








最全的Linux教程,Linux从入门到精通
======================
-
linux从入门到精通(第2版)
-
Linux系统移植
-
Linux驱动开发入门与实战
-
LINUX 系统移植 第2版
-
Linux开源网络全栈详解 从DPDK到OpenFlow

第一份《Linux从入门到精通》466页
====================
内容简介
====
本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。本书第1版出版后曾经多次印刷,并被51CTO读书频道评为“最受读者喜爱的原创IT技术图书奖”。本书第﹖版以最新的Ubuntu 12.04为版本,循序渐进地向读者介绍了Linux 的基础应用、系统管理、网络应用、娱乐和办公、程序开发、服务器配置、系统安全等。本书附带1张光盘,内容为本书配套多媒体教学视频。另外,本书还为读者提供了大量的Linux学习资料和Ubuntu安装镜像文件,供读者免费下载。

本书适合广大Linux初中级用户、开源软件爱好者和大专院校的学生阅读,同时也非常适合准备从事Linux平台开发的各类人员。
需要《Linux入门到精通》、《linux系统移植》、《Linux驱动开发入门实战》、《Linux开源网络全栈》电子书籍及教程的工程师朋友们劳烦您转发+评论
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
客户端(client)代表用户与namenode和datanode交互来访问整个文件系统。客户端提供了一些列的文件系统接口,因此我们在编程时,几乎无须知道datanode和namenode,即可完成我们所需要的功能。
1.1Namenode容错机制
没有Namenode,HDFS就不能工作。事实上,如果运行namenode的机器坏掉的话,系统中的文件将会完全丢失,因为没有其他方法能够将位于不同datanode上的文件块(blocks)重建文件。因此,namenode的容错机制非常重要,Hadoop提供了两种机制。
第一种方式是将持久化存储在本地硬盘的文件系统元数据备份。Hadoop可以通过配置来让Namenode将他的持久化状态文件写到不同的文件系统中。这种写操作是同步并且是原子化的。比较常见的配置是在将持久化状态写到本地硬盘的同时,也写入到一个远程挂载的网络文件系统。
第二种方式是运行一个辅助的Namenode(Secondary Namenode)。 事实上Secondary Namenode并不能被用作Namenode它的主要作用是定期的将Namespace镜像与操作日志文件(edit log)合并,以防止操作日志文件(edit log)变得过大。通常,Secondary Namenode 运行在一个单独的物理机上,因为合并操作需要占用大量的CPU时间以及和Namenode相当的内存。辅助Namenode保存着合并后的Namespace镜像的一个备份,万一哪天Namenode宕机了,这个备份就可以用上了。
但是辅助Namenode总是落后于主Namenode,所以在Namenode宕机时,数据丢失是不可避免的。在这种情况下,一般的,要结合第一种方式中提到的远程挂载的网络文件系统(NFS)中的Namenode的元数据文件来使用,把NFS中的Namenode元数据文件,拷贝到辅助Namenode,并把辅助Namenode作为主Namenode来运行。
2、Datanode介绍
Datanode是文件系统的工作节点,他们根据客户端或者是namenode的调度存储和检索数据,并且定期向namenode发送他们所存储的块(block)的列表。
集群中的每个服务器都运行一个DataNode后台程序,这个后台程序负责把HDFS数据块读写到本地的文件系统。当需要通过客户端读/写某个 数据时,先由NameNode告诉客户端去哪个DataNode进行具体的读/写操作,然后,客户端直接与这个DataNode服务器上的后台程序进行通 信,并且对相关的数据块进行读/写操作。
3、Secondary NameNode介绍
Secondary NameNode是一个用来监控HDFS状态的辅助后台程序。就想NameNode一样,每个集群都有一个Secondary NameNode,并且部署在一个单独的服务器上。Secondary NameNode不同于NameNode,它不接受或者记录任何实时的数据变化,但是,它会与NameNode进行通信,以便定期地保存HDFS元数据的 快照。由于NameNode是单点的,通过Secondary NameNode的快照功能,可以将NameNode的宕机时间和数据损失降低到最小。同时,如果NameNode发生问题,Secondary NameNode可以及时地作为备用NameNode使用。
3.1
NameNode的目录结构如下:
${dfs.name.dir}/current/VERSION
/edits
/fsimage
/fstime
3.2
Secondary NameNode的目录结构如下:
${fs.checkpoint.dir}/current/VERSION
/edits
/fsimage
/fstime
/previous.checkpoint/VERSION
/edits
/fsimage
/fstime
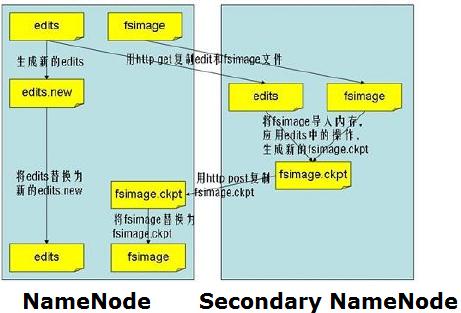
如上图,Secondary NameNode主要是做Namespace image和Edit log合并的。
那么这两种文件是做什么的?当客户端执行写操作,则NameNode会在edit log记录下来,(我感觉这个文件有些像Oracle的online redo logo file)并在内存中保存一份文件系统的元数据。
Namespace image(fsimage)文件是文件系统元数据的持久化检查点,不会在写操作后马上更新,因为fsimage写非常慢(这个有比较像datafile)。
由于Edit log不断增长,在NameNode重启时,会造成长时间NameNode处于安全模式,不可用状态,是非常不符合Hadoop的设计初衷。所以要周期性合并Edit log,但是这个工作由NameNode来完成,会占用大量资源,这样就出现了Secondary NameNode,它可以进行image检查点的处理工作。步骤如下:
(1) Secondary NameNode请求NameNode进行edit log的滚动(即创建一个新的edit log),将新的编辑操作记录到新生成的edit log文件;
(2) 通过http get方式,读取NameNode上的fsimage和edits文件,到Secondary NameNode上;
(3) 读取fsimage到内存中,即加载fsimage到内存,然后执行edits中所有操作(类似OracleDG,应用redo log),并生成一个新的fsimage文件,即这个检查点被创建;
(4) 通过http post方式,将新的fsimage文件传送到NameNode;
(5) NameNode使用新的fsimage替换原来的fsimage文件,让(1)创建的edits替代原来的edits文件;并且更新fsimage文件的检查点时间。
整个处理过程完成。
Secondary NameNode的处理,是将fsimage和edites文件周期的合并,不会造成nameNode重启时造成长时间不可访问的情况。
4、JobTracker介绍
JobTracker后台程序用来连接应用程序与Hadoop。用户代码提交到集群以后,由JobTracker决定哪个文件将被处理,并且为 不同的task分配节点。同时,它还监控所有的task,一旦某个task失败了,JobTracker就会自动重新开启这个task,在大多数情况下这 个task会被放在不用的节点上。每个Hadoop集群只有一个JobTracker,一般运行在集群的Master节点上。
下面我们详细介绍:
4.1JobClient
我们配置好作业之后,就可以向JobTracker提交该作业了,然后JobTracker才能安排适当的TaskTracker来完成该作业。那么MapReduce在这个过程中到底做了那些事情呢?这就是本文以及接下来的一片博文将要讨论的问题,当然本文主要是围绕客户端在作业的提交过程中的工作来展开。先从全局来把握这个过程吧!
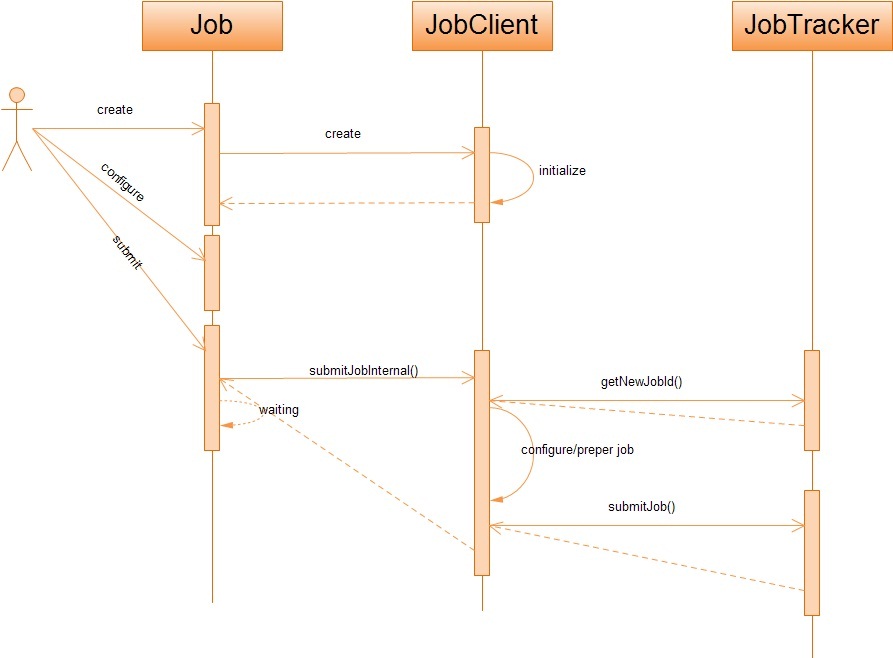
在Hadoop中,作业是使用Job对象来抽象的,对于Job,我首先不得不介绍它的一个大家伙JobClient——客户端的实际工作者。JobClient除了自己完成一部分必要的工作外,还负责与JobTracker进行交互。所以客户端对Job的提交,绝大部分都是JobClient完成的,从上图中,我们可以得知JobClient提交Job的详细流程主要如下:
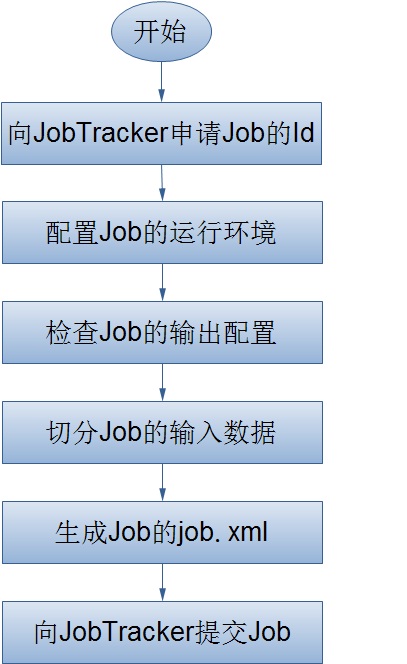
JobClient在获取了JobTracker为Job分配的id之后,会在JobTracker的系统目录(HDFS)下为该Job创建一个单独的目录,目录的名字即是Job的id,该目录下会包含文件job.xml、job.jar、job.split等,其中,job.xml文件记录了Job的详细配置信息,job.jar保存了用户定义的关于job的map、reduce操纵,job.split保存了job任务的切分信息。在上面的流程图中,我想详细阐述的是JobClient是任何配置Job的运行环境,以及如何对Job的输入数据进行切分。
4.2
JobTracker
上面谈到了客户端的JobClient对一个作业的提交所做的工作,那么这里,就要好好的谈一谈JobTracker为作业的提交到底干了那些个事情——一.为作业生成一个Job;二.接受该作业。
我们都知道,客户端的JobClient把作业的所有相关信息都保存到了JobTracker的系统目录下(当然是HDFS了),这样做的一个最大的好处就是客户端干了它所能干的事情同时也减少了服务器端JobTracker的负载。下面就来看看JobTracker是如何来完成客户端作业的提交的吧!哦。对了,在这里我不得不提的是客户端的JobClient向JobTracker正式提交作业时直传给了它一个改作业的JobId,这是因为与Job相关的所有信息已经存在于JobTracker的系统目录下,JobTracker只要根据JobId就能得到这个Job目录。
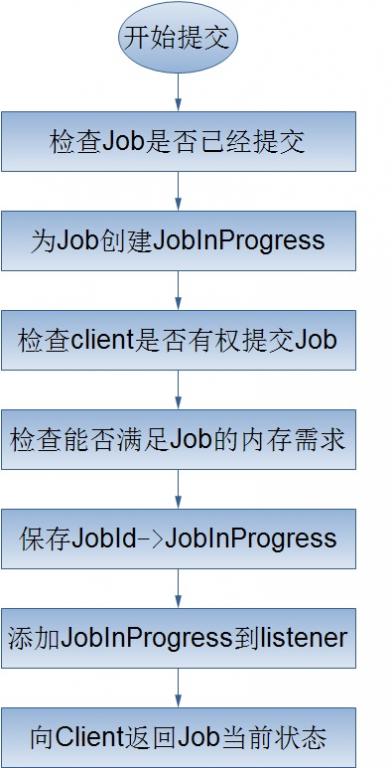
对于上面的Job的提交处理流程,我将简单的介绍以下几个过程:
为了做好运维面试路上的助攻手,特整理了上百道 【运维技术栈面试题集锦】 ,让你面试不慌心不跳,高薪offer怀里抱!
这次整理的面试题,小到shell、MySQL,大到K8s等云原生技术栈,不仅适合运维新人入行面试需要,还适用于想提升进阶跳槽加薪的运维朋友。

本份面试集锦涵盖了
- 174 道运维工程师面试题
- 128道k8s面试题
- 108道shell脚本面试题
- 200道Linux面试题
- 51道docker面试题
- 35道Jenkis面试题
- 78道MongoDB面试题
- 17道ansible面试题
- 60道dubbo面试题
- 53道kafka面试
- 18道mysql面试题
- 40道nginx面试题
- 77道redis面试题
- 28道zookeeper
总计 1000+ 道面试题, 内容 又全含金量又高
- 174道运维工程师面试题
1、什么是运维?
2、在工作中,运维人员经常需要跟运营人员打交道,请问运营人员是做什么工作的?
3、现在给你三百台服务器,你怎么对他们进行管理?
4、简述raid0 raid1raid5二种工作模式的工作原理及特点
5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
7、Tomcat和Resin有什么区别,工作中你怎么选择?
8、什么是中间件?什么是jdk?
9、讲述一下Tomcat8005、8009、8080三个端口的含义?
10、什么叫CDN?
11、什么叫网站灰度发布?
12、简述DNS进行域名解析的过程?
13、RabbitMQ是什么东西?
14、讲一下Keepalived的工作原理?
15、讲述一下LVS三种模式的工作过程?
16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
17、如何重置mysql root密码?
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
epalived的工作原理?
15、讲述一下LVS三种模式的工作过程?
16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
17、如何重置mysql root密码?
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









