



 本文详细介绍了如何在Linux中新建虚拟机,包括内存优化、最小化安装、删除无用硬件;修改主机名并重启,配置静态IP和SSH连接,以及关闭和管理防火墙。后续还指导了如何克隆虚拟机并调整内存设置。
本文详细介绍了如何在Linux中新建虚拟机,包括内存优化、最小化安装、删除无用硬件;修改主机名并重启,配置静态IP和SSH连接,以及关闭和管理防火墙。后续还指导了如何克隆虚拟机并调整内存设置。
一、在Linux中新建一个虚拟机
在新建虚拟机是处理数量和内核数量建议内存大点,选择两个处理器和内核,虚拟机内存为4GB。安装时选择最小安装,新建虚拟机后把没有用的硬件删掉。如;USB控制器、声卡、打印机
二、修改主机名
直接用root用户输入
hostnameectl set-hostname 主机名
修改完主机名后重启虚拟机
第一台虚拟机为:master
三、配置静态固定IP
查看主机IP地址
ip addr
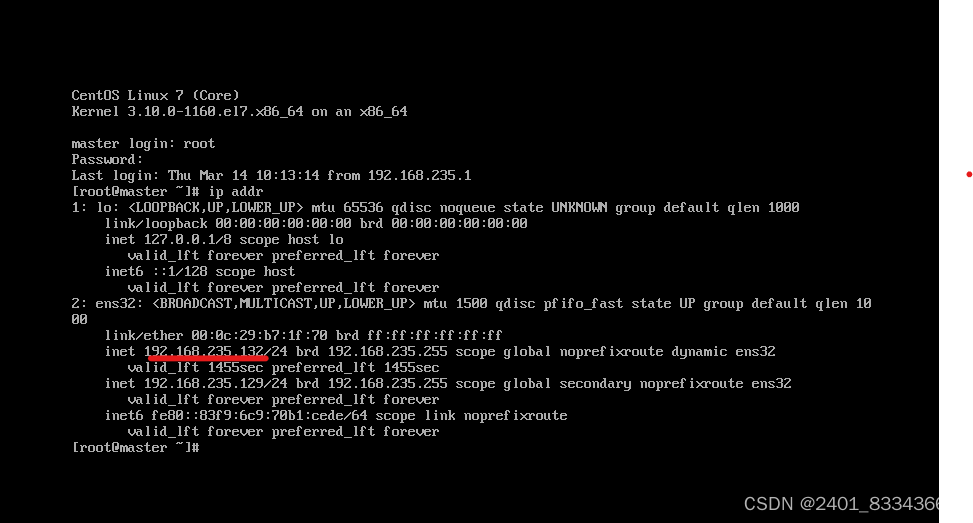
用如下命令编辑网卡配置文件
vi /etc/sysconfig/network-scripts/ifcfg-ens32
使用以下命令重启网络
systemctl restart network
四、连接SSH服务term
打开MobaXterm,点击左上角Session,选择SSH
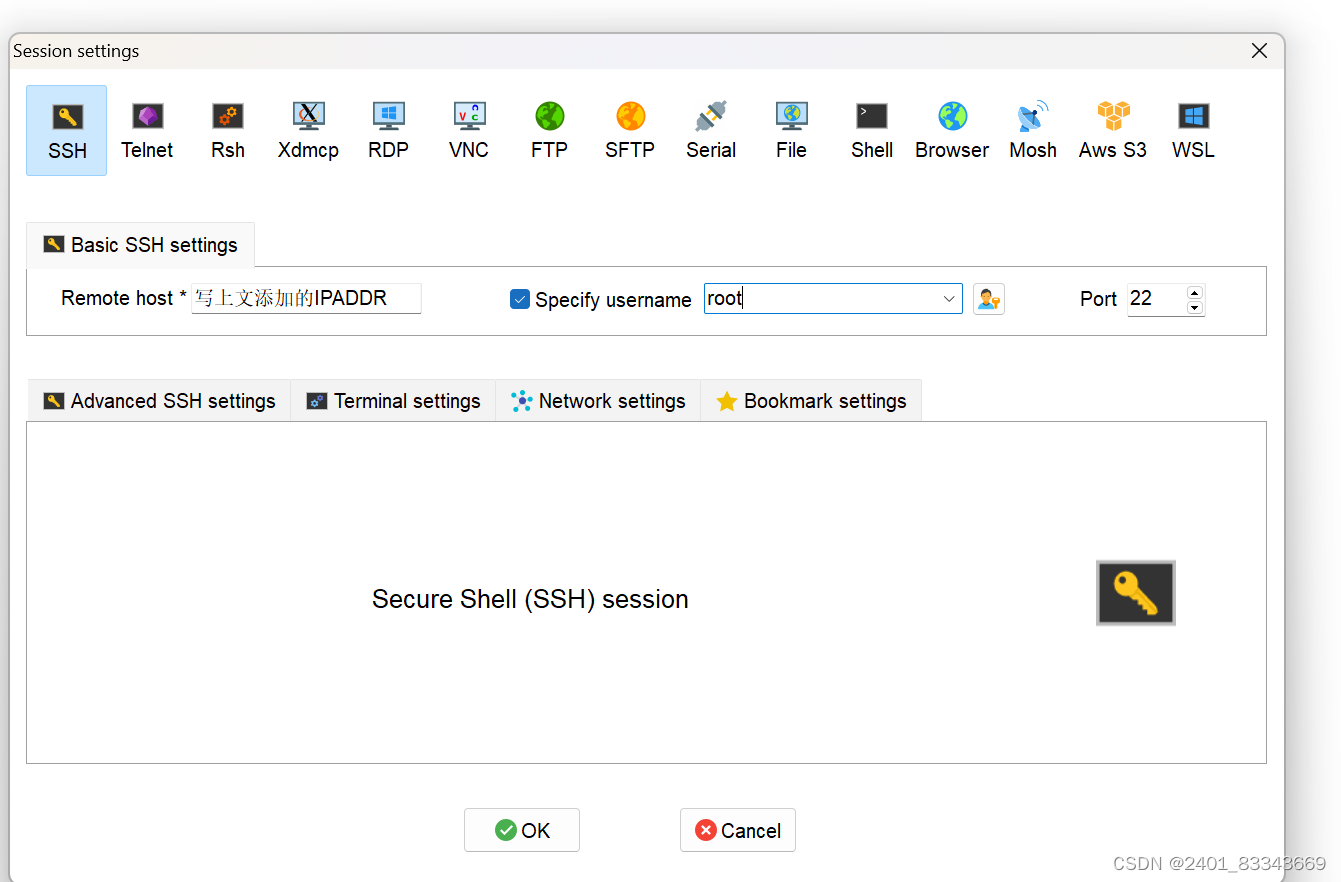
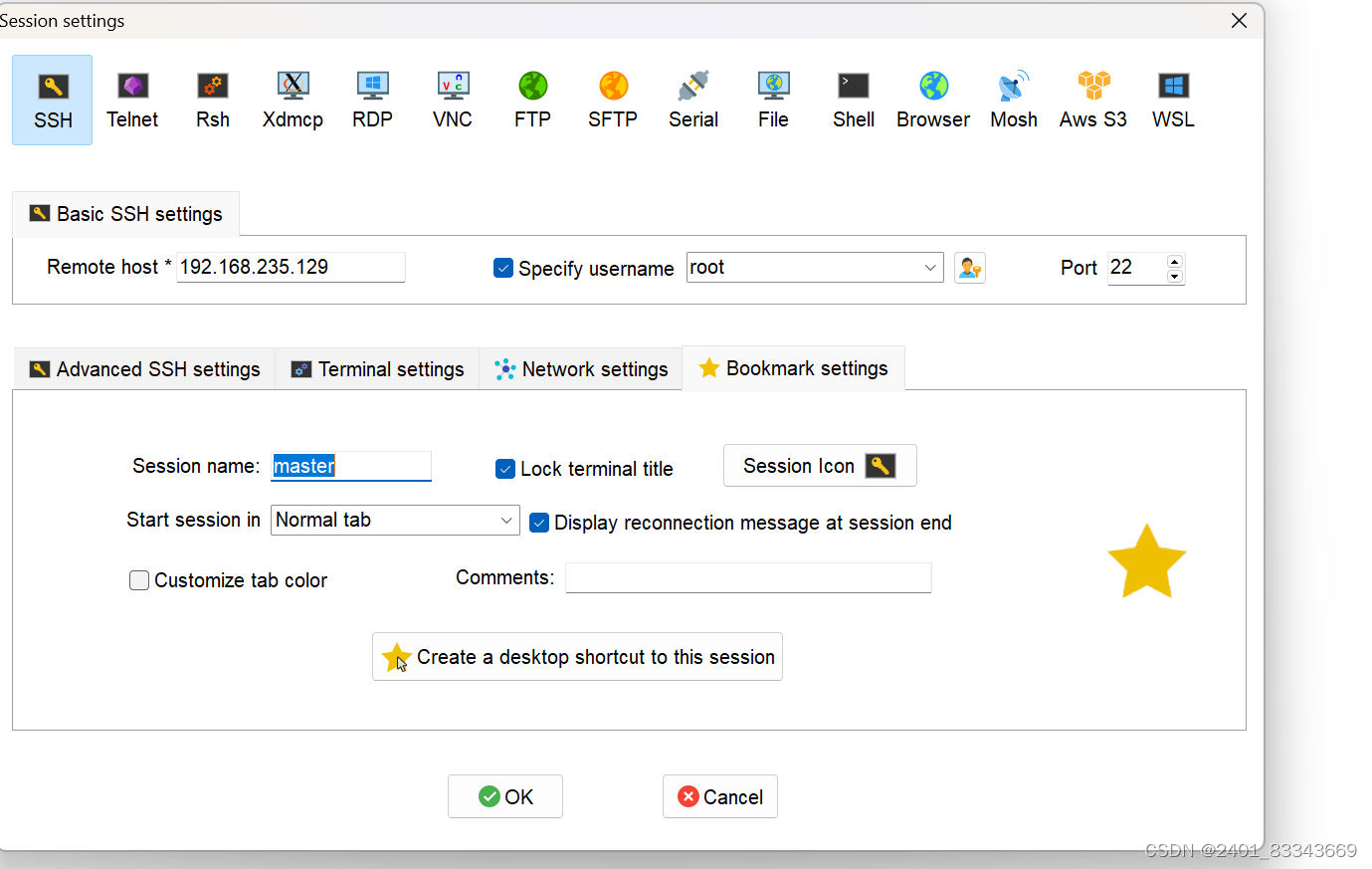
五、关闭防火墙状态
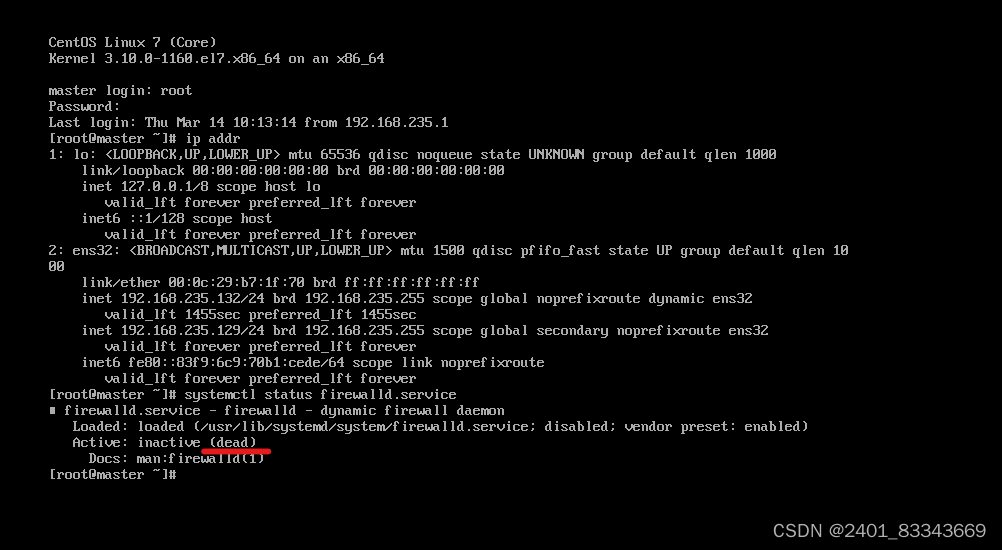
查看防火墙状态
systemctl status firewalld.service
停止防火墙
systemctl stop firewalld.service
关闭防火墙
systemctl disable firewalld.service
再次查看防火墙状态,如图显示dead则防火墙关闭成功
六、按如上步骤在克隆两个虚拟机改名为slave1、slave2
克隆的两个虚拟机可以修改内存为1GB

















 2571
2571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









