






前言:
引入 MQ 消息中间件最直接的目的是:做系统解耦合流量控制,追其根源还是为了解决互联网系统的高可用和高性能问题。
系统解耦:用 MQ 消息队列,可以隔离系统上下游环境变化带来的不稳定因素,比如:优惠劵服务系统的需求无论如何变化,交易服务不用做任何改变,即使当优惠劵服务出现故障,主交易流程也可以将优惠劵服务降级,实现交易服务和优惠劵服务的解耦,做到了系统的高可用。
流量控制:遇到秒杀等流量突增的场景,通过 MQ 还可以实现流量的“削峰填谷”的作用,可以根据下游的处理能力自动调节流量。
引入 MQ 虽然实现了系统解耦合流量控制,但也会带来其他问题:
1.引入 MQ 消息中间件实现系统解耦,会影响系统之间数据传输的一致性。 在分布式系统中,如果两个节点之间存在数据同步,就会带来数据一致性的问题。同理,在这一点要解决的就是:消息生产端和消息消费端的消息数据一致性问题(也就是如何确保消息不丢失)。
2.引入 MQ 消息中间件解决流量控制 , 会使消费端处理能力不足从而导致消息积压。
1.如何确保消息不丢失?
如何确保消息不丢失?——> 如何知道产生了消息丢失问题?——> 哪些环节可能丢消息?
网络中的数据传输不可靠,想要解决如何不丢消息的问题,首先要知道哪些环节可能丢消息,以及我们如何知道消息是否丢失了,最后才是解决方案。
1.1首先来看消息丢失的环节
一条消息从生产到消费完成这个过程,可以划分三个阶段,分别为消息生产阶段,消息存储阶段和消息消费阶段。

消息生产阶段: 从消息被生产出来,然后提交给 MQ 的过程中,只要能正常收到 MQ Broker 的 ack 确认响应,就表示发送成功,所以只要处理好返回值和异常,这个阶段是不会出现消息丢失的。
消息存储阶段: 这个阶段一般会直接交给 MQ 消息中间件来保证,但是你要了解它的原理,比如 Broker 会做副本,保证一条消息至少同步两个节点再返回 ack。
消息消费阶段: 消费端从 Broker 上拉取消息,只要消费端在收到消息后,不立即发送消费确认给 Broker,而是等到执行完业务逻辑后,再发送消费确认,也能保证消息的不丢失。
除此之外还需要一种机制来 Check 消息是否丢失
1.2消息检测
总体方案解决思路为:在消息生产端,给每个发出的消息都指定一个全局唯一 ID,或者附加一个连续递增的版本号,然后在消费端做对应的版本校验。
利用拦截器机制:在生产端发送消息之前,通过拦截器将消息版本号注入消息中(版本号可以采用连续递增的 ID 生成,也可以通过分布式全局唯一 ID生成)。然后在消费端收到消息后,再通过拦截器检测版本号的连续性或消费状态,这样实现的好处是消息检测的代码不会侵入到业务代码中,可以通过单独的任务来定位丢失的消息,做进一步的排查。
注意:如果同时存在多个消息生产端和消息消费端,通过版本号递增的方式就很难实现了,因为不能保证版本号的唯一性,此时只能通过全局唯一 ID 的方案来进行消息检测,具体的实现原理和版本号递增的方式一致。
2.如何解决消息被重复消费的问题?
如何解决消费端幂等性问题(幂等性,就是一条命令,任意多次执行所产生的影响均与一次执行的影响相同),只要消费端具备了幂等性,那么重复消费消息的问题也就解决了。
在消息消费的过程中,如果出现失败的情况,通过补偿的机制发送方会执行重试,重试的过程就有可能产生重复的消息。
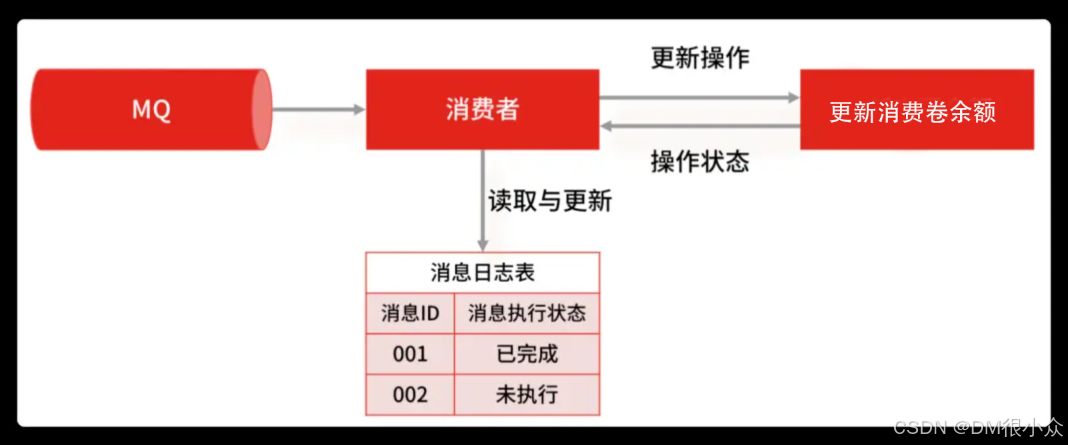
在数据库中建一张消息日志表 , 这个表有两个字段:消息 ID 和消息执行状态。这样,我们消费消息的逻辑可以变为:在消息日志表中增加一条消息记录,然后再根据消息记录,异步操作更新用户消费卷余额。
因为每次都会在插入之前检查是否消息已存在,所以就不会出现一条消息被执行多次的情况,这样就实现了一个幂等的操作。当然,基于这个思路,不仅可以使用关系型数据库,也可以通过 Redis 来代替数据库实现唯一约束的方案。
想要解决“消息丢失”和“消息重复消费”的问题,有一个前提条件就是要实现一个全局唯一 ID 生成的技术方案。在分布式系统中,全局唯一 ID 生成的实现方法有数据库自增主键、UUID、Redis,Twitter-Snowflake 算法。
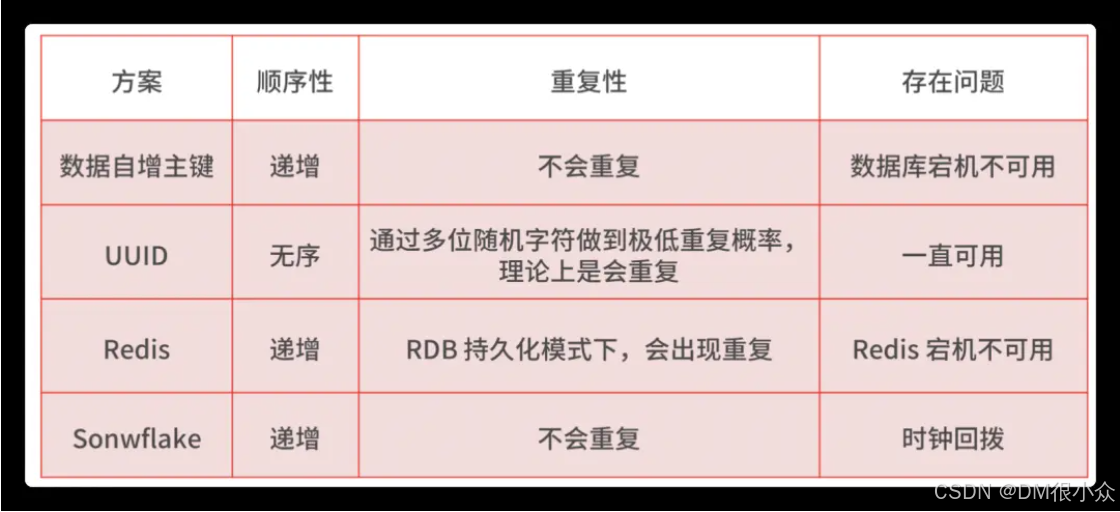
无论哪种方法,如果想同时满足简单、高可用和高性能,就要有取舍,所以要站在实际的业务中,关注选型所考虑的平衡点是什么。在业务中个人推荐选择 Snowflake 算法,主要是让算法中的 ID 生成规则更加符合业务特点,以及优化诸如时钟回拨等问题。
1.3消息积压
消息积压反映的是性能问题,解决消息积压问题,是处理高并发场景下的消费能力问题。
如果出现积压,那一定是性能问题,想要解决消息从生产到消费上的性能问题,就首先要知道哪些环节可能出现消息积压,然后在考虑如何解决。因为消息发送之后才会出现积压的问题,所以和消息生产端没有关系,又因为绝大部分的消息队列单节点都能达到每秒钟几万的处理能力,相对于业务逻辑来说,性能不会出现在中间件的消息存储上面。毫无疑问,出问题的肯定是消息消费阶段。
1.如果是线上突发问题,要临时扩容,增加消费端的数量,与此同时,降级一些非核心的业务。通过扩容和降级承担流量。
2.排查解决异常问题,通过监控、日志等手段分析是否消费端的业务逻辑代码出现了问题,优化消费端的业务处理逻辑。
3.如果是消费端的处理能力不足,可以通过水平扩容来提供消费端的并发处理能力。(在扩容消费者的实例数的同时,必须同步扩容主题 Topic 的分区数量,确保消费者的实例数和分区数相等。如果消费者的实例数超过了分区数,由于分区是单线程消费,所以这样的扩容就没有效果。)
在 Kafka 中,一个 Topic 可以配置多个 Partition(分区),数据会被写入到多个分区中,但在消费的时候,Kafka 约定一个分区只能被一个消费者消费,Topic 的分区数量决定了消费的能力,所以,可以通过增加分区来提高消费者的处理能力。


















 1068
1068

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









