







 这篇博客介绍了Python中的argparse模块,用于处理命令行参数和选项。通过示例展示了如何定义和解析命令行参数,包括添加不同类型的参数、启用帮助选项等。博主分享了个人的编程经历,并提供了一份全面的Python学习资料,涵盖前端开发的大部分知识点,旨在帮助开发者系统地提升技能。
这篇博客介绍了Python中的argparse模块,用于处理命令行参数和选项。通过示例展示了如何定义和解析命令行参数,包括添加不同类型的参数、启用帮助选项等。博主分享了个人的编程经历,并提供了一份全面的Python学习资料,涵盖前端开发的大部分知识点,旨在帮助开发者系统地提升技能。
parser.add_argument('-s', '--seed', type=int, default=42)
parser.add_argument('-m', '--milestones', nargs='+', required=True, default=15) # -m 是一个短选项参数,后面跟着一系列值 15 30 45 60 75 90,表示将这些值作为参数传递给 -m。
parser.add_argument('-rd', '--result_directory', type=str, default="FGNET_experiments/subject")
parser.add_argument('-pi', '--pred_image', type=str, default=None)
parser.add_argument('-pm', '--pred_model', type=str, default=None)
parser.add_argument('-K', '--K', type=int, default=6)
parser.add_argument('--loss', type=str, default='mrloss', help='mean_softmax/residual_softmax/softmax/mrloss/mvloss')
parser.add_argument('--SGD', action='store_true')
parser.add_argument('--Adam', action='store_true')
parser.add_argument('--gpu', type=int, default=2, help='GPU to use')
return parser.parse_args()
参数详解
>
> **`name or flags`**:参数的名称或选项。可以是一个字符串,例如 `'--batch_size'` 或 `'-b'`,也可以是一个字符串列表,例如 `['-b', '--batch_size']`,其中 `--batch_size` 是长选项,`-b` 是短选项。
>
>
> **type**:表示输入参数的类型,可以是int,str,float
>
>
> **default**:表示参数默认的值
>
>
> **help**: 帮助信息,例如`help='VGG/ResNet'` 提供了关于该参数的帮助信息,当用户使用 `-h` 或 `--help` 选项时,该信息将显示在帮助文档中。
>
>
> **nargs**:用于定义一个选项参数应该消耗的命令行参数数量。它可以接受以下不同的取值:
>
>
> * `'+'`:表示选项参数可以**接受一个或多个参数值**。多个参数值将被解析为一个列表。例如,`-m 15 30 45` 将解析为 `args.milestones = [15, 30, 45]`。
> * `'*'`:表示选项参数可以**接受零个或多个参数值**。多个参数值将被解析为一个列表。例如,`-m 15 30 45` 将解析为 `args.milestones = [15, 30, 45]`,而不提供 `-m` 参数将解析为 `args.milestones = []`。
> * `int`:表示选项参数应该消耗**固定数量的参数值**。例如,`nargs=2` 表示选项参数需要接受两个参数值。例如,`-m 15 30` 将解析为 `args.milestones = [15, 30]`。
> * `argparse.REMAINDER`:表示选项参数应该消耗剩余的命令行参数,将其解析为一个列表。例如,`-m 15 30 45 60 75 90` 将解析为 `args.milestones = [15, 30, 45, 60, 75, 90]`。
>
>
> **`required`**:指定该参数是否是必需的。默认为 `False`,即可选参数。如果将其设置为 `True`,则在命令行中必须提供该参数,否则将引发错误。
>
>
> **`choices`**:指定参数的可选值列表。如果设置了该参数,那么命令行中提供的值必须是列表中的一个,否则将引发错误。
>
>
> **`action`**:指定参数的动作。常见的动作包括 `'store'`(默认动作,将参数值存储为属性)、`'store_true'`(将参数解析为 `True`)、`'store_false'`(将参数解析为 `False`)、`'append'`(将多个参数值存储为列表)等。
>
>
>
## 2.看下如何运用--heip
help.py
import argparse
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument(‘–net’, type=str, default=‘ResNet’, help=‘VGG/ResNet’)
return parser.parse_args()
def main():
args = get_args()
# 获取命令行参数的值
net = args.net
# 在这里使用参数进行相应的操作
print(f"net: {net}")
if name == ‘main’:
main()
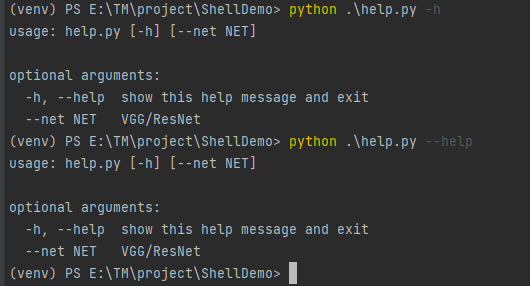
使用shell命令行查看帮助信息,一般代码是自己写,不会看的哈!
python filename.py --help
python filename.py -h
## 3.看下action四个参数的区别
help.py文件
import argparse
def main():
parser = argparse.ArgumentParser()
parser.add_argument(‘–input’, action=‘store’, type=str, help=‘Input file path’)
parser.add_argument(‘–verbose’, action=‘store_true’, help=‘Enable verbose mode’)
parser.add_argument(‘–output’, action=‘append’, help=‘Output file path’)
args = parser.parse_args()
# 使用解析后的参数进行后续处理
if args.input:
print(f'Input file: {args.input}')
if args.verbose:
print('Verbose mode enabled')
if args.output:
print(f'Output files: {args.output}')
if name == ‘main’:
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注Python)
学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!**
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注Python)


















 1920
1920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









