



多分类任务评估指标详解
以下是对多分类任务中核心指标的详细说明,包括其作用、计算方法、适用场景及对比分析。
1. Weighted/Macro/Micro F1
作用:
-
综合评估分类器在精确率(Precision)和召回率(Recall)之间的平衡性能,适用于多类别分类任务。
计算方法:
-
F1 分数:
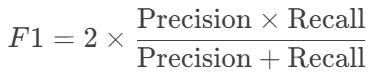
其中:
-
Precision(精确率):正确预测的正类占所有预测为正类的比例。
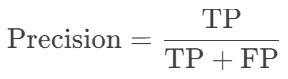
-
Recall(召回率):正确预测的正类占所有真实正类的比例。
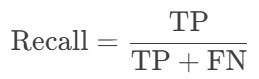
-
-
多分类扩展:
-
Macro-F1:对每个类别的F1取算术平均。
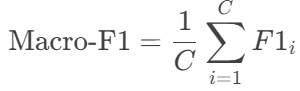
-
Micro-F1:汇总所有类别的TP、FP、FN后计算全局F1。

-
Weighted-F1:按每个类别的样本数量加权平均F1。
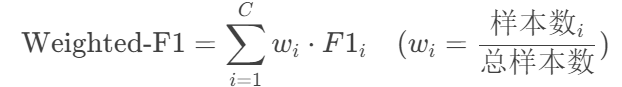
-
评估目标:
-
Macro-F1:平等对待所有类别,适合类别均衡的场景。
-
Micro-F1:关注整体样本的准确性,适合类别不平衡但需全局评估的任务。
-
Weighted-F1:按类别重要性(样本量)加权,适合不平衡数据且需反映类别权重的场景。
示例:
-
类别分布:A(100样本)、B(50样本)、C(20样本)。
-
Macro-F1:三类的F1分别为0.8、0.7、0.6 → Macro-F1 = (0.8+0.7+0.6)/3 = 0.7。
-
Weighted-F1:权重为100/170、50/170、20/170 → 0.8×100/170 + 0.7×50/170 + 0.6×20/170 ≈ 0.75。
-
2. AUROC(多分类加权ROC-AUC)
作用:
-
评估分类器在不同阈值下区分正类和负类的整体能力,尤其关注排序质量(将正类样本排在负类前)。
计算方法:
-
二分类ROC-AUC:
-
计算每个阈值下的TPR(真正率)和FPR(假正率):
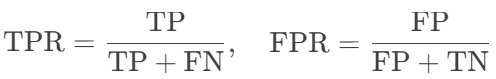
-
绘制ROC曲线,计算曲线下面积(AUC)。
-
-
多分类扩展:
-
加权策略(OvR, One-vs-Rest):
-
对每个类别
,将其视为正类,其他类为负类,计算二分类ROC-AUC。
-
按类别样本量加权平均:
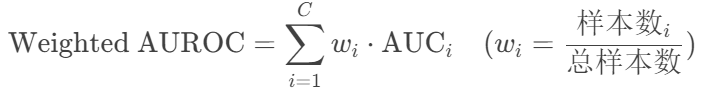
-
-
评估目标:
-
模型对各类别的排序能力,高AUROC表示模型能有效区分不同类别。
-
适用场景:需要高置信度排序的任务(如推荐系统TOP-N推荐)。
示例:
-
三分类任务中,各类别AUC分别为0.9(A类)、0.8(B类)、0.7(C类),样本量分别为100、50、20。
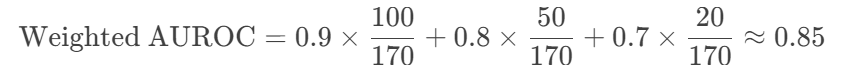
3. AUPRC(多分类加权PR-AUC)
作用:
-
评估分类器在不同阈值下的精确率-召回率平衡,尤其适合类别不平衡的任务。
计算方法:
-
二分类PR-AUC:
-
计算不同阈值下的Precision和Recall。
-
绘制PR曲线,计算曲线下面积(AUC)。
-
-
多分类扩展:
-
加权策略(同AUROC):
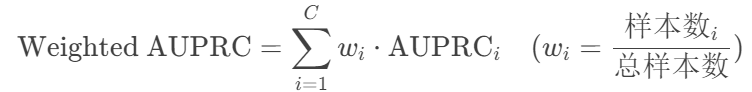
-
评估目标:
-
模型在不平衡数据中识别正类的能力,高AUPRC表示模型在少数类上表现良好。
-
适用场景:医疗诊断(少数病例检测)、欺诈检测(罕见事件)。
示例:
-
若某罕见病分类的AUPRC为0.6,虽低于AUROC的0.85,但在此类任务中可能更关键。
4. Accuracy(准确率)
作用:
-
直观衡量模型整体预测正确的比例,适用于类别分布均衡的任务。
计算:

评估目标:
-
模型的整体预测正确性。
-
缺点:在类别不平衡时,可能虚高(如99%样本为负类,全预测负类Accuracy=99%)。
示例:
-
三分类任务中,90个样本预测正确,总样本100 → Accuracy=90%。
5. Weighted Precision/Recall
作用:
-
按类别样本量加权评估精确率和召回率,反映类别重要性。
计算:
-
Weighted Precision:
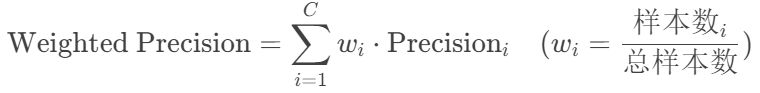
-
Weighted Recall:
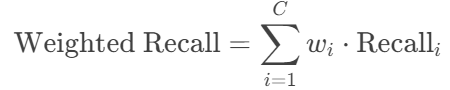
评估目标:
-
模型在重要类别(大样本类)上的性能。
-
适用场景:电商商品分类(热销品类更重要)。
指标对比与选择建议
| 指标 | 核心优势 | 局限性 | 适用场景 |
|---|---|---|---|
| Macro-F1 | 平等对待所有类别 | 易受小类别性能影响 | 类别均衡、需公平评估各类 |
| Micro-F1 | 反映全局样本表现 | 可能掩盖小类别问题 | 类别略不平衡、关注整体准确性 |
| Weighted-F1 | 按样本量加权,贴近实际影响 | 忽视小类别重要性 | 类别不平衡、需反映样本分布 |
| Weighted AUROC | 评估排序能力,适合阈值敏感任务 | 计算复杂度高 | 推荐系统、高置信度排序需求 |
| Weighted AUPRC | 对类别不平衡敏感,关注正类识别 | 对多数类性能不敏感 | 医疗诊断、欺诈检测等罕见事件 |
| Accuracy | 简单直观,易于解释 | 类别不平衡时误导性高 | 类别均衡、初步模型评估 |
| Weighted Precision/Recall | 按重要性加权,贴近业务需求 | 可能忽略小类别的关键性能 | 电商分类、客户分层管理 |
总结
-
全面评估策略:
-
基础性能:Accuracy + Micro-F1(全局视角)。
-
类别平衡性:Macro-F1 + Weighted-F1(公平性与重要性平衡)。
-
排序能力:Weighted AUROC(如推荐系统)。
-
不平衡数据:Weighted AUPRC + Weighted Precision/Recall(如医疗诊断)。
-
-
避免单一指标依赖:结合业务需求选择组合,例如:
-
医疗领域:AUPRC + Weighted Recall(确保疾病检出率)。
-
推荐系统:AUROC + Micro-F1(兼顾排序与整体准确性)。
-

















 1950
1950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









