







{“id”:“4.1”},
{“id”:“4.4”},
{“id”:“2.3”},
{“id”:“1.1”},
{“id”:“1.2”}
],
“edges”: [
{
“id”:“e1”,
“source”: “3.1”,
“target”: “4.1”
},
{
“id”:“e2”,
“source”: “4.4”,
“target”: “4.1”
},
{
“id”:“e3”,
“source”: “3.1”,
“target”: “4.4”
},
{
“id”:“e4”,
“source”: “4.1”,
“target”: “2.3”
},
{
“id”:“e5”,
“source”: “4.4”,
“target”: “1.1”
},
{
“id”:“e6”,
“source”: “1.2”,
“target”: “1.1”
}
]
}
这是示例数组对应的无向图:
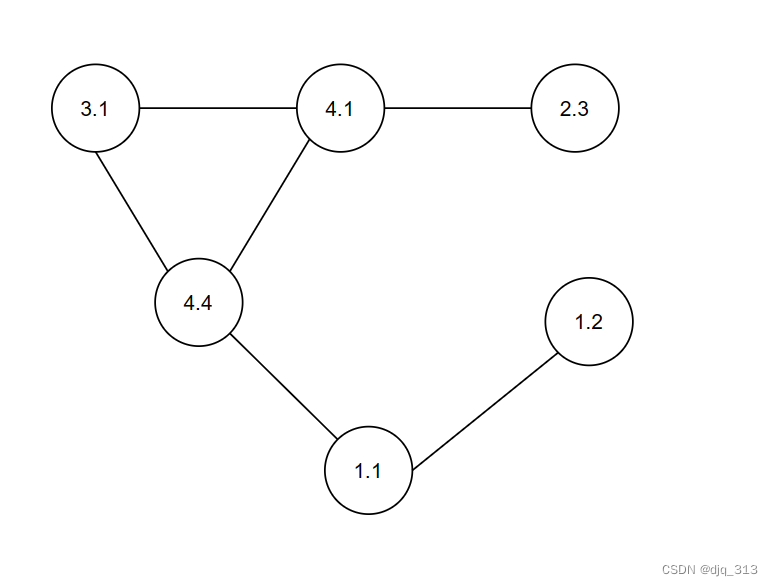
我们假设上图中每个节点间的距离均为“1”,如下图所示,例如,我们选取节点“3.1”计算其到其他节点最短路径之和:
(type-bilibili)(url-https://player.bilibili.com/player.html?aid=1804892953)(image-https://img-blog.csdnimg.cn/img_convert/d03a705143646f4f3f6ea879d59b2788.png)(title-必看视频!获取2024年最新Java开发全套学习资料 备注Java)]
://img-blog.csdnimg.cn/direct/97684309c32a4aeeb8d053030afea0d1.png)
“3.1”到“4.1”和“4.4”距离均为“1”,“3.1”到“1.1”和“2.3”距离均为“2”,“3.1”到“1.2”距离为“3”
那么,节点“3.1”计算其到其他节点最短路径之和为:1+1+2+2+3=9
同理,我们可以计算出其他节点的相应的最短路径之和。
## 三、Java代码实现
利用Brandes算法,我们能够在无向图中更轻松地计算出每个节点到其他节点最短路径之和。
以下是Java代码:
// 导入必要的库,用于处理JSON数据及集合操作
import org.json.JSONArray;
import org.json.JSONObject;
import java.util.*;
public class Main {
public static void main(String[] args) {
// 获取JSON对象,该对象包含了图的节点和边信息
JSONObject graphJson = getJsonObject();
// 创建邻接表表示图结构,键为节点ID,值为连接到该节点的所有节点ID列表
Map<String, List<String>> adjacencyList = new HashMap<>();
// 创建一个HashSet存储所有节点ID
Set<String> nodesSet = new HashSet<>();
// 解析JSON对象中的"nodes"数组,获取所有节点ID并添加到nodesSet中
JSONArray nodesArray = graphJson.getJSONArray("nodes");
for (int i = 0; i < nodesArray.length(); i++) {
JSONObject nodeObj = nodesArray.getJSONObject(i);
String nodeId = nodeObj.getString("id");
nodesSet.add(nodeId);
}
// 解析JSON对象中的"edges"数组,构建邻接表
JSONArray edgesArray = graphJson.getJSONArray("edges");
for (int i = 0; i < edgesArray.length(); i++) {
JSONObject edgeObj = edgesArray.getJSONObject(i);
String source = edgeObj.getString("source");
String target = edgeObj.getString("target");
// 假设图是无向的,所以在邻接表中双向添加边
adjacencyList.computeIfAbsent(source, k -> new ArrayList<>()).add(target);
adjacencyList.computeIfAbsent(target, k -> new ArrayList<>()).add(source);
}
// 计算并存储每个节点的中介中心性
Map<String, Double> nodeCentralities = new HashMap<>();
for (String nodeId : nodesSet) {
double centrality = calculateBetweennessCentrality(adjacencyList, nodeId);
nodeCentralities.put(nodeId, centrality);
}
// 将节点按照其中介中心性降序排列
List<Map.Entry<String, Double>> sortedNodes = new ArrayList<>(nodeCentralities.entrySet());
sortedNodes.sort(Map.Entry.comparingByValue(Comparator.reverseOrder()));
// 输出每个节点及其对应的中介中心性
System.out.println("节点:该节点到其他节点最短路径距离之和:");
for (Map.Entry<String, Double> entry : sortedNodes) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
}
// 从固定JSON字符串中创建并返回JSONObject
private static JSONObject getJsonObject() {
String jsonData = "{\"nodes\":[\n" +
"{\"id\":\"3.1\"},\n" +
"{\"id\":\"4.1\"},\n" +
"{\"id\":\"4.4\"},\n" +
"{\"id\":\"2.3\"},\n" +
"{\"id\":\"1.1\"},\n" +
"{\"id\":\"1.2\"}\n" +
"],\n" +
"\"edges\": [\n" +
" {\n" +
" \"id\":\"e1\",\n" +
" \"source\": \"3.1\",\n" +
" \"target\": \"4.1\"\n" +
" },\n" +
" {\n" +
" \"id\":\"e2\",\n" +
" \"source\": \"4.4\",\n" +
" \"target\": \"4.1\"\n" +
" },\n" +
" {\n" +
" \"id\":\"e3\",\n" +
" \"source\": \"3.1\",\n" +
" \"target\": \"4.4\"\n" +
" },\n" +
" {\n" +
" \"id\":\"e4\",\n" +
" \"source\": \"4.1\",\n" +
" \"target\": \"2.3\"\n" +
" },\n" +
" {\n" +
" \"id\":\"e5\",\n" +
" \"source\": \"4.4\",\n" +
" \"target\": \"1.1\"\n" +
" },\n" +
" {\n" +
" \"id\":\"e6\",\n" +
" \"source\": \"1.2\",\n" +
" \"target\": \"1.1\"\n" +
" }\n" +
" ]\n}";
JSONObject graphJson = new JSONObject(jsonData);
return graphJson;
}
// 根据给定的邻接表和节点ID,计算该节点的中介中心性
private static double calculateBetweennessCentrality(Map<String, List<String>> graph, String node) {
// 初始化用于计算中介中心性的三个HashMap
Map<String, Integer> sigma = new HashMap<>();
Map<String, Double> delta = new HashMap<>();
Map<String, Double> betweenness = new HashMap<>();
// 初始化所有节点的sigma、delta和betweenness值
for (String v : graph.keySet()) {
sigma.put(v, 0);
delta.put(v, 0.0);
betweenness.put(v, 0.0);
}
// 设置当前节点的sigma值为1
sigma.put(node, 1);
// 创建队列(BFS)和栈(用于回溯),以及预处理器列表和距离映射表
Queue<String> queue = new LinkedList<>();
Stack<String> stack = new Stack<>();
Map<String, List<String>> predecessors = new HashMap<>();
Map<String, Integer> distances = new HashMap<>();
// 初始化所有节点的预处理器列表和距离值
for (String v : graph.keySet()) {
predecessors.put(v, new ArrayList<>());
distances.put(v, -1);
}
// 将当前节点加入队列,并设置距离为0
queue.offer(node);
distances.put(node, 0);
// 开始广度优先搜索(BFS)
while (!queue.isEmpty()) {
String v = queue.poll();
stack.push(v);
// 遍历当前节点的所有邻居节点
for (String w : graph.get(v)) {
// 如果邻居节点尚未访问过,则将其加入队列,并更新距离
if (distances.get(w) < 0) {
结局:总结+分享
看完美团、字节、腾讯这三家的一二三面试问题,是不是感觉问的特别多,可能咱们真的又得开启面试造火箭、工作拧螺丝的模式去准备下一次的面试了。
开篇有提及我可是足足背下了Java互联网工程师面试1000题,多少还是有点用的呢,换汤不换药,不管面试官怎么问你,抓住本质即可!能读到此处的都是真爱
- Java互联网工程师面试1000题
而且从上面三家来看,算法与数据结构是必备不可少的呀,因此我建议大家可以去刷刷这本左程云大佬著作的 《程序员代码面试指南 IT名企算法与数据结构题目最优解》,里面近200道真实出现过的经典代码面试题。
- 程序员代码面试指南–IT名企算法与数据结构题目最优解

- 其余像设计模式,建议可以看看下面这4份PDF(已经整理)
- 更多的Java面试学习笔记如下,关于面试这一块,我额外细分出Java基础-中级-高级开发的面试+解析,以及调优笔记等等等。。。
以上所提及的全部Java面试学习的PDF及笔记,如若皆是你所需要的,那么都可发送给你!
)]
- 其余像设计模式,建议可以看看下面这4份PDF(已经整理)
[外链图片转存中…(img-83dxbZgE-1716404048553)]
- 更多的Java面试学习笔记如下,关于面试这一块,我额外细分出Java基础-中级-高级开发的面试+解析,以及调优笔记等等等。。。
[外链图片转存中…(img-C6F8ojzD-1716404048553)]
以上所提及的全部Java面试学习的PDF及笔记,如若皆是你所需要的,那么都可发送给你!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









