计算可以并行化,因此我们不再处理单一向量,而是处理矩阵。
实现过程保持不变:
1. 先计算 Q、K、V 矩阵。
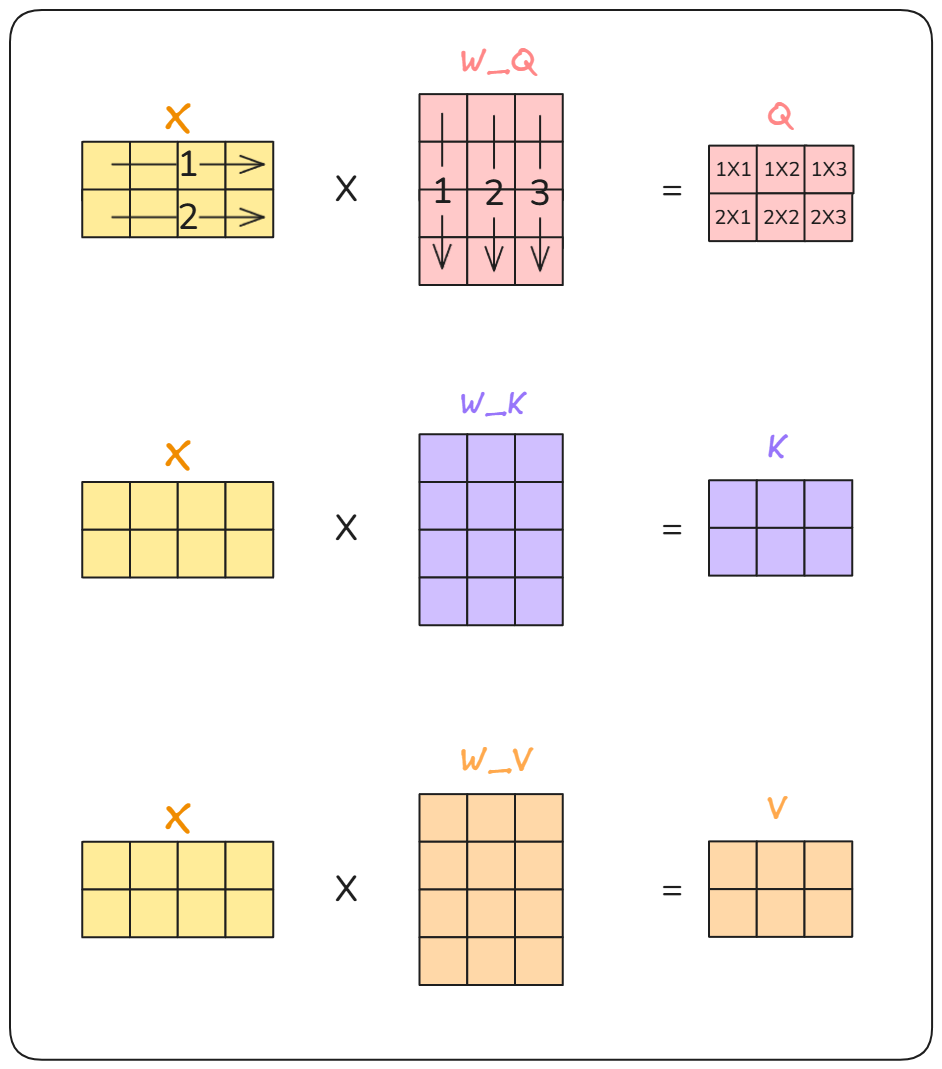
2. 然后计算注意力分数。
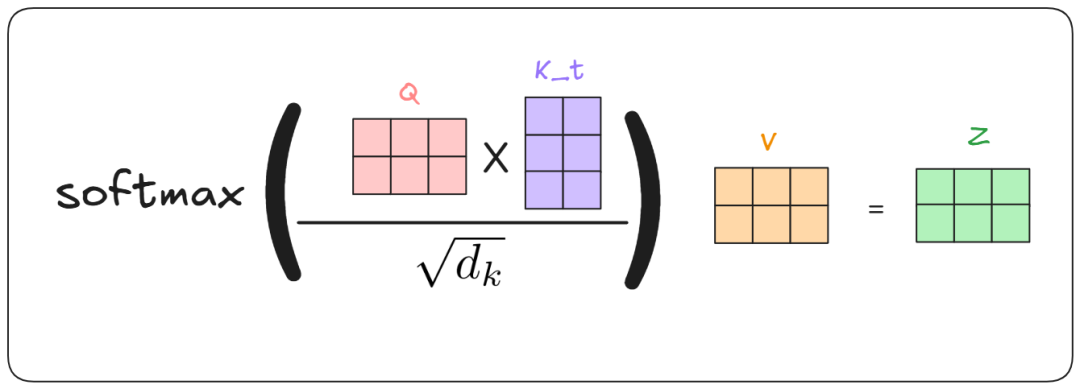
3. 对每个注意力头(Attention Head)重复以上步骤。
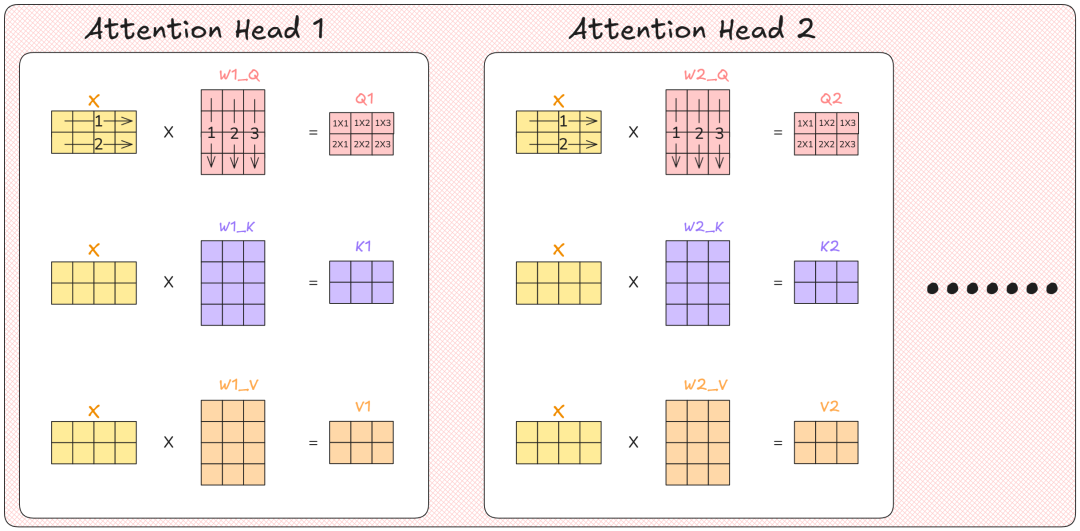
这就是每个注意力头的输出效果。
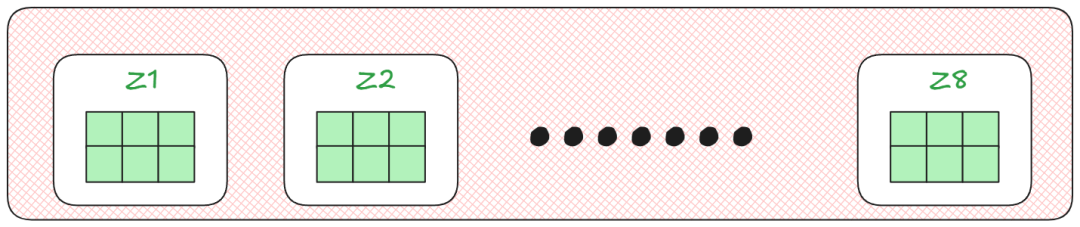
最终,将所有注意力头的输出合并,并与一个训练好的矩阵 WO(与模型一起训练) 相乘,得到最终的注意力得分。
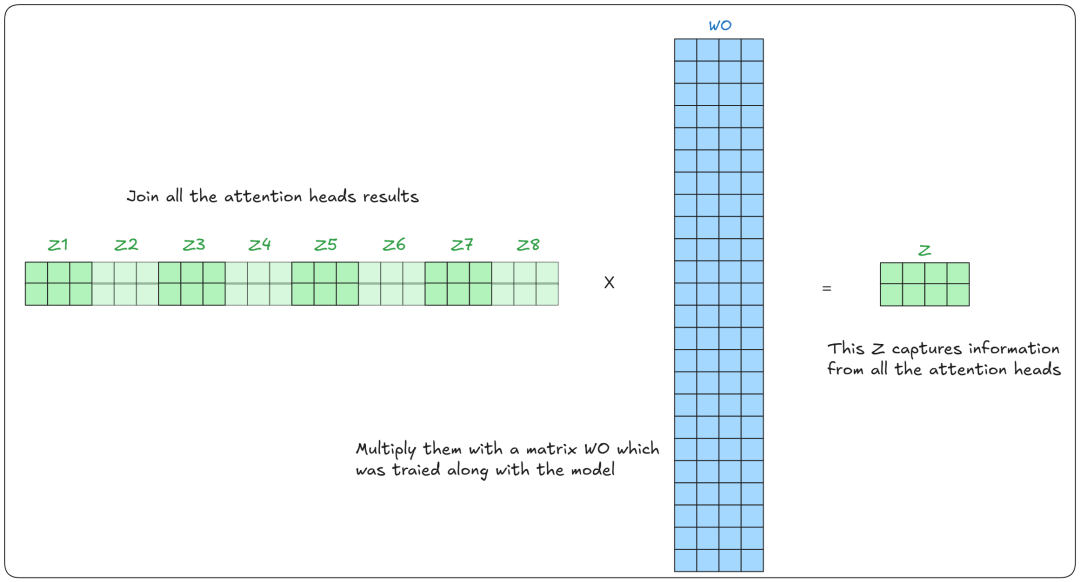
这里是对所有过程的总结
让我们现在理解一下为什么这个方法有效:
忘掉多头注意力、注意力模块和所有的术语吧。
想象你现在在 A 点,想要去 B 点,在一个巨大的城市里。你觉得只有一条路可以到达那里吗?当然不是,有成千上万条路可以到达那个地方。
但你永远无法知道哪条路是最好的,直到你尝试了其中的很多条。试得越多,越好。
因此,单一的矩阵乘法无法得到最佳的查询与键的匹配结果。你可以为每个查询生成多个查询向量,可以为每个查询生成多个键向量。这就是为什么我们需要进行多次矩阵乘法,来尽量找到最相关的键,以便回答用户提出的问题。
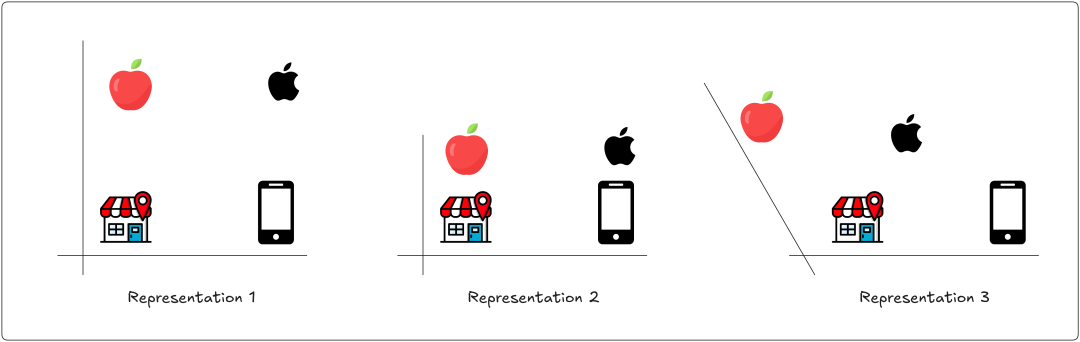
为了可视化自注意力如何创建不同的表示,我们来看一下单词 “apple”、“market”和 “cellphone” 这三个词的不同表示。
哪个表示最适合回答以下问题?
- 公司苹果做什么的?
表示2 最适合这个问题,它给出的答案是“手机”,因为“手机”是最接近的。
接下来的问题:
- 我可以在哪里买到新 iPhone?
在这种情况下,表示 3 是最佳选择,我们会得到答案“市场”。
这些都是线性变换,可以应用于任何矩阵,第三种变换叫做剪切操作。
理解位置编码(Positional Encoding)
为了理解什么是位置编码(Positional Encoding)以及为什么我们需要它,我们可以设想一下没有位置编码的场景。
首先,输入句子,例如:“Pramod likes to eat pizza with his friends”,会被拆分成各自的单词:
“Pramod”,“likes”,“to”,“eat”,“pizza”,“with”,“his”,“friends”。
接着,每个单词都会被转换成一个给定维度的嵌入向量。
现在,假如没有位置编码,模型就没有关于单词相对位置的信息。(因为所有单词都是并行处理的)
所以,句子与 “Pramod likes to eat friends with his pizza” 或其他任何单词的排列顺序并没有什么区别。
因此,我们需要位置编码(PE)来告诉模型不同单词之间的位置关系。
接下来,什么样的特点是位置编码(PE)需要具备的?
-
每个位置的唯一编码:否则它会随着句子长度的变化而不断变化。对于一个10个单词的句子,第2个位置的编码会与一个100个单词的句子的第2个位置编码不同。这会妨碍训练,因为没有可预测的模式可以遵循。
-
两个编码位置之间的线性关系:如果我知道一个单词的位置p,应该能轻松计算出另一个单词的位置p+k。这将使模型更容易学习这种模式。
-
能够推广到比训练时更长的序列:如果模型仅限于训练中使用的句子长度,它在现实世界中就无法正常工作。
-
由模型可以学习的确定性过程生成:位置编码应该是一个简单的公式或易于计算的算法,帮助模型更好地进行泛化。
-
可扩展到多个维度:不同的场景可能有不同的维度,我们希望它能在所有情况下都能工作。
整数编码
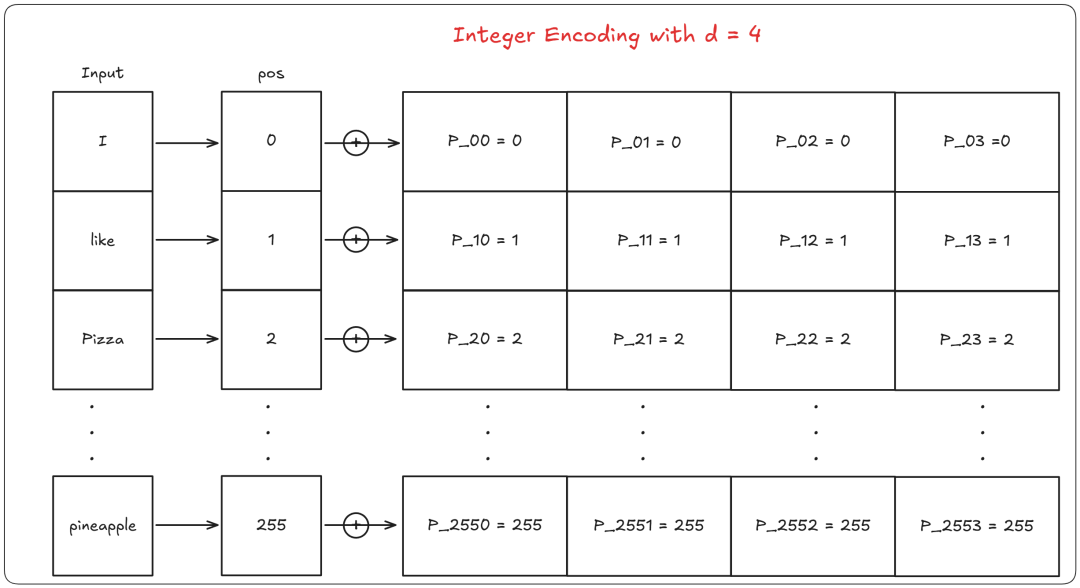
阅读以上条件后,任何人首先想到的可能是:“为什么不直接加上单词的位置呢?”这个简单的解决方案对于短句子是有效的。但是对于更长的句子,比如说一篇有2000个单词的文章,添加位置2000可能会导致梯度爆炸或梯度消失问题。
也有其他替代方案,比如对整数编码进行归一化,或者使用二进制编码,但每种方法都有其问题。
正弦编码(Sinusoidal Encoding)
一种满足我们所有条件的编码方法是使用正弦函数(Sinusoidal functions),正如论文中所做的那样。
但为什么如果正弦函数已经满足所有条件,我们还要交替使用余弦呢?
实际上,正弦函数并没有满足所有条件,但满足了大部分条件。我们对线性关系的需求没有被正弦函数满足,因此我们也需要余弦函数。下面我将展示一个简单的证明,这部分内容摘自这里。
考虑一对正弦和余弦函数序列,每一对函数都有一个频率 wi。我们的目标是找到一个线性变换矩阵M,可以通过一个固定的偏移量 k来平移这些正弦函数:
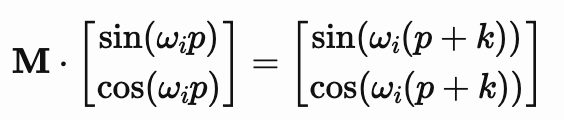
频率 wi 遵循随维度索引 i 减小的几何级数,定义为:
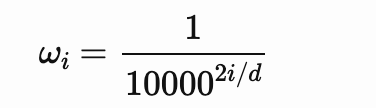
为了找到这个变换矩阵,我们可以将其表示为一个一般的 2×2 矩阵,包含未知的系数u1,u1和u2,u2。
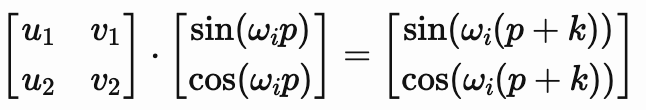
通过将三角函数加法公式应用到右边,我们可以将其展开为:
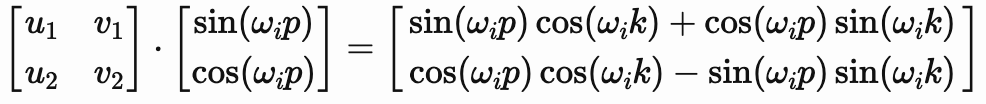
这个展开通过匹配系数给我们一个包含两个方程的系统:
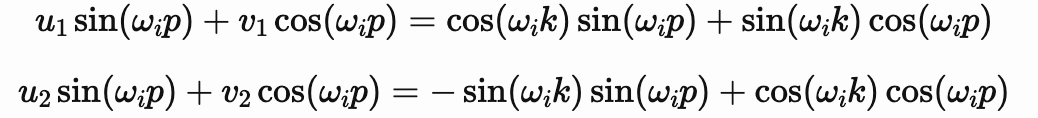
通过比较两边的 sin(ωip)和 cos(ωip)项,我们可以求解未知系数:
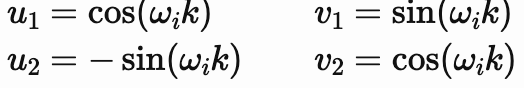
这些解决方案为我们提供了最终的变换矩阵 Mk :
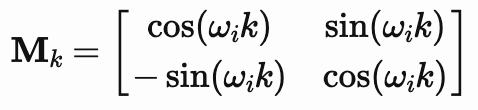
现在我们理解了什么是 PE 以及为什么使用正弦和余弦。接下来,让我们理解它是如何工作的。
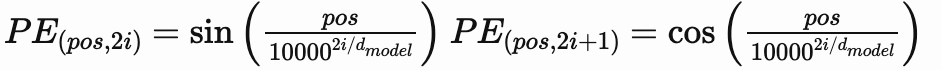
pos = 句子中单词的位置(例如,“Pramod likes pizza”中,Pramod的位置是0,likes是1,依此类推) i = 嵌入向量中第i个和(i+1)个索引的值,偶数列号使用正弦,奇数列号使用余弦(“Pramod”被转换成一个嵌入向量,具有不同的索引) d_model = 模型的维度(在我们的例子中是512) 10,000 (n) = 这是一个通过实验确定的常数
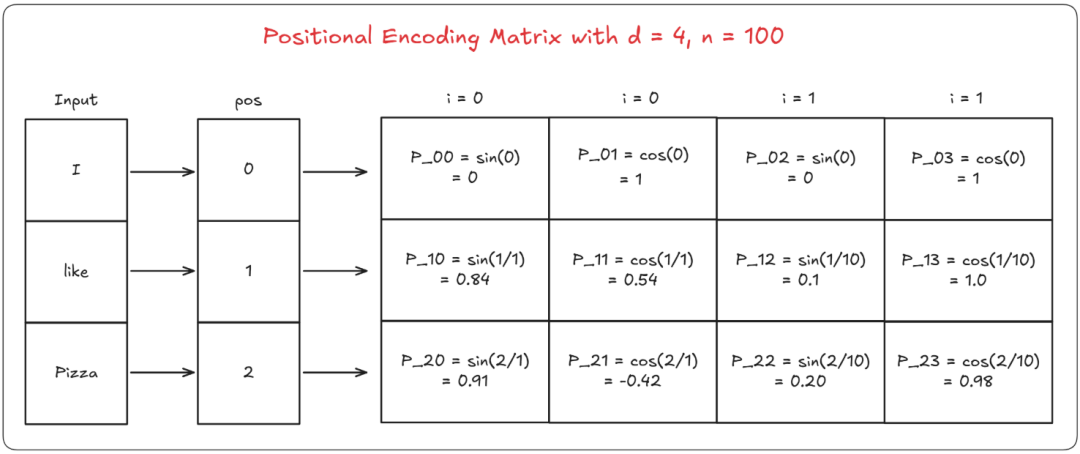
如你所见,利用这个方法,我们可以计算每个位置的PE值以及该位置的所有索引。下面是一个简单的示例,展示了它是如何完成的。
现在在上述基础上扩展,这就是该函数的样子:
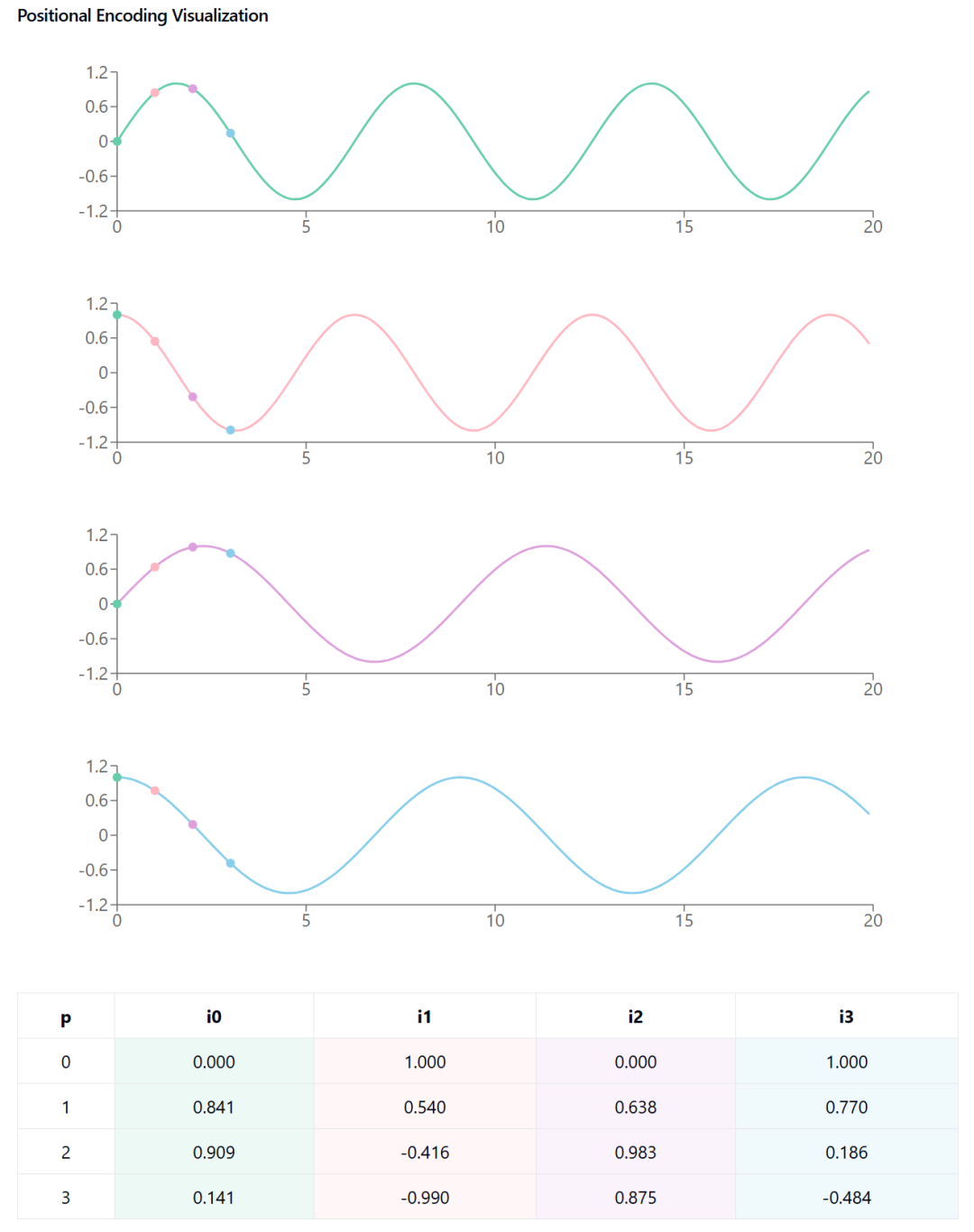
下面是当 n = 10,000,d_model = 10,000 且序列长度 = 100 时,原始的效果。代码生成如下:
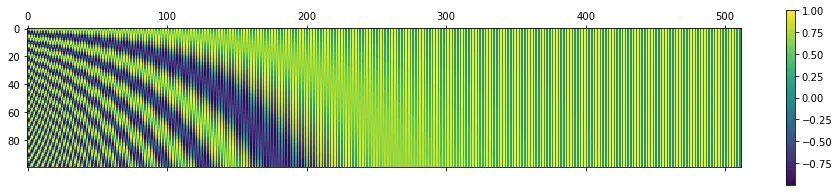
可以这样想象,y 轴上的每个索引代表一个单词,x 轴上与该索引对应的所有内容就是它的位置信息编码。
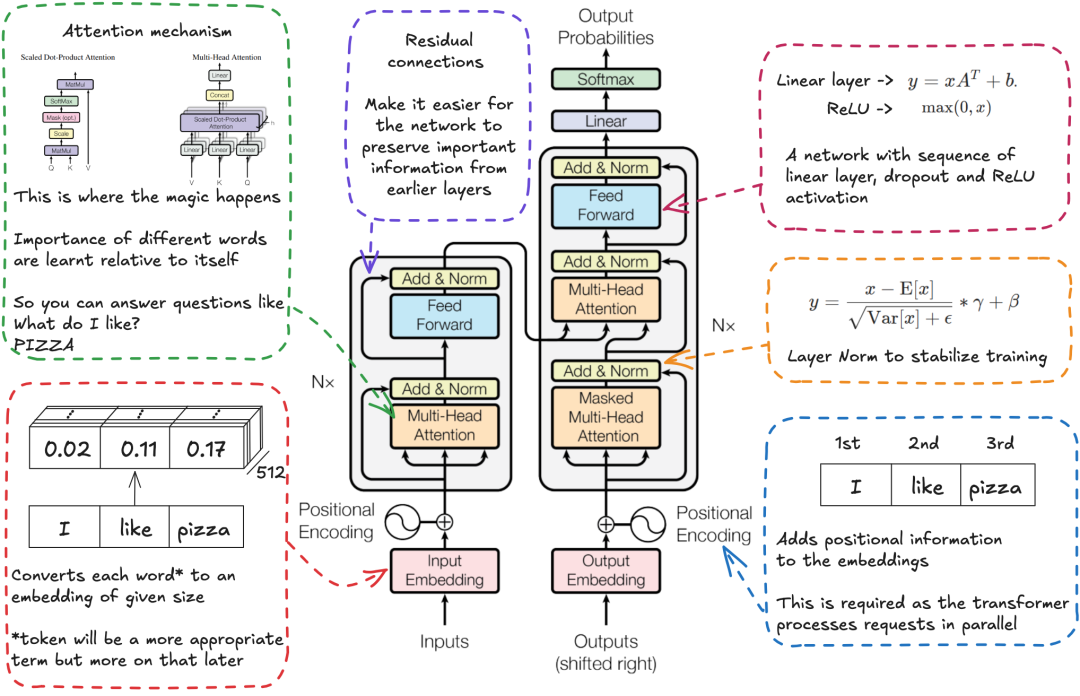
理解编码器和解码器模块
如果到目前为止你都能理解,那么接下来对你来说应该是小菜一碟了。因为这是我们将一切组合在一起的地方。
一个单独的 Transformer 可以有多个编码器模块和解码器模块。
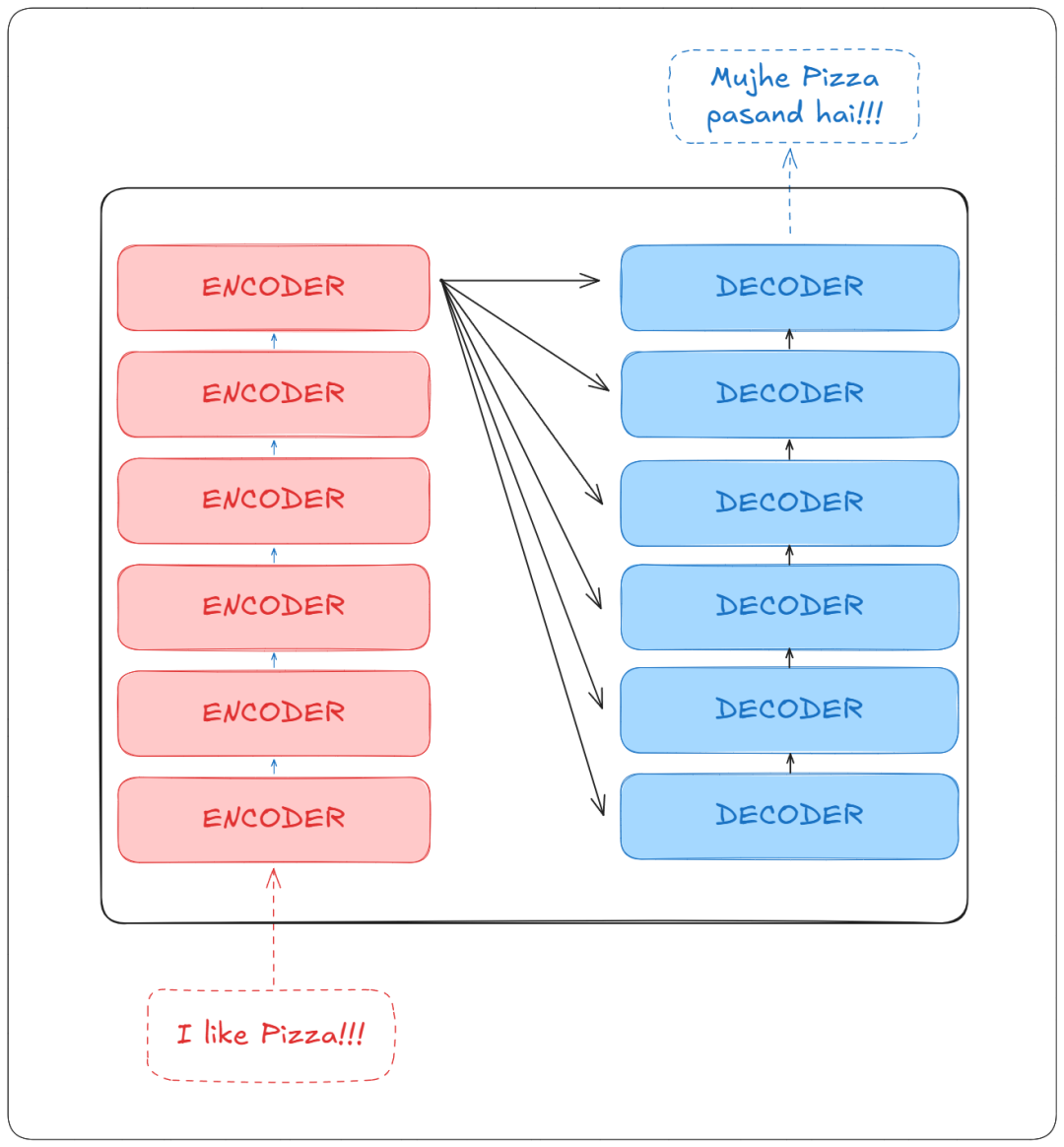
编码器
让我们先从编码器部分开始。它由多个编码器组成,每个编码器模块包含以下部分:
-
多头注意力(Multi-head Attention)
-
残差连接(Residual connection)
-
层归一化(Layer Normalization)
-
前馈网络(Feed Forward network)
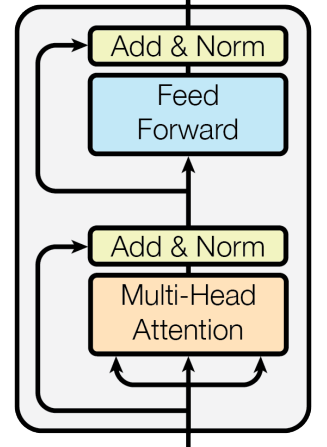
残差连接
我们已经详细讨论过多头注意力,接下来我们来聊聊剩下的三个部分。
残差连接,也叫跳跃连接,正如其名字所示,它们的工作方式是:将输入跳过一个模块,直接传递到下一个模块。
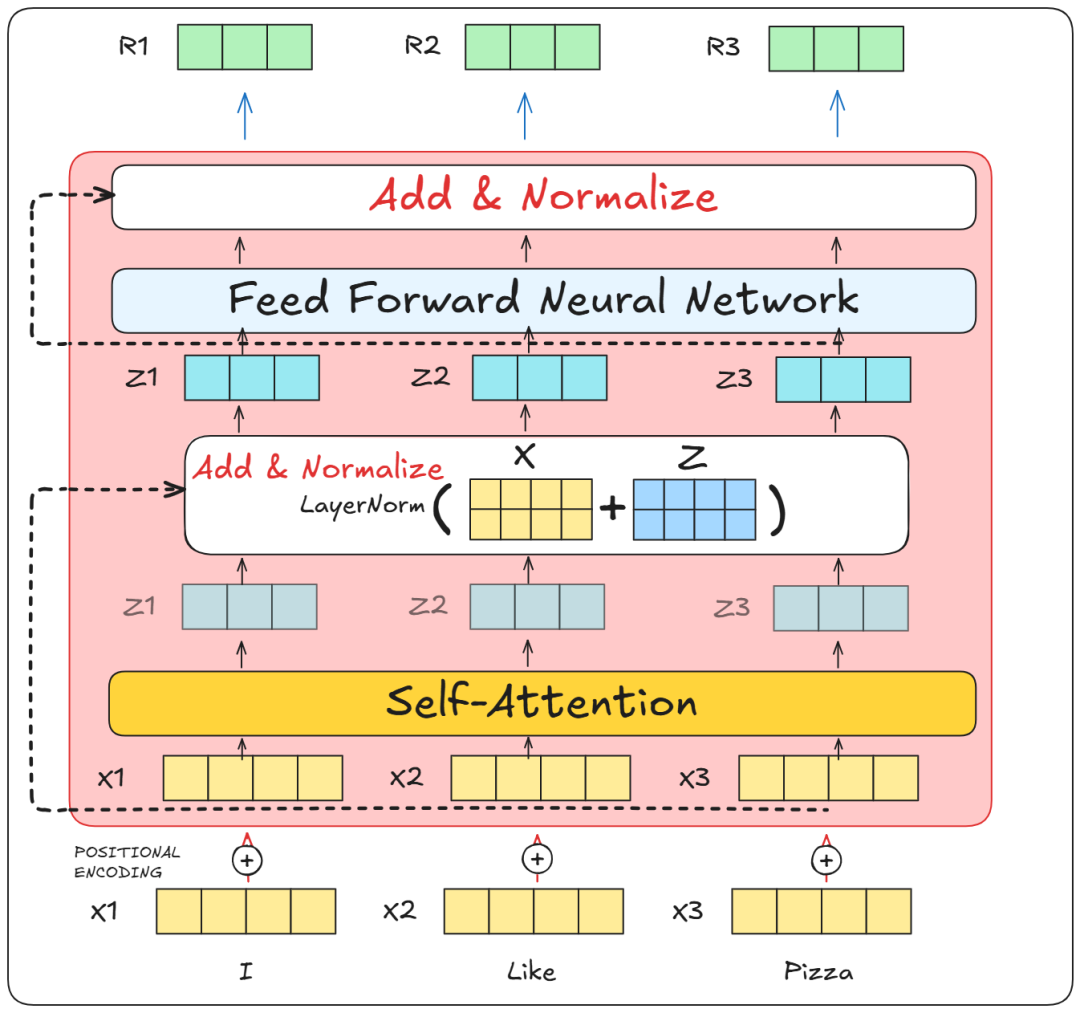
层归一化
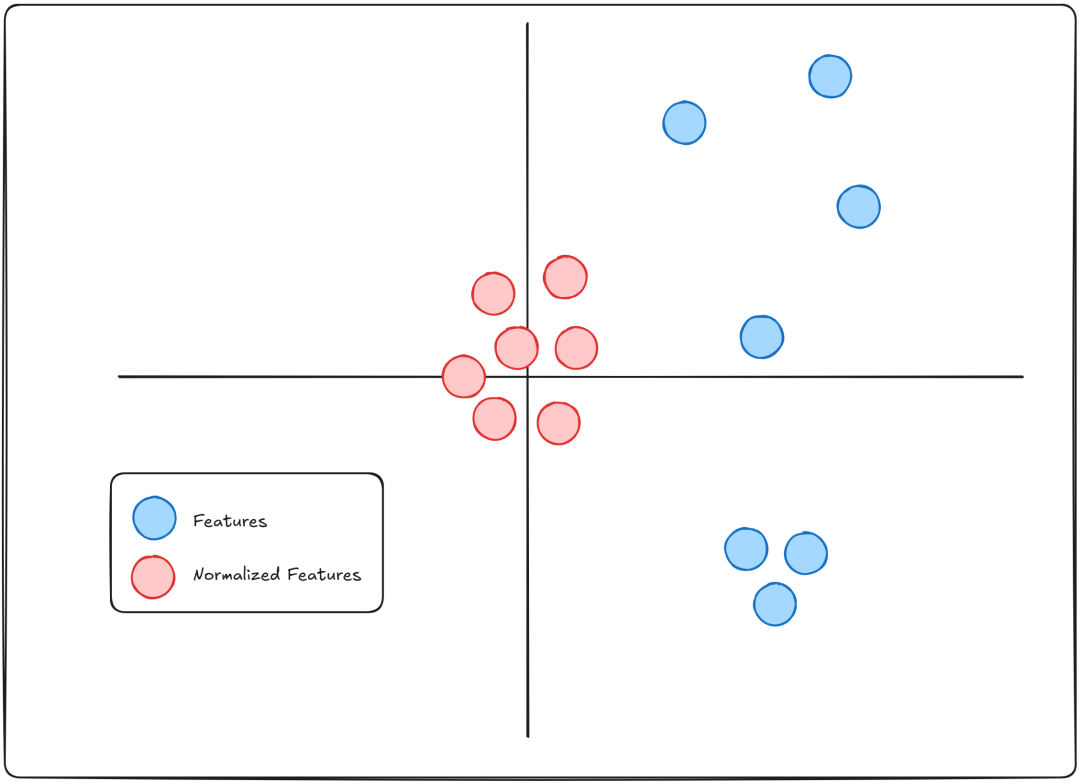
层归一化是在批归一化之后的发展。在我们讨论这两者之前,首先需要理解什么是归一化。
归一化是一种将不同特征统一到相同尺度的方法,目的是为了稳定训练过程。当模型尝试从具有极大尺度差异的特征中学习时,这会导致训练变慢并可能导致梯度爆炸。
批归一化是一种方法,它通过从后续层中减去整个批次的均值和标准差来进行归一化。
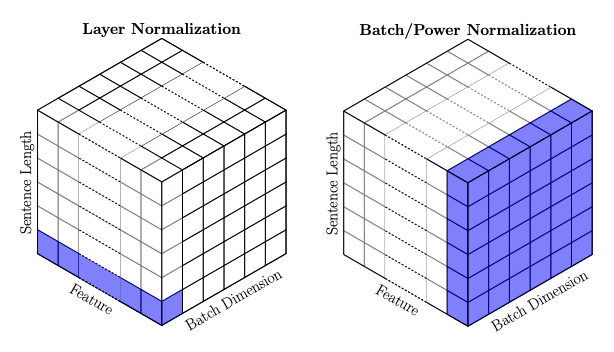
在层归一化中,焦点不是集中在整个批次上,而是集中在单个实例的所有特征上。
可以这样理解,我们从句子中取出每个单词,然后对每个单词进行归一化。
前馈网络
前馈网络(FFN)被添加进来,是为了给模型引入非线性和复杂性。虽然注意力机制在捕捉序列中不同位置之间的关系上非常有效,但它本质上仍然是线性操作(如前所述)。
FFN通过其激活函数(通常是ReLU)引入非线性,使得模型能够学习更复杂的模式和转换,这些是纯注意力机制所无法捕捉的。
可以这样想象:如果注意力机制像是一场每个人都能与其他人交谈的对话(全局交互),那么FFN就像是给每个人时间深入思考他们听到的内容,并独立地处理这些信息(局部处理)。两者对有效理解和转化输入是必不可少的。如果没有FFN,transformers将在学习复杂函数的能力上受到严重限制,基本上只能通过注意力机制进行加权平均操作。
解码器模块
编码器的输出被作为Key和Value矩阵输入到每个解码器模块中进行处理。解码器模块是自回归的。这意味着它依次输出每个结果,并将自己的输出作为输入。
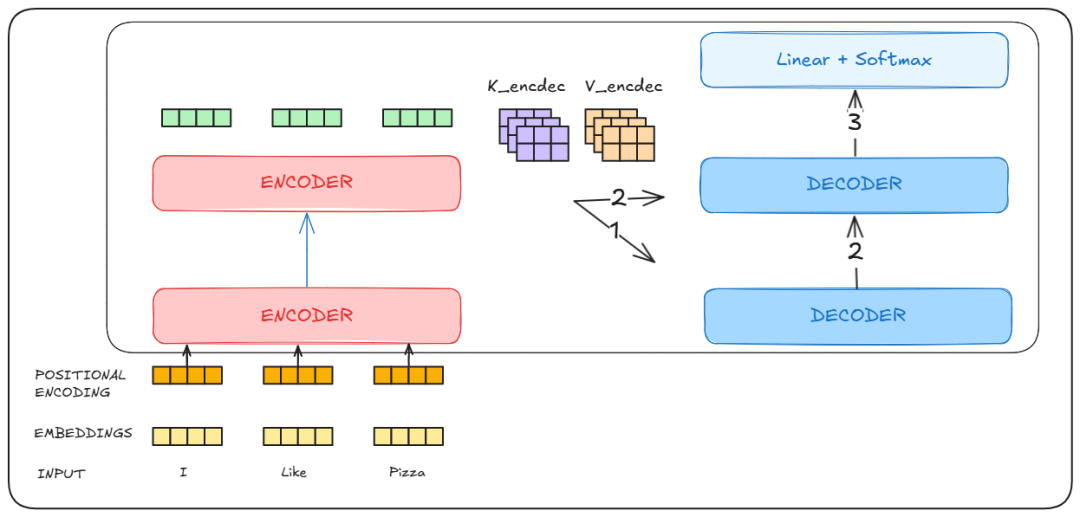
-
解码器块从编码器中获取键(Keys)和值(Values),并根据前一步的输出生成自己的查询(Queries)。
-
在第二步中,前一个解码器块的输出作为查询(Query),同时编码器的输出作为键和值。
-
这个过程会重复,直到从解码器得到输出,解码器再将该输出作为生成下一个词的输入。
-
这个过程会一直重复,直到我们得到最终的词。
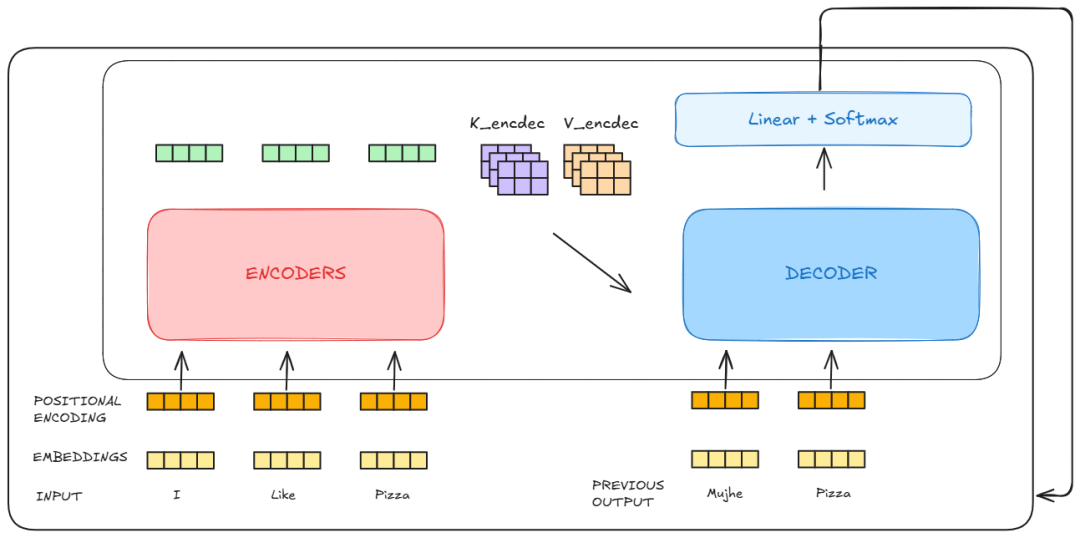
解码器块中还有一个稍微不同的地方,那就是我们应用了一个遮罩(mask),使得自注意力机制只能关注输出序列中较早的位置。
这就是你需要了解的所有高层次的概念,足以让你自己编写一个 Transformer。现在让我们看看论文和代码。
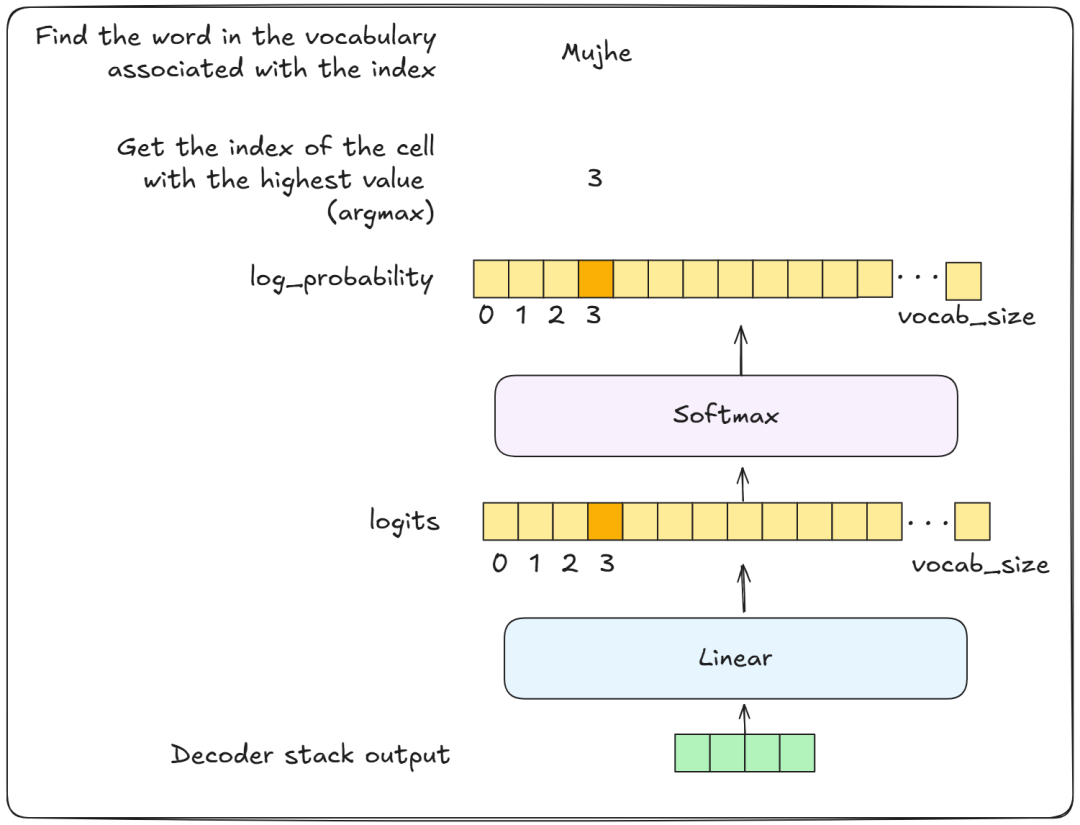
最后的线性层与 Softmax 层
解码器输出一个数字向量(通常是浮点数),然后将其传送到线性层。
线性层输出词汇表中每个单词的得分(即训练数据集中独特单词的数量)。
接着,这些得分会被传送到 Softmax 层,Softmax 层将得分转化为概率。然后,概率最高的单词将被输出。(通常是这种情况,有时我们也可以设置为输出第二高概率的单词,或者第三高的单词,以此类推。)
编写 Transformer
摘要与介绍
这一部分让你了解论文的内容和为什么要写这篇论文。
有些概念可以帮助你学习新的内容,比如 RNN、卷积神经网络和 BLEU。
另外,了解 Transformer 最初是为了文本到文本的翻译(即从一种语言翻译成另一种语言)而创建的也很重要。
因此,Transformer 包含了编码器和解码器部分。它们之间传递信息,这就是所谓的“交叉注意力”(稍后会详细介绍自注意力和交叉注意力的区别)。
背景
这一部分通常讲述之前在该领域做的工作、已知的问题以及人们用来解决这些问题的方法。我们需要理解的一个重要点是:
“跟踪远程信息”。 Transformer 有许多令人惊叹的优点,但其中一个关键优势就是它们能够记住远程的关系。
像 RNN 和 LSTM 这样的解决方案在句子变长时会丢失上下文的意义。但 Transformer 不会遇到这个问题。(但有一个问题——希望你在阅读时已经解决了,就是上下文窗口长度。它决定了 Transformer 能够看到多少信息。)
模型架构
这一部分是我们一直在等待的。我会稍微偏离论文,因为我发现跟随数据更容易一些。如果你阅读了论文,每个词都应该能让你理解。
首先从多头注意力(Multi-Head Attention)开始,然后是前馈网络(Feed Forward Network),接着是位置编码(Positional Encoding)。利用这些,我们将完成编码器层。接下来,我们将进入解码器层,然后编写编码器和解码器块,最后编写整个 Transformer 的训练循环,最终使用真实世界的数据进行训练。
必要的导入
import math
import torch
import torch.nn as nn
from torch.nn.functional import softmax
多头注意力(Multi-Head Attention)
到现在为止,你应该对注意力机制有了很好的理解,那么我们首先从编写缩放点积注意力(scaled dot-product attention)开始,因为多头注意力(MHA)实际上就是多个缩放点积注意力堆叠在一起。参考部分是 3.2.1 节 缩放点积注意力。
# try to finish this function on your own
def scaled_dot_product_attention(query, key, value, mask=None):
"""
Args:
query: (batch_size, num_heads, seq_len_q, d_k)
key: (batch_size, num_heads, seq_len_k, d_k)
value: (batch_size, num_heads, seq_len_v, d_v)
mask: Optional mask to prevent attention to certain positions
"""
# get the size of d_k using the query or the key
# calculate the attention score using the formula given. Be vary of the dimension of Q and K. And what you need to transpose to achieve the desired results.
#YOUR CODE HERE
# hint 1: batch_size and num_heads should not change
# hint 2: nXm @ mXn -> nXn, but you cannot do nXm @ nXm, the right dimension of the left matrix should match the left dimension of the right matrix. The easy way I visualize it is as, who face each other must be same
# add inf is a mask is given, This is used for the decoder layer. You can use help for this if you want to. I did!!
#YOUR CODE HERE
# get the attention weights by taking a softmax on the scores, again be wary of the dimensions. You do not want to take softmax of batch_size or num_heads. Only of the values. How can you do that?
#YOUR CODE HERE
# return the attention by multiplying the attention weights with the Value (V)
#YOUR CODE HERE
张量大小
矩阵乘法
遮罩填充
# my implementation
def scaled_dot_product_attention(query, key, value, mask=None):
"""
Args:
query: (batch_size, num_heads, seq_len_q, d_k)
key: (batch_size, num_heads, seq_len_k, d_k)
value: (batch_size, num_heads, seq_len_v, d_v)
mask: Optional mask to prevent attention to certain positions
"""
# Shape checks
assert query.dim() == 4, f"Query should be 4-dim but got {query.dim()}-dim"
assert key.size(-1) == query.size(-1), "Key and query depth must be equal"
assert key.size(-2) == value.size(-2), "Key and value sequence length must be equal"
d_k = query.size(-1)
# Attention scores
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
attention_weights = softmax(scores, dim=-1)
return torch.matmul(attention_weights, value)
利用这个,我们来完成多头注意力(MHA)
class MultiHeadAttention(nn.Module):
#Let me write the initializer just for this class, so you get an idea of how it needs to be done
def __init__(self, d_model, num_heads):
super().__init__()
assert d_model % num_heads == 0, "d_model must be divisible by num_heads" #think why?
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads # Note: use integer division //
# Create the learnable projection matrices
self.W_q = nn.Linear(d_model, d_model) #think why we are doing from d_model -> d_model
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
@staticmethod
def scaled_dot_product_attention(query, key, value, mask=None):
#YOUR IMPLEMENTATION HERE
def forward(self, query, key, value, mask=None):
#get batch_size and sequence length
#YOUR CODE HERE
# 1. Linear projections
#YOUR CODE HERE
# 2. Split into heads
#YOUR CODE HERE
# 3. Apply attention
#YOUR CODE HERE
# 4. Concatenate heads
#YOUR CODE HERE
# 5. Final projection
#YOUR CODE HERE
我很难区分 view 和 transpose。这两个链接应该能帮助你:什么时候使用 view, transpose 和 permute 以及 view 和 transpose 的区别。Contiguous 和 view 的关系仍然让我困惑。直到我读了这两篇:Pytorch 内部 和 连续与非连续张量。
#my implementation
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads # Note: use integer division //
# Create the learnable projection matrices
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
@staticmethod
def scaled_dot_product_attention(query, key, value, mask=None):
"""
Args:
query: (batch_size, num_heads, seq_len_q, d_k)
key: (batch_size, num_heads, seq_len_k, d_k)
value: (batch_size, num_heads, seq_len_v, d_v)
mask: Optional mask to prevent attention to certain positions
"""
# Shape checks
assert query.dim() == 4, f"Query should be 4-dim but got {query.dim()}-dim"
assert key.size(-1) == query.size(-1), "Key and query depth must be equal"
assert key.size(-2) == value.size(-2), "Key and value sequence length must be equal"
d_k = query.size(-1)
# Attention scores
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
attention_weights = softmax(scores, dim=-1)
return torch.matmul(attention_weights, value)
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
seq_len = query.size(1)
# 1. Linear projections
Q = self.W_q(query) # (batch_size, seq_len, d_model)
K = self.W_k(key)
V = self.W_v(value)
# 2. Split into heads
Q = Q.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
K = K.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
V = V.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
# 3. Apply attention
output = self.scaled_dot_product_attention(Q, K, V, mask)
# 4. Concatenate heads
output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, self.d_model)
# 5. Final projection
return self.W_o(output)
前馈网络
另一种描述方式是,将其视为两个卷积核大小为 1 的卷积层。输入和输出的维度为 dmodel = 512,中间层的维度为 df f = 2048。
class FeedForwardNetwork(nn.Module):
"""Position-wise Feed-Forward Network
Args:
d_model: input/output dimension
d_ff: hidden dimension
dropout: dropout rate (default=0.1)
"""
def __init__(self, d_model, d_ff, dropout=0.1):
super().__init__()
#create a sequential ff model as mentioned in section 3.3
#YOUR CODE HERE
def forward(self, x):
"""
Args:
x: Input tensor of shape (batch_size, seq_len, d_model)
Returns:
Output tensor of shape (batch_size, seq_len, d_model)
"""
#YOUR CODE HERE
-
Dropout
-
Where to put Dropout
-
ReLU
#my implementation
class FeedForwardNetwork(nn.Module):
"""Position-wise Feed-Forward Network
Args:
d_model: input/output dimension
d_ff: hidden dimension
dropout: dropout rate (default=0.1)
"""
def __init__(self, d_model, d_ff, dropout=0.1):
super().__init__()
self.model = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(d_ff, d_model),
nn.Dropout(dropout)
)
def forward(self, x):
"""
Args:
x: Input tensor of shape (batch_size, seq_len, d_model)
Returns:
Output tensor of shape (batch_size, seq_len, d_model)
"""
return self.model(x)
位置编码
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_length=5000):
super().__init__()
# Create matrix of shape (max_seq_length, d_model)
#YOUR CODE HERE
# Create position vector
#YOUR CODE HERE
# Create division term
#YOUR CODE HERE
# Compute positional encodings
#YOUR CODE HERE
# Register buffer
#YOUR CODE HERE
def forward(self, x):
"""
Args:
x: Tensor shape (batch_size, seq_len, d_model)
"""
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_length=5000):
super().__init__()
# Create matrix of shape (max_seq_length, d_model)
pe = torch.zeros(max_seq_length, d_model)
# Create position vector
position = torch.arange(0, max_seq_length).unsqueeze(1) # Shape: (max_seq_length, 1)
# Create division term
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# Compute positional encodings
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# Register buffer
self.register_buffer('pe', pe.unsqueeze(0)) # Shape: (1, max_seq_length, d_model)
def forward(self, x):
"""
Args:
x: Tensor shape (batch_size, seq_len, d_model)
"""
return x + self.pe[:, :x.size(1)] # Add positional encoding up to sequence length
编码器层
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super().__init__()
# 1. Multi-head attention
#YOUR CODE HERE
# 2. Layer normalization
#YOUR CODE HERE
# 3. Feed forward
#YOUR CODE HERE
# 4. Another layer normalization
#YOUR CODE HERE
# 5. Dropout
#YOUR CODE HERE
def forward(self, x, mask=None):
"""
Args:
x: Input tensor of shape (batch_size, seq_len, d_model)
mask: Optional mask for padding
Returns:
x: Output tensor of shape (batch_size, seq_len, d_model)
"""
# 1. Multi-head attention with residual connection and layer norm
#YOUR CODE HERE
# 2. Feed forward with residual connection and layer norm
#YOUR CODE HERE
return x
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super().__init__()
# 1. Multi-head attention
self.mha = MultiHeadAttention(d_model,num_heads)
# 2. Layer normalization
self.layer_norm_1 = nn.LayerNorm(d_model)
# 3. Feed forward
self.ff = FeedForwardNetwork(d_model,d_ff)
# 4. Another layer normalization
self.layer_norm_2 = nn.LayerNorm(d_model)
# 5. Dropout
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
"""
Args:
x: Input tensor of shape (batch_size, seq_len, d_model)
mask: Optional mask for padding
Returns:
x: Output tensor of shape (batch_size, seq_len, d_model)
"""
# 1. Multi-head attention with residual connection and layer norm
# att_output = self.attention(...)
# x = x + att_output # residual connection
# x = self.norm1(x) # layer normalization
att_output = self.mha(x, x, x, mask)
x = self.dropout(x + att_output) # Apply dropout after residual
x = self.layer_norm_1(x)
ff_output = self.ff(x)
x = self.dropout(x + ff_output) # Apply dropout after residual
x = self.layer_norm_2(x)
# 2. Feed forward with residual connection and layer norm
return x
解码器层
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super().__init__()
# 1. Masked Multi-head attention
#YOUR CODE HERE
# 2. Layer norm for first sub-layer
#YOUR CODE HERE
# 3. Multi-head attention for cross attention with encoder output
# This will take encoder output as key and value
#YOUR CODE HERE
# 4. Layer norm for second sub-layer
#YOUR CODE HERE
# 5. Feed forward network
#YOUR CODE HERE
# 6. Layer norm for third sub-layer
#YOUR CODE HERE
# 7. Dropout
#YOUR CODE HERE
def forward(self, x, encoder_output, src_mask=None, tgt_mask=None):
"""
Args:
x: Target sequence embedding (batch_size, target_seq_len, d_model)
encoder_output: Output from encoder (batch_size, source_seq_len, d_model)
src_mask: Mask for source padding
tgt_mask: Mask for target padding and future positions
"""
# 1. Masked self-attention
# Remember: In decoder self-attention, query, key, value are all x
#YOUR CODE HERE
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super().__init__()
# 1. Masked Multi-head attention
self.mha_1 = MultiHeadAttention(d_model,num_heads)
# 2. Layer norm for first sub-layer
self.layer_norm_1 = nn.LayerNorm(d_model)
# 3. Multi-head attention for cross attention with encoder output
# This will take encoder output as key and value
self.mha_2 = MultiHeadAttention(d_model,num_heads)
# 4. Layer norm for second sub-layer
self.layer_norm_2 = nn.LayerNorm(d_model)
# 5. Feed forward network
self.ff = FeedForwardNetwork(d_model,d_ff)
# 6. Layer norm for third sub-layer
self.layer_norm_3 = nn.LayerNorm(d_model)
# 7. Dropout
self.dropout = nn.Dropout(dropout)
def forward(self, x, encoder_output, src_mask=None, tgt_mask=None):
"""
Args:
x: Target sequence embedding (batch_size, target_seq_len, d_model)
encoder_output: Output from encoder (batch_size, source_seq_len, d_model)
src_mask: Mask for source padding
tgt_mask: Mask for target padding and future positions
"""
# 1. Masked self-attention
# Remember: In decoder self-attention, query, key, value are all x
att_output = self.mha_1(x,x,x,tgt_mask)
x = self.dropout(x + att_output)
x = self.layer_norm_1(x)
att_output_2 = self.mha_2(x, encoder_output,encoder_output, src_mask)
x = self.dropout(x + att_output_2)
x = self.layer_norm_2(x)
ff_output = self.ff(x)
x = self.dropout(x + ff_output)
x = self.layer_norm_3(x)
return x
编码器
class Encoder(nn.Module):
def __init__(self,
vocab_size,
d_model,
num_layers=6,
num_heads=8,
d_ff=2048,
dropout=0.1,
max_seq_length=5000):
super().__init__()
# 1. Input embedding
#YOUR CODE HERE
# 2. Positional encoding
#YOUR CODE HERE
# 3. Dropout
#YOUR CODE HERE
# 4. Stack of N encoder layers
#YOUR CODE HERE
def forward(self, x, mask=None):
"""
Args:
x: Input tokens (batch_size, seq_len)
mask: Mask for padding positions
Returns:
encoder_output: (batch_size, seq_len, d_model)
"""
# 1. Pass through embedding layer and scale
#YOUR CODE HERE
# 2. Add positional encoding and apply dropout
#YOUR CODE HERE
# 3. Pass through each encoder layer
#YOUR CODE HERE
class Encoder(nn.Module):
def __init__(self,
vocab_size,
d_model,
num_layers=6,
num_heads=8,
d_ff=2048,
dropout=0.1,
max_seq_length=5000):
super().__init__()
# 1. Input embedding
self.embeddings = nn.Embedding(vocab_size, d_model)
self.scale = math.sqrt(d_model)
# 2. Positional encoding
self.pe = PositionalEncoding(d_model, max_seq_length)
# 3. Dropout
self.dropout = nn.Dropout(dropout)
# 4. Stack of N encoder layers
self.encoder_layers = nn.ModuleList([
EncoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(num_layers)
])
def forward(self, x, mask=None):
"""
Args:
x: Input tokens (batch_size, seq_len)
mask: Mask for padding positions
Returns:
encoder_output: (batch_size, seq_len, d_model)
"""
# 1. Pass through embedding layer and scale
x = self.embeddings(x) * self.scale
# 2. Add positional encoding and apply dropout
x = self.dropout(self.pe(x))
# 3. Pass through each encoder layer
for layer in self.encoder_layers:
x = layer(x, mask)
return x
解码器
class Decoder(nn.Module):
def __init__(self,
vocab_size,
d_model,
num_layers=6,
num_heads=8,
d_ff=2048,
dropout=0.1,
max_seq_length=5000):
super().__init__()
# 1. Output embedding
#YOUR CODE HERE
# 2. Positional encoding
#YOUR CODE HERE
# 3. Dropout
#YOUR CODE HERE
# 4. Stack of N decoder layers
#YOUR CODE HERE
def forward(self, x, encoder_output, src_mask=None, tgt_mask=None):
"""
Args:
x: Target tokens (batch_size, target_seq_len)
encoder_output: Output from encoder (batch_size, source_seq_len, d_model)
src_mask: Mask for source padding
tgt_mask: Mask for target padding and future positions
Returns:
decoder_output: (batch_size, target_seq_len, d_model)
"""
# 1. Pass through embedding layer and scale
#YOUR CODE HERE
# 2. Add positional encoding and dropout
#YOUR CODE HERE
# 3. Pass through each decoder layer
#YOUR CODE HERE
class Decoder(nn.Module):
def __init__(self,
vocab_size,
d_model,
num_layers=6,
num_heads=8,
d_ff=2048,
dropout=0.1,
max_seq_length=5000):
super().__init__()
# 1. Output embedding
self.embeddings = nn.Embedding(vocab_size, d_model)
self.scale = math.sqrt(d_model)
# 2. Positional encoding
self.pe = PositionalEncoding(d_model, max_seq_length)
# 3. Dropout
self.dropout = nn.Dropout(dropout)
# 4. Stack of N decoder layers
self.decoder_layers = nn.ModuleList([
DecoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(num_layers)
])
def forward(self, x, encoder_output, src_mask=None, tgt_mask=None):
"""
Args:
x: Target tokens (batch_size, target_seq_len)
encoder_output: Output from encoder (batch_size, source_seq_len, d_model)
src_mask: Mask for source padding
tgt_mask: Mask for target padding and future positions
Returns:
decoder_output: (batch_size, target_seq_len, d_model)
"""
# 1. Pass through embedding layer and scale
x = self.embeddings(x) * self.scale
# 2. Add positional encoding and dropout
x = self.dropout(self.pe(x))
# 3. Pass through each decoder layer
for layer in self.decoder_layers:
x = layer(x, encoder_output, src_mask, tgt_mask)
return x
辅助代码
def create_padding_mask(seq):
"""
Create mask for padding tokens (0s)
Args:
seq: Input sequence tensor (batch_size, seq_len)
Returns:
mask: Padding mask (batch_size, 1, 1, seq_len)
"""
#YOUR CODE HERE
def create_future_mask(size):
"""
Create mask to prevent attention to future positions
Args:
size: Size of square mask (target_seq_len)
Returns:
mask: Future mask (1, 1, size, size)
"""
# Create upper triangular matrix and invert it
#YOUR CODE HERE
def create_masks(src, tgt):
"""
Create all masks needed for training
Args:
src: Source sequence (batch_size, src_len)
tgt: Target sequence (batch_size, tgt_len)
Returns:
src_mask: Padding mask for encoder
tgt_mask: Combined padding and future mask for decoder
"""
# 1. Create padding masks
#YOUR CODE HERE
# 2. Create future mask
#YOUR CODE HERE
# 3. Combine padding and future mask for target
# Both masks should be True for allowed positions
#YOUR CODE HERE
def create_padding_mask(seq):
"""
Create mask for padding tokens (0s)
Args:
seq: Input sequence tensor (batch_size, seq_len)
Returns:
mask: Padding mask (batch_size, 1, 1, seq_len)
"""
batch_size, seq_len = seq.shape
output = torch.eq(seq, 0).float()
return output.view(batch_size, 1, 1, seq_len)
def create_future_mask(size):
"""
Create mask to prevent attention to future positions
Args:
size: Size of square mask (target_seq_len)
Returns:
mask: Future mask (1, 1, size, size)
"""
# Create upper triangular matrix and invert it
mask = torch.triu(torch.ones((1, 1, size, size)), diagonal=1) == 0
return mask
def create_masks(src, tgt):
"""
Create all masks needed for training
Args:
src: Source sequence (batch_size, src_len)
tgt: Target sequence (batch_size, tgt_len)
Returns:
src_mask: Padding mask for encoder
tgt_mask: Combined padding and future mask for decoder
"""
# 1. Create padding masks
src_padding_mask = create_padding_mask(src)
tgt_padding_mask = create_padding_mask(tgt)
# 2. Create future mask
tgt_len = tgt.size(1)
tgt_future_mask = create_future_mask(tgt_len)
# 3. Combine padding and future mask for target
# Both masks should be True for allowed positions
tgt_mask = tgt_padding_mask & tgt_future_mask
return src_padding_mask, tgt_mask
Transformer
class Transformer(nn.Module):
def __init__(self,
src_vocab_size,
tgt_vocab_size,
d_model,
num_layers=6,
num_heads=8,
d_ff=2048,
dropout=0.1,
max_seq_length=5000):
super().__init__()
# Pass all necessary parameters to Encoder and Decoder
#YOUR CODE HERE
# The final linear layer should project from d_model to tgt_vocab_size
#YOUR CODE HERE
def forward(self, src, tgt):
# Create masks for source and target
#YOUR CODE HERE
# Pass through encoder
#YOUR CODE HERE
# Pass through decoder
#YOUR CODE HERE
# Project to vocabulary size
#YOUR CODE HERE
class Transformer(nn.Module):
def __init__(self,
src_vocab_size,
tgt_vocab_size,
d_model,
num_layers=6,
num_heads=8,
d_ff=2048,
dropout=0.1,
max_seq_length=5000):
super().__init__()
# Pass all necessary parameters to Encoder and Decoder
self.encoder = Encoder(
src_vocab_size,
d_model,
num_layers,
num_heads,
d_ff,
dropout,
max_seq_length
)
self.decoder = Decoder(
tgt_vocab_size,
d_model,
num_layers,
num_heads,
d_ff,
dropout,
max_seq_length
)
# The final linear layer should project from d_model to tgt_vocab_size
self.final_layer = nn.Linear(d_model, tgt_vocab_size)
def forward(self, src, tgt):
# Create masks for source and target
src_mask, tgt_mask = create_masks(src, tgt)
# Pass through encoder
encoder_output = self.encoder(src, src_mask)
# Pass through decoder
decoder_output = self.decoder(tgt, encoder_output, src_mask, tgt_mask)
# Project to vocabulary size
output = self.final_layer(decoder_output)
# Note: Usually don't apply softmax here if using CrossEntropyLoss
# as it applies log_softmax internally
return output
Transformer 的辅助代码
class TransformerLRScheduler:
def __init__(self, optimizer, d_model, warmup_steps):
"""
Args:
optimizer: Optimizer to adjust learning rate for
d_model: Model dimensionality
warmup_steps: Number of warmup steps
"""
self.optimizer = optimizer
self.d_model = d_model
self.warmup_steps = warmup_steps
def step(self, step_num):
"""
Update learning rate based on step number
"""
# lrate = d_model^(-0.5) * min(step_num^(-0.5), step_num * warmup_steps^(-1.5))
#YOUR CODE HERE
class LabelSmoothing(nn.Module):
def __init__(self, smoothing=0.1):
super().__init__()
self.smoothing = smoothing
self.confidence = 1.0 - smoothing
def forward(self, logits, target):
"""
Args:
logits: Model predictions (batch_size, vocab_size) #each row of vocab_size contains probability score of each label
target: True labels (batch_size) #each row of batch size contains the index to the correct label
"""
#Note: make sure to not save the gradients of these
# Create a soft target distribution
#create the zeros [0,0,...]
#fill with calculated value [0.000125..,0.000125...] (this is an arbitarary value for example purposes)
#add 1 to the correct index (read more on docs of pytorch)
#return cross entropy loss
class TransformerLRScheduler:
def __init__(self, optimizer, d_model, warmup_steps):
"""
Args:
optimizer: Optimizer to adjust learning rate for
d_model: Model dimensionality
warmup_steps: Number of warmup steps
"""
# Your code here
# lrate = d_model^(-0.5) * min(step_num^(-0.5), step_num * warmup_steps^(-1.5))
self.optimizer = optimizer
self.d_model = d_model
self.warmup_steps = warmup_steps
def step(self, step_num):
"""
Update learning rate based on step number
"""
# Your code here - implement the formula
lrate = torch.pow(self.d_model,-0.5)*torch.min(torch.pow(step_num,-0.5), torch.tensor(step_num) * torch.pow(self.warmup_steps,-1.5))
class LabelSmoothing(nn.Module):
def __init__(self, smoothing=0.1):
super().__init__()
self.smoothing = smoothing
self.confidence = 1.0 - smoothing
def forward(self, logits, target):
"""
Args:
logits: Model predictions (batch_size, vocab_size) #each row of vocab_size contains probability score of each label
target: True labels (batch_size) #each row of batch size contains the index to the correct label
"""
vocab_size = logits.size(-1)
with torch.no_grad():
# Create a soft target distribution
true_dist = torch.zeros_like(logits) #create the zeros [0,0,...]
true_dist.fill_(self.smoothing / (vocab_size - 1)) #fill with calculated value [0.000125..,0.000125...] (this is an arbitarary value for example purposes)
true_dist.scatter_(1, target.unsqueeze(1), self.confidence) #add 1 to the correct index (read more on docs of pytorch)
return torch.mean(torch.sum(-true_dist * torch.log_softmax(logits, dim=-1), dim=-1)) #return cross entropy loss
训练 Transformer 模型
def train_transformer(model, train_dataloader, criterion, optimizer, scheduler, num_epochs, device='cuda'):
"""
Training loop for transformer
Args:
model: Transformer model
train_dataloader: DataLoader for training data
criterion: Loss function (with label smoothing)
optimizer: Optimizer
scheduler: Learning rate scheduler
num_epochs: Number of training epochs
"""
# 1. Setup
# 2. Training loop
def train_transformer(model, train_dataloader, criterion, optimizer, scheduler, num_epochs, device='cuda'):
"""
Training loop for transformer
Args:
model: Transformer model
train_dataloader: DataLoader for training data
criterion: Loss function (with label smoothing)
optimizer: Optimizer
scheduler: Learning rate scheduler
num_epochs: Number of training epochs
"""
# 1. Setup
model = model.to(device)
model.train()
# For tracking training progress
total_loss = 0
all_losses = []
# 2. Training loop
for epoch in range(num_epochs):
print(f"Epoch {epoch + 1}/{num_epochs}")
epoch_loss = 0
for batch_idx, batch in enumerate(train_dataloader):
# Get source and target batches
src = batch['src'].to(device)
tgt = batch['tgt'].to(device)
# Create masks
src_mask, tgt_mask = create_masks(src, tgt)
# Prepare target for input and output
# Remove last token from target for input
tgt_input = tgt[:, :-1]
# Remove first token from target for output
tgt_output = tgt[:, 1:]
# Zero gradients
optimizer.zero_grad()
# Forward pass
outputs = model(src, tgt_input, src_mask, tgt_mask)
# Reshape outputs and target for loss calculation
outputs = outputs.view(-1, outputs.size(-1))
tgt_output = tgt_output.view(-1)
# Calculate loss
loss = criterion(outputs, tgt_output)
# Backward pass
loss.backward()
# Clip gradients
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
# Update weights
optimizer.step()
scheduler.step()
# Update loss tracking
epoch_loss += loss.item()
# Print progress every N batches
if batch_idx % 100 == 0:
print(f"Batch {batch_idx}, Loss: {loss.item():.4f}")
# Calculate average loss for epoch
avg_epoch_loss = epoch_loss / len(train_dataloader)
all_losses.append(avg_epoch_loss)
print(f"Epoch {epoch + 1} Loss: {avg_epoch_loss:.4f}")
# Save checkpoint
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': avg_epoch_loss,
}, f'checkpoint_epoch_{epoch+1}.pt')
return all_losses
设置数据集和数据加载器
import os
import torch
import spacy
import urllib.request
import zipfile
from torch.utils.data import Dataset, DataLoader
def download_multi30k():
"""Download Multi30k dataset if not present"""
# Create data directory
if not os.path.exists('data'):
os.makedirs('data')
# Download files if they don't exist
base_url = "https://raw.githubusercontent.com/multi30k/dataset/master/data/task1/raw/"
files = {
"train.de": "train.de.gz",
"train.en": "train.en.gz",
"val.de": "val.de.gz",
"val.en": "val.en.gz",
"test.de": "test_2016_flickr.de.gz",
"test.en": "test_2016_flickr.en.gz"
}
for local_name, remote_name in files.items():
filepath = f'data/{local_name}'
if not os.path.exists(filepath):
url = base_url + remote_name
urllib.request.urlretrieve(url, filepath + '.gz')
os.system(f'gunzip -f {filepath}.gz')
def load_data(filename):
"""Load data from file"""
with open(filename, 'r', encoding='utf-8') as f:
return [line.strip() for line in f]
def create_dataset():
"""Create dataset from files"""
# Download data if needed
download_multi30k()
# Load data
train_de = load_data('data/train.de')
train_en = load_data('data/train.en')
val_de = load_data('data/val.de')
val_en = load_data('data/val.en')
return (train_de, train_en), (val_de, val_en)
class TranslationDataset(Dataset):
def __init__(self, src_texts, tgt_texts, src_vocab, tgt_vocab, src_tokenizer, tgt_tokenizer):
self.src_texts = src_texts
self.tgt_texts = tgt_texts
self.src_vocab = src_vocab
self.tgt_vocab = tgt_vocab
self.src_tokenizer = src_tokenizer
self.tgt_tokenizer = tgt_tokenizer
def __len__(self):
return len(self.src_texts)
def __getitem__(self, idx):
src_text = self.src_texts[idx]
tgt_text = self.tgt_texts[idx]
# Tokenize
src_tokens = [tok.text for tok in self.src_tokenizer(src_text)]
tgt_tokens = [tok.text for tok in self.tgt_tokenizer(tgt_text)]
# Convert to indices
src_indices = [self.src_vocab["<s>"]] + [self.src_vocab[token] for token in src_tokens] + [self.src_vocab["</s>"]]
tgt_indices = [self.tgt_vocab["<s>"]] + [self.tgt_vocab[token] for token in tgt_tokens] + [self.tgt_vocab["</s>"]]
return {
'src': torch.tensor(src_indices),
'tgt': torch.tensor(tgt_indices)
}
def build_vocab_from_texts(texts, tokenizer, min_freq=2):
"""Build vocabulary from texts"""
counter = {}
for text in texts:
for token in [tok.text for tok in tokenizer(text)]:
counter[token] = counter.get(token, 0) + 1
# Create vocabulary
vocab = {"<s>": 0, "</s>": 1, "<blank>": 2, "<unk>": 3}
idx = 4
for word, freq in counter.items():
if freq >= min_freq:
vocab[word] = idx
idx += 1
return vocab
def create_dataloaders(batch_size=32):
# Load tokenizers
spacy_de = spacy.load("de_core_news_sm")
spacy_en = spacy.load("en_core_web_sm")
# Get data
(train_de, train_en), (val_de, val_en) = create_dataset()
# Build vocabularies
vocab_src = build_vocab_from_texts(train_de, spacy_de)
vocab_tgt = build_vocab_from_texts(train_en, spacy_en)
# Create datasets
train_dataset = TranslationDataset(
train_de, train_en,
vocab_src, vocab_tgt,
spacy_de, spacy_en
)
val_dataset = TranslationDataset(
val_de, val_en,
vocab_src, vocab_tgt,
spacy_de, spacy_en
)
# Create dataloaders
train_dataloader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
collate_fn=collate_batch
)
val_dataloader = DataLoader(
val_dataset,
batch_size=batch_size,
shuffle=False,
collate_fn=collate_batch
)
return train_dataloader, val_dataloader, vocab_src, vocab_tgt
def collate_batch(batch):
src_tensors = [item['src'] for item in batch]
tgt_tensors = [item['tgt'] for item in batch]
# Pad sequences
src_padded = torch.nn.utils.rnn.pad_sequence(src_tensors, batch_first=True, padding_value=2)
tgt_padded = torch.nn.utils.rnn.pad_sequence(tgt_tensors, batch_first=True, padding_value=2)
return {
'src': src_padded,
'tgt': tgt_padded
}
import os
import torch
import spacy
import urllib.request
import zipfile
from torch.utils.data import Dataset, DataLoader
def download_multi30k():
"""Download Multi30k dataset if not present"""
# Create data directory
if not os.path.exists('data'):
os.makedirs('data')
# Download files if they don't exist
base_url = "https://raw.githubusercontent.com/multi30k/dataset/master/data/task1/raw/"
files = {
"train.de": "train.de.gz",
"train.en": "train.en.gz",
"val.de": "val.de.gz",
"val.en": "val.en.gz",
"test.de": "test_2016_flickr.de.gz",
"test.en": "test_2016_flickr.en.gz"
}
for local_name, remote_name in files.items():
filepath = f'data/{local_name}'
if not os.path.exists(filepath):
url = base_url + remote_name
urllib.request.urlretrieve(url, filepath + '.gz')
os.system(f'gunzip -f {filepath}.gz')
def load_data(filename):
"""Load data from file"""
with open(filename, 'r', encoding='utf-8') as f:
return [line.strip() for line in f]
def create_dataset():
"""Create dataset from files"""
# Download data if needed
download_multi30k()
# Load data
train_de = load_data('data/train.de')
train_en = load_data('data/train.en')
val_de = load_data('data/val.de')
val_en = load_data('data/val.en')
return (train_de, train_en), (val_de, val_en)
class TranslationDataset(Dataset):
def __init__(self, src_texts, tgt_texts, src_vocab, tgt_vocab, src_tokenizer, tgt_tokenizer):
self.src_texts = src_texts
self.tgt_texts = tgt_texts
self.src_vocab = src_vocab
self.tgt_vocab = tgt_vocab
self.src_tokenizer = src_tokenizer
self.tgt_tokenizer = tgt_tokenizer
def __len__(self):
return len(self.src_texts)
def __getitem__(self, idx):
src_text = self.src_texts[idx]
tgt_text = self.tgt_texts[idx]
# Tokenize
src_tokens = [tok.text for tok in self.src_tokenizer(src_text)]
tgt_tokens = [tok.text for tok in self.tgt_tokenizer(tgt_text)]
# Convert to indices
src_indices = [self.src_vocab["<s>"]] + [self.src_vocab[token] for token in src_tokens] + [self.src_vocab["</s>"]]
tgt_indices = [self.tgt_vocab["<s>"]] + [self.tgt_vocab[token] for token in tgt_tokens] + [self.tgt_vocab["</s>"]]
return {
'src': torch.tensor(src_indices),
'tgt': torch.tensor(tgt_indices)
}
def build_vocab_from_texts(texts, tokenizer, min_freq=2):
"""Build vocabulary from texts"""
counter = {}
for text in texts:
for token in [tok.text for tok in tokenizer(text)]:
counter[token] = counter.get(token, 0) + 1
# Create vocabulary
vocab = {"<s>": 0, "</s>": 1, "<blank>": 2, "<unk>": 3}
idx = 4
for word, freq in counter.items():
if freq >= min_freq:
vocab[word] = idx
idx += 1
return vocab
def create_dataloaders(batch_size=32):
# Load tokenizers
spacy_de = spacy.load("de_core_news_sm")
spacy_en = spacy.load("en_core_web_sm")
# Get data
(train_de, train_en), (val_de, val_en) = create_dataset()
# Build vocabularies
vocab_src = build_vocab_from_texts(train_de, spacy_de)
vocab_tgt = build_vocab_from_texts(train_en, spacy_en)
# Create datasets
train_dataset = TranslationDataset(
train_de, train_en,
vocab_src, vocab_tgt,
spacy_de, spacy_en
)
val_dataset = TranslationDataset(
val_de, val_en,
vocab_src, vocab_tgt,
spacy_de, spacy_en
)
# Create dataloaders
train_dataloader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
collate_fn=collate_batch
)
val_dataloader = DataLoader(
val_dataset,
batch_size=batch_size,
shuffle=False,
collate_fn=collate_batch
)
return train_dataloader, val_dataloader, vocab_src, vocab_tgt
def collate_batch(batch):
src_tensors = [item['src'] for item in batch]
tgt_tensors = [item['tgt'] for item in batch]
# Pad sequences
src_padded = torch.nn.utils.rnn.pad_sequence(src_tensors, batch_first=True, padding_value=2)
tgt_padded = torch.nn.utils.rnn.pad_sequence(tgt_tensors, batch_first=True, padding_value=2)
return {
'src': src_padded,
'tgt': tgt_padded
}
开始训练循环和一些分析(带有良好收敛的提示)
# Initialize your transformer with the vocabulary sizes
model = Transformer(
src_vocab_size=len(vocab_src),
tgt_vocab_size=len(vocab_tgt),
d_model=512,
num_layers=6,
num_heads=8,
d_ff=2048,
dropout=0.1
)
criterion = LabelSmoothing(smoothing=0.1).to(device)
# Now you can use your training loop
losses = train_transformer(
model=model,
train_dataloader=train_dataloader,
criterion=criterion,
optimizer=optimizer,
scheduler=scheduler,
num_epochs=10
)
https://goyalpramod.github.io/blogs/Transformers_laid_out


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









