




只要你有一个时间变量来过滤,那么几乎任何图表都可以做成动画。下面是一个制作散点图动画的例子:
import plotly.express as px
df = px.data.gapminder()
fig = px.scatter(
df,
x=“gdpPercap”,
y=“lifeExp”,
animation_frame=“year”,
size=“pop”,
color=“continent”,
hover_name=“country”,
log_x=True,
size_max=55,
range_x=[100, 100000],
range_y=[25, 90],
color_continuous_scale=px.colors.sequential.Emrld
)
fig.update_layout(width=1000,
height=800,
xaxis_showgrid=False,
yaxis_showgrid=False,
paper_bgcolor=‘rgba(0,0,0,0)’,
plot_bgcolor=‘rgba(0,0,0,0)’)
太阳图
太阳图(sunburst chart)是一种可视化 group by 语句的好方法。如果你想通过一个或多个类别变量来分解一个给定的量,那就用太阳图吧。
假设我们想根据性别和每天的时间分解平均小费数据,那么相较于表格,这种双重 group by 语句可以通过可视化来更有效地展示。

这个图表是交互式的,让你可以自己点击并探索各个类别。你只需要定义你的所有类别,并声明它们之间的层次结构(见以下代码中的 parents 参数)并分配对应的值即可,这在我们案例中即为 group by 语句的输出。
import plotly.graph_objects as go
import plotly.express as px
import numpy as np
import pandas as pd
df = px.data.tips()
fig = go.Figure(go.Sunburst(
labels=[“Female”, “Male”, “Dinner”, “Lunch”, 'Dinner ', 'Lunch '],
parents=[“”, “”, “Female”, “Female”, ‘Male’, ‘Male’],
values=np.append(
df.groupby(‘sex’).tip.mean().values,
df.groupby([‘sex’, ‘time’]).tip.mean().values),
marker=dict(colors=px.colors.sequential.Emrld)),
layout=go.Layout(paper_bgcolor=‘rgba(0,0,0,0)’,
plot_bgcolor=‘rgba(0,0,0,0)’))
fig.update_layout(margin=dict(t=0, l=0, r=0, b=0),
title_text=‘Tipping Habbits Per Gender, Time and Day’)
fig.show()
现在我们向这个层次结构再添加一层:

为此,我们再添加另一个涉及三个类别变量的 group by 语句的值。
import plotly.graph_objects as go
import plotly.express as px
import pandas as pd
import numpy as np
df = px.data.tips()
fig = go.Figure(go.Sunburst(labels=[
“Female”, “Male”, “Dinner”, “Lunch”, 'Dinner ', 'Lunch ', ‘Fri’, ‘Sat’,
‘Sun’, ‘Thu’, 'Fri ', 'Thu ', 'Fri ', 'Sat ', 'Sun ', 'Fri ', 'Thu ’
],
parents=[
“”, “”, “Female”, “Female”, ‘Male’, ‘Male’,
‘Dinner’, ‘Dinner’, ‘Dinner’, ‘Dinner’,
‘Lunch’, ‘Lunch’, 'Dinner ', 'Dinner ',
'Dinner ', 'Lunch ', 'Lunch ’
],
values=np.append(
np.append(
df.groupby(‘sex’).tip.mean().values,
df.groupby([‘sex’,
‘time’]).tip.mean().values,
),
df.groupby([‘sex’, ‘time’,
‘day’]).tip.mean().values),
marker=dict(colors=px.colors.sequential.Emrld)),
layout=go.Layout(paper_bgcolor=‘rgba(0,0,0,0)’,
plot_bgcolor=‘rgba(0,0,0,0)’))
fig.update_layout(margin=dict(t=0, l=0, r=0, b=0),
title_text=‘Tipping Habbits Per Gender, Time and Day’)
fig.show()
平行类别
另一种探索类别变量之间关系的方法是以下这种流程图。你可以随时拖放、高亮和浏览值,非常适合演示时使用。
代码如下:
import plotly.express as px
from vega_datasets import data
import pandas as pd
df = data.movies()
df = df.dropna()
df[‘Genre_id’] = df.Major_Genre.factorize()[0]
fig = px.parallel_categories(
df,
dimensions=[‘MPAA_Rating’, ‘Creative_Type’, ‘Major_Genre’],
color=“Genre_id”,
color_continuous_scale=px.colors.sequential.Emrld,
)
fig.show()
平行坐标图
平行坐标图是上面的图表的连续版本。这里,每一根弦都代表单个观察。这是一种可用于识别离群值(远离其它数据的单条线)、聚类、趋势和冗余变量(比如如果两个变量在每个观察上的值都相近,那么它们将位于同一水平线上,表示存在冗余)的好用工具。
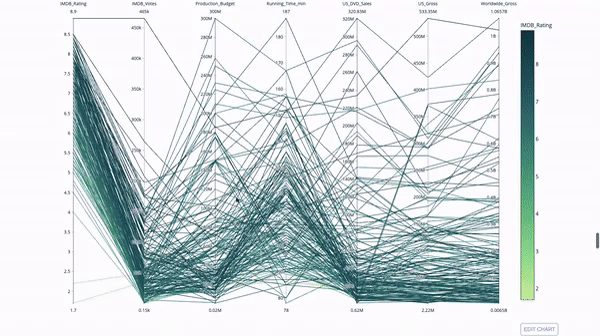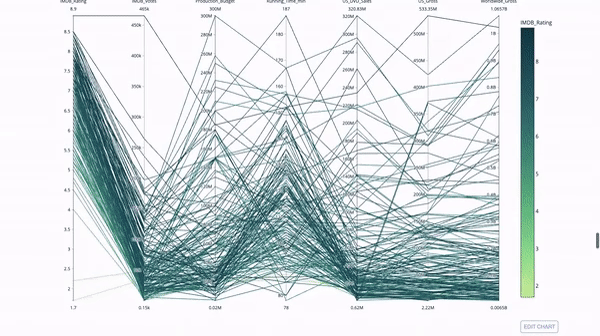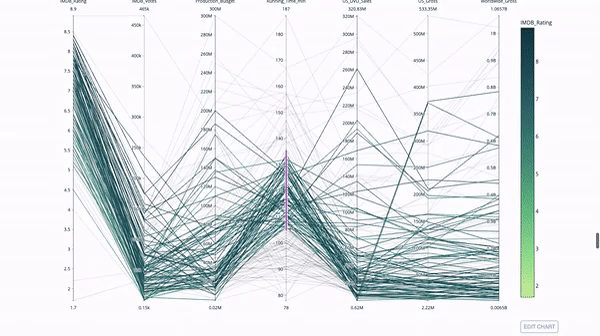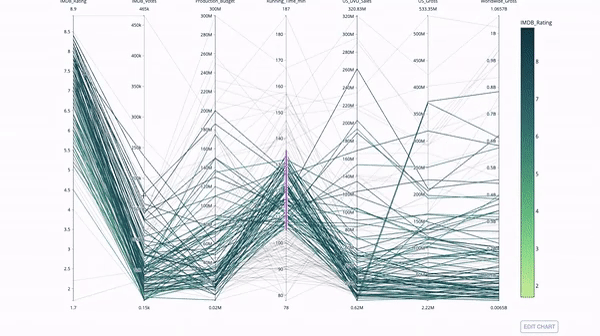
代码如下:
import plotly.express as px
from vega_datasets import data
import pandas as pd
df = data.movies()
df = df.dropna()
df[‘Genre_id’] = df.Major_Genre.factorize()[0]
fig = px.parallel_coordinates(
df,
dimensions=[
‘IMDB_Rating’, ‘IMDB_Votes’, ‘Production_Budget’, ‘Running_Time_min’,
‘US_Gross’, ‘Worldwide_Gross’, ‘US_DVD_Sales’
],
color=‘IMDB_Rating’,
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注Python)
96f86381401c05e862fe4e9.png)
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注Python)


















 1306
1306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









