



 本文详细介绍了并发标记清除算法中的初始标记过程,包括从根集合和新生代查找活跃对象,以及使用标记位图和内存块划分提高效率。同时讨论了并发标记时可能出现的标记栈溢出处理及其优化策略。
本文详细介绍了并发标记清除算法中的初始标记过程,包括从根集合和新生代查找活跃对象,以及使用标记位图和内存块划分提高效率。同时讨论了并发标记时可能出现的标记栈溢出处理及其优化策略。
并发标记清除之初始标记
初始标记是对老生代中活跃对象进行标记的第一步,仅仅收集从老生代外部指向老生代的活跃对象,这些对象构成了初始标记的输出,并作为下一步并发标记的输入。下面通过一个简单的例子来介绍初始标记的思路。假设堆内存在执行初始标记前如图4-24所示。
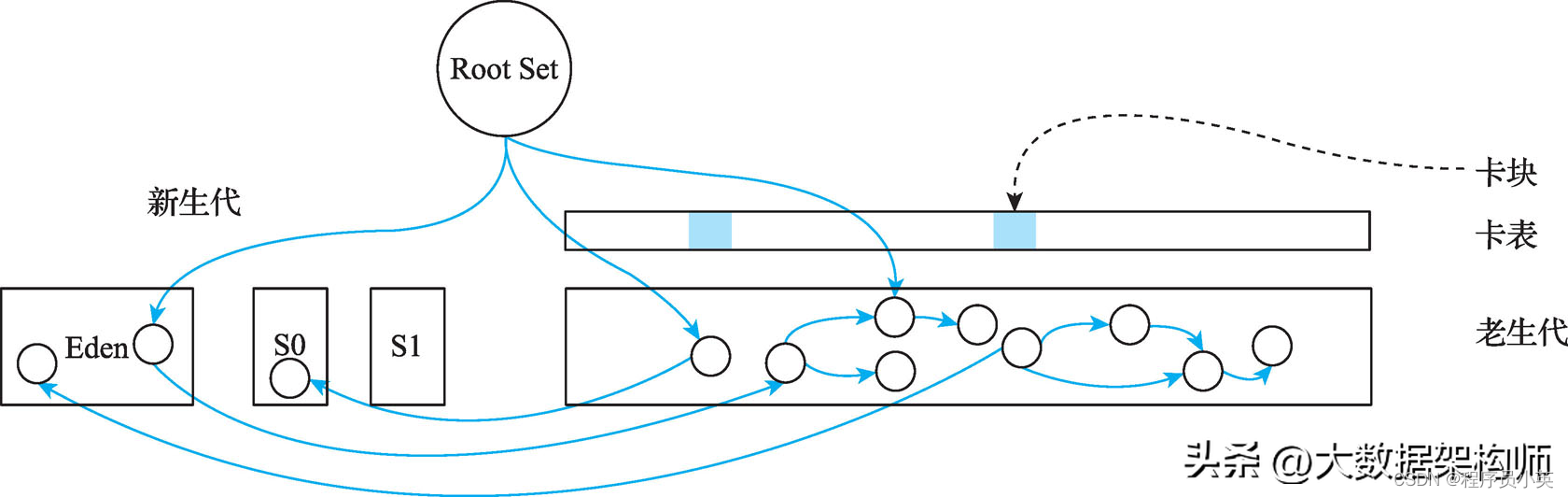
图4-24 堆内存初始状态
初始标记是寻找老生代外部指向老生代的活跃对象。对垃圾回收算法来说,有以下两种实现方法:
1)从根集合出发遍历根集合,找到是否存在指向老生代的对象引用,如果存在引用则直接作为根输出。在遍历过程中需要遍历新生代所有对象才能知道是否有指向老生代的对象引用。
2)直接将新生代作为根,和其他的根集合一样判断是否存在指向老生代的对象引用,如果存在引用则直接作为输出。
第一种方法能准确地识别老生代中的活跃对象,但是需要遍历整个新生代,会导致初始标记耗时较长;第二种方式会存在一定的误差,可能将新生代中已经死亡的对象作为根,导致老生代中存在浮动垃圾,但是该方法仅需较短的时间就可以完成初始标记。不同的垃圾回收实现中可能采用不同的实现细节,比如OpenJ9中的gencon采用第一种方法,而JVM的CMS采用第二种方法。
所以在初始标记时会把根集合和新生代作为老生代活跃对象的根,如果发现引用的对象在老生代中,则把对应的老生代对象标记出来。为了不影响Mutator的运行,不能直接在对象上进行标记,否则需要锁(因为在整个老生代回收周期中对象可能会被修改,Mutator也会访问对象,为了保证正确性,并发访问时需要锁进行同步)。但使用锁将导致性能下降,所以引入了一个标记位图(Bitmap)用于记录活跃对象。在初始标记完成时,通过标记位图记录根集合(含新生代)指向老生代的直接引用。根据堆的初始状态,标记位图中有3个位被设置,其中有两个来自根集合,一个来自新生代,如图4-25所示。
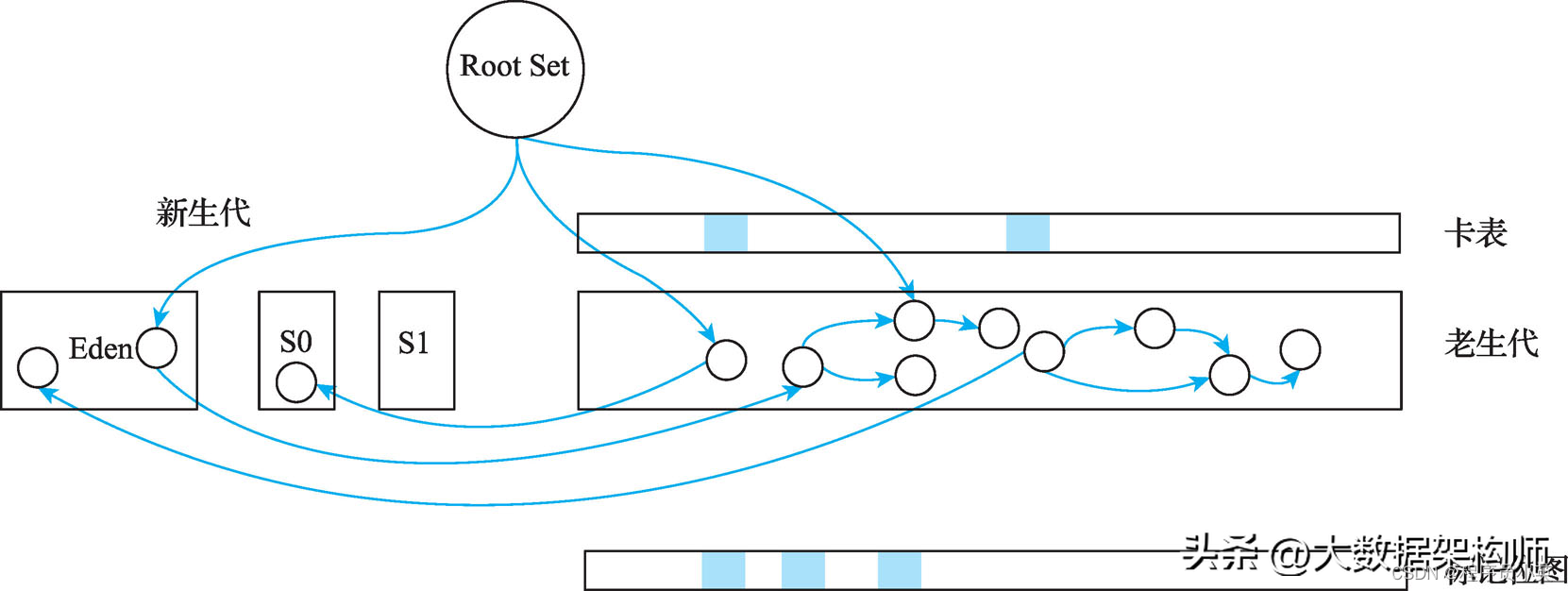
图4-25 标记位图示意图
标记位图的粒度和卡表粒度有所不同,老生代中每个字都有一个位与之对应。
新生代的处理思路也是将新生代划分为多个内存块,由多个线程并行处理。
但是划分的方式与参数设置有关,默认情况下是新生代划分为多个内存块。其中Eden的划分与参数CMSEdenChunksRecordAlways相关(默认值为true),如果参数为false,整个Eden被一个线程处理。关于划分Eden的更多信息在预清理阶段再详细介绍。Survivor的划分与PLAB相关,PLAB是MinorGC并行执行时为防止多线程间同步而引入的,每个线程都有一个缓冲区(称为PLAB),当对象从Eden转移到Survivor时都从PLAB中分配。可以利用这样的特性,在初始标记处理Survivor分区时,每个线程以PLAB大小为粒度进行并行处理(只需要在初始化时按照PLAB大小对Survivor进行划分即可,然后在执行Minor GC时记录每个划分的对象)。
并发标记清除之并发标记
并发标记的输入是初始标记的输出,即标记位图。在并发标记阶段,根据标记位图中的初始活跃对象在老生代中进行遍历,找到老生代中所有活跃的对象。并发标记执行时Mutator正常运行,并发标记本身也是多个线程同时执行标记动作。
为了保证标记的正确性,在并发标记的同时,如果Mutator运行中修改了老生代中对象的引用关系,则会通过卡表的方式进行记录,在并发标记结束后再对卡表记录的对象做额外的标记,从而保证标记的正确性。更多具体信息参考上一节介绍。本节主要关注如何高效地进行并发标记。
针对标记位图高效执行并发标记的思路非常简单,那就是将老生代内存划分成大小一定的块,每个线程处理一个内存块。线程执行标记时,根据内存块对应的标记位图中存在的标记位找到待标记对象,遍历待标记对象的成员变量,直到完成整个老生代内存块的处理,此时老生代中所有活跃对象都被标记。内存块的大小通过参数CMSConcMarkMultiple控制,默认值为32,表示内存块的大小为32×4KB=128KB。
下面通过一个例子来介绍一下并发标记。假设初始标记后标记位图中有两个标记位被设置,分别对应对象A和B。在并发标记中,首先对老生代进行划分,假设老生代被划分为n个内存块,其中第一个内存无标记位图。同时假设有3个线程T0、T1和T2,分别对内存块进行处理。T0在执行时在标记位图中找不到标记对象,所以T0会跳过内存块0,然后寻找下一个可用的内存块。T1和T2分别处理内存块1和内存块2,如图4-26所示。
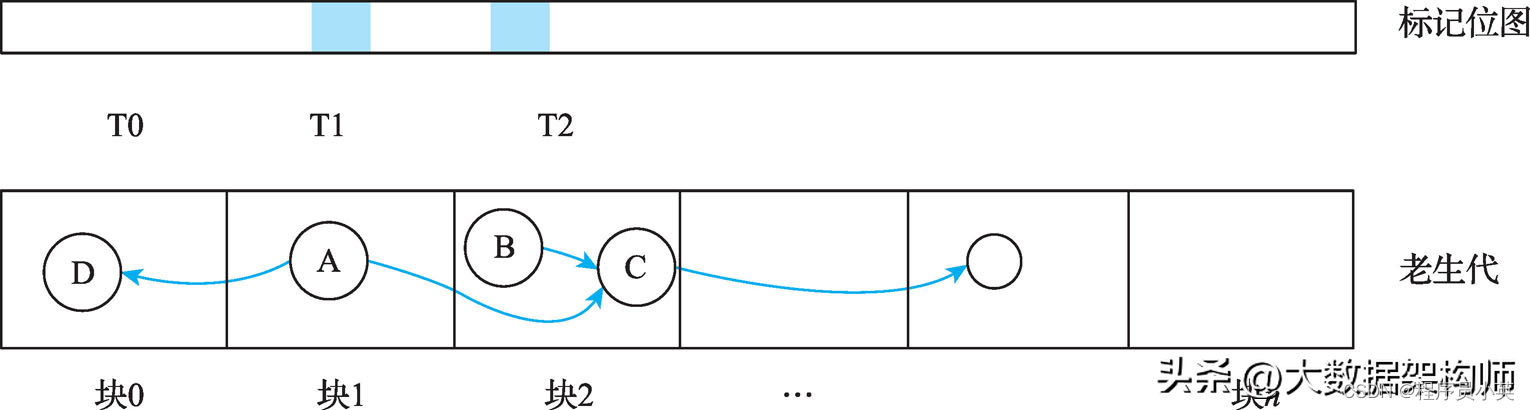
图4-26 并发标记示意图
在图4-26中可以看到,对象A引用到内存块0和内存块2中的对象,同时对象B也引用到内存块2的对象。对象A和对象B分别由T1和T2进行遍历标记,可能存在T1和T2需要同时标记对象C的情况,因此两个线程需要竞争访问对象C,在标识时通过对标记位图的竞争来确定谁来处理对象C,所以对象的标记可能由T1执行,也可能由T2执行。另外,对象A还有一个指向块0的对象D,也需要被标记,也是由T1处理。
线程在进行标记时通过线程的局部标记栈来保存待进一步标记的对象。在并发标记中,如果遇到线程局部标记栈溢出的问题,并发标记的处理思路和其他标记的处理思路并不相同。并发标记如果遇到标记栈溢出的情况,会记录溢出对象的地址,当前并发标记执行结束后如果发现标记栈溢出,会再次进入并发标记并从溢出对象开始向后重新遍历标记整个空间的对象。当有多个线程同时发生标记栈溢出时,将地址最低的对象作为重新开始标记的起点。在并发标记中发生标记栈溢出会导致成本提高,可能需要做大量无用的重复遍历工作。
那么为什么并发标记中标记栈溢出处理和其他标记中的处理方式均不相同?最主要的原因还是并发操作带来的复杂性。例如下面介绍的再标记阶段也是多线程执行,也可能存在标记栈溢出的情况,但是再标记阶段可以通过额外的技术来处理标记栈溢出的情况。这里先不展开介绍,在本章扩展阅读中会对标记栈溢出展开介绍。
并发标记的整体算法如上所述,但是在处理每个内存块时还是进行了一个小小的优化。具体来说就是,当处理本内存块中的标记对象时,会从起始地址到结束地址逐一判断是否需要扫描,如果扫描完成那么增加起始地址的位置用finger表示。一个简单的例子如图4-27所示。
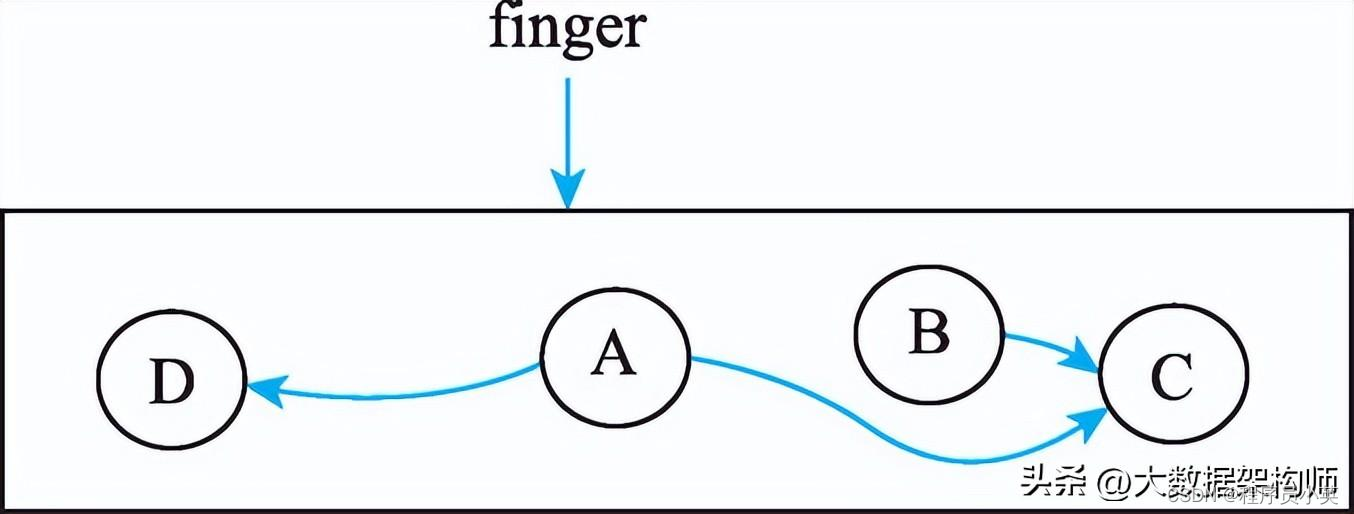
图4-27 一个内存块中并发标记处理优化示意图
当标记对象A时,finger指向对象A的起始地址,A有两个对象引用,分别是对象C和对象D,在标记时仅会处理对象D(包含标记对象D并遍历标记对象D的成员变量),但是对于对象C,仅仅标记而不遍历标记其成员变量。
首先,这样的设计在正确性方面是没有问题的,当对象A处理完成后,对象C位于尚未遍历的内存空间中,即对象C在后续的处理中还会被遍历到。那么为什么要这样设计?为什么不直接按照深度遍历标记对象C?其主要目的是减少标记栈的溢出。在标记栈溢出时,并发标记会从最低地址对象重新开始继续标记,成本相对比较高。本质上该优化是将原本可以深度遍历的对象转换为宽度遍历。

















 768
768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









