






 本文探讨了Dubbo框架中的服务容错机制,重点分析了Dubbo的集群结构和Cluster接口,特别是FailoverCluster的实现。FailoverCluster通过失败重试策略确保服务的高可用性,涉及Invoker、Directory、Router、LoadBalance等核心组件,以及粘滞连接、负载均衡和重试逻辑。
本文探讨了Dubbo框架中的服务容错机制,重点分析了Dubbo的集群结构和Cluster接口,特别是FailoverCluster的实现。FailoverCluster通过失败重试策略确保服务的高可用性,涉及Invoker、Directory、Router、LoadBalance等核心组件,以及粘滞连接、负载均衡和重试逻辑。
在分布式系统构建过程中,我们需要重点关注和处理的就是服务依赖失败。服务依赖失败较之服务自身失败而言影响更大,也更加难以发现和处理。为了应对服务依赖失败,我们需要引入服务容错(Fault Tolerance)的思想和实现机制。
服务容错是一个相对复杂的话题,也是一个理论性比较强的话题。那么,我们如何来理解服务容错的设计策略和实现原理呢?最好的办法就是参考优秀开源框架中的做法。这就是今天要讨论的内容,我们将基于Dubbo框架来剖析它所具备的服务容错机制。
Dubbo中的集群
服务容错的实现方法和策略有很多,我们首先明确在Dubbo中主要采用的是集群容错的实现策略。
Dubbo中的整个集群结构如下图所示。这张图比较复杂,涉及到Dubbo中关于集群管理和服务调用的诸多概念。为了讨论集群容错,我们必须首先理解这种图中的相关概念,进而把握Dubbo对集群的抽象。
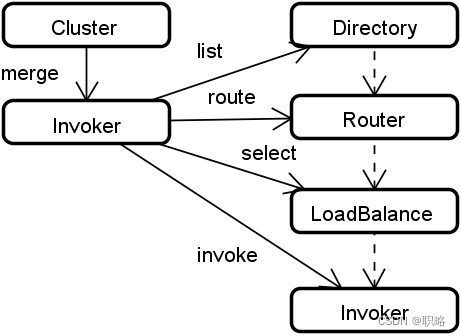
上图展现了Dubbo中的几个重要技术组件,我们一一来展开。
- Invoker:在Dubbo中,Invoker是一个核心概念,代表的就是一个具体的可执行对象;
- Directory:即目录,代表一个集合,内部包含了一组Invoker对象;
- Router:即路由器,根据路由规则在一组Invoker中选出符合规则的一部分Invoker;
- LoadBalance:即负载均衡,对经过Router过滤之后的一部分Invoker执行各种负载均衡算法,从而确定一个具体的Invoker;
- Cluster:即集群,从Directory中获取一组Invoker,并对外伪装成一个Invoker。这样,我们在使用Cluster时就像是在使用一个Invoker一样,而在这背后则隐藏了访问容错机制。
基于上述分析,今天内容所要介绍的重点是Cluster。我们首先来看看Dubbo中Cluster接口的定义,该接口只包含一个join方法,如下所示。
@SPI(FailoverCluster.NAME)
public interface Cluster {
@Adaptive
<T> Invoker<T> join(Directory<T> directory) throws RpcException;
}
Cluster接口中包含另一个与集群相关的重要概念,即前面提到的Directory。Directory本质上代表多个Invoker,我们需要知道可以通过它获取一个有效Invoker的列表。
换一个角度,Dubbo中的Cluster也相当于是一种代理对象,它在Directory的基础上向开发人员暴露一个具体的Invoker,而在暴露这个Invoker的过程中,万一发生了异常情况,Cluster就会自动嵌入集群容错机制。那么,Cluster是如何做到这一点的呢?在Dubbo中,实际上提供了一组不同类型的Cluster对象,而每一个Cluster对象就代表一种具体的集群容错机制,如下图所示。
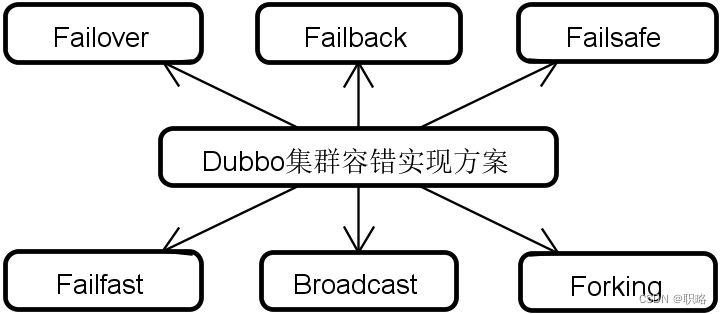
上述方案中,Dubbo默认使用的是FailoverCluster。我们来看一下这个默认实现,如下所示。
public class FailoverCluster implements Cluster {
public final static String NAME = "failover";
public <T> Invoker<T> join(Directory<T> directory) throws RpcException {
return new FailoverClusterInvoker<T>(directory);
}
}
可以看到该类非常简单,join方法只是根据传入的Directory构建一个新的FailoverClusterInvoker实例。而查看其他的Cluster接口实现,可以发现它们的处理方式与FailoverCluster类似,都是返回一个新的Invoker。Dubbo中整个Cluster的类层结构可以通过下图进行展示。
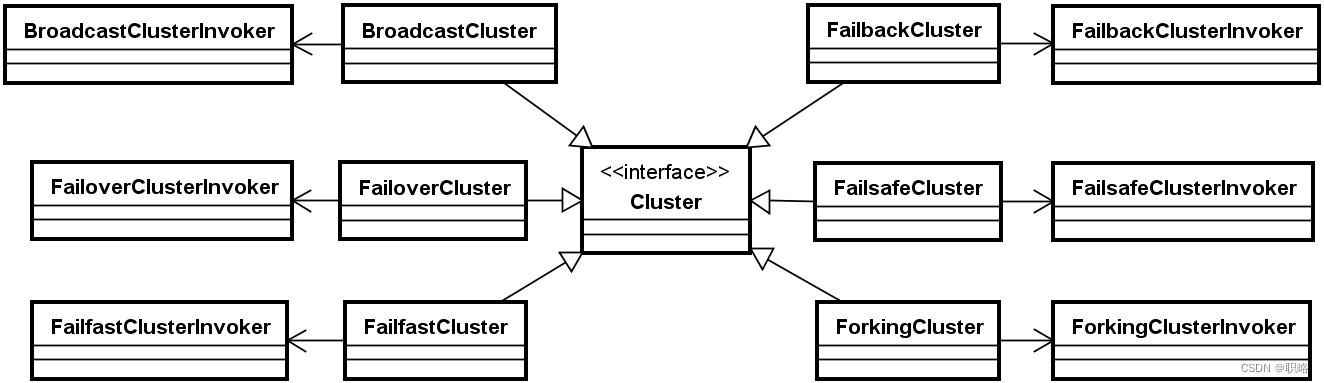
Dubbo中的集群容错机制
显然,想要理解Dubbo中的集群容错机制,重点是要分析上图中所示的各种ClusterInvoker对象。这里,我们同样选择默认的FailoverClusterInvoker作为分析对象。在深入FailoverClusterInvoker之前,我们发现该类存在一个基类,即AbstractClusterInvoker,而AbstractClusterInvoker又实现了Invoker接口。
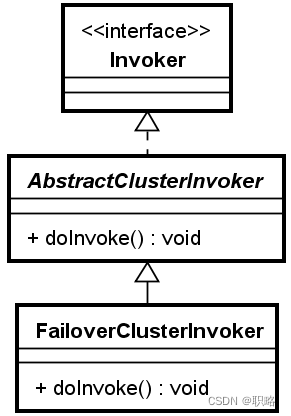
从设计模式角度讲,AbstractClusterInvoker采用的是很典型的模板方法设计模式。模板方法设计模式的一般实现过程就是为整个操作流程提供一种框架代码,然后再提取抽象方法供子类进行实现。上图中就展示了模板方法的设计思想。
AbstractClusterInvoker的实现逻辑也是类似,它的主要步骤包括从Directory获得Invoker列表、基于LoadBalance实现负载均衡,并基于doInvoke方法完成在远程调用中嵌入容错机制。
这里的doInvoke就是模板方法,需要FailoverClusterInvoker等子类分别实现。
public abstract class AbstractClusterInvoker<T> implements ClusterInvoker<T> {
protected abstract Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException;
}
AbstractClusterInvoker类的代码有点长,但理解起来并不是很复杂。通过观察该类中的代码实现,可以看到存在一批以select结尾的方法,包括select、doselect、reselect以及LoadBalance本身的select。我们基于这些select方法梳理整体的处理流程,并给出如下所示的伪代码。
select() {
checkSticky();//粘滞连接
doselect() {
loadbalance.select();
reselect() {
loadbalance.select();
}
}
}
上述伪代码清晰展示了这些select方法的嵌套过程,从而能够更好的帮助大家梳理代码执行流程。
首先,select方法的第一部分内容提供了“粘滞连接”机制。所谓粘滞连接(Sticky Connection),就是为每一次请求维护一个状态,确保始终由同一个服务提供者对来自同一客户端的请求进行响应。在Dubbo中,使用粘滞连接的目的是为了减少重复创建连接的成本,提高远程调用的效率。我们可以通过URL传入的“sticky”参数对该行为进行控制。
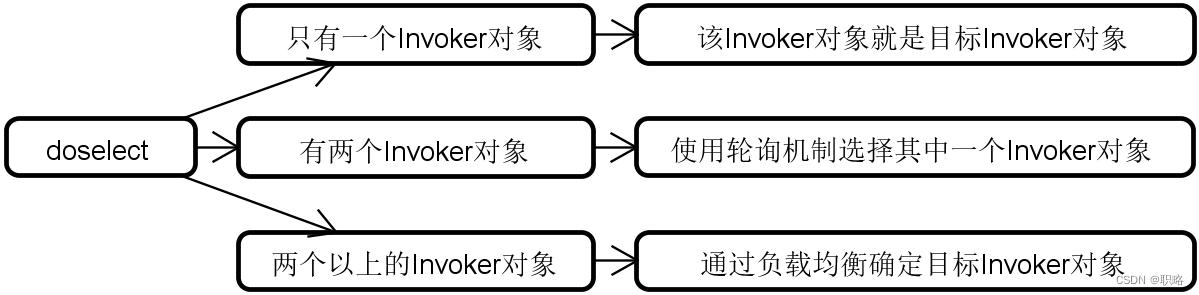
处理完粘滞连接之后,select方法就借助于doselect方法进行下一步操作。doselect方法执行了一系列的判断来最终明确目标Invoker对象。首先,我们需要判断当前是否存在可用的Invoker对象,如果没有则直接返回。如果有,那么就分如下几种情况:
- 如果只有一个Invoker对象,那么该Invoker对象就是目标Invoker对象
- 如果有两个Invoker对象,则使用轮询机制选择其中一个进行返回
- 如果有两个以上的Invoker对象,这时候就会借助于LoadBalance的select方法,通过负载均衡算法那来最终确定一个目标Invoker对象。
下图展示了这个执行过程。
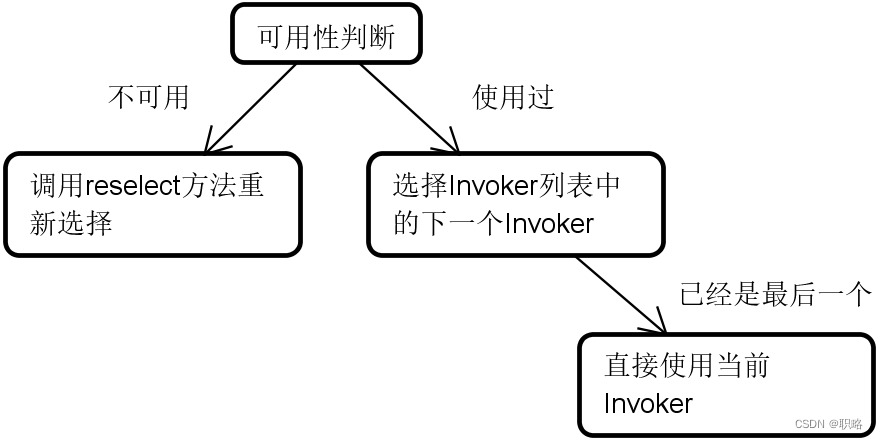
获取了目标Invoker对象之后,Dubbo并不会直接就使用这个对象,因为我们需要考虑该对象的可用性。如果该Invoker对象不可用或者已经使用过,那么就需要通过reselect方法重新进行选择。而如果在Invoker列表中已经没有可用的Invoker对象了,那么也就只能直接使用当前选中的这个Invoker对象。图X进一步展示了Invoker对象的可用性判断逻辑。
至于reselect方法,它的主要机制同样也是借助于LoadBalance的select方法完成对Invoker的重新选择。Dubbo会使用一个标志位用于对传递给LoadBalance的Invoker对象的可用性进行过滤,然后将过滤之后且未被选择的Invoker对象列表交给LoadBalance执行负载均衡。
以上几个方法中,只有select方法的修饰符是protected的,可以被AbstractClusterInvoker的各个子类根据需要进行直接调用。显然,因为AbstractClusterInvoker提供了模板方法,因此它的子类势必是在doInvoke方法中调用这些select方法。
我们来看一下FailoverClusterInvoker的doInvoke方法,这个方法的执行逻辑同样不是很复杂。Failover的意思很简单,就是失败重试,所以可以想象doInvoke方法中应该包括一个重试的循环操作。通过翻阅代码,我们确实发现了这样一个for循环,裁剪后的代码结构如下所示。
for (int i = 0; i < len; i++) {
// 由于Invoker对象列表可能已经发生变化,所以在执行重试操作前需要进行重新选择
if (i > 0) {
// 验证当前Invoker对象是否可用
checkWhetherDestroyed();
// 重新获取所有服务提供者
copyinvokers = list(invocation);
// 重新检查这些Invoker对象
checkInvokers(copyinvokers, invocation);
}
// 通过父类的select方法获取invoker
Invoker<T> invoker = select(loadbalance, invocation, copyinvokers, invoked);
…
try {
// 发起远程调用
Result result = invoker.invoke(invocation);
return result;
} catch (RpcException e) {
// 如果是业务异常,直接抛出
}
…
}
// 如果for循环执行完毕还是没有找到一个合适的invoker,则直接抛出异常
throw new RpcException();
上述代码中的循环次数来自于URL传入的重试次数,默认重试次数是2。在重试之前,由于Invoker对象列表可能已经发生变化,所以需要对当前Invoker对象是否可用进行验证,并根据需要进行重新选择。注意到在每一次循环中,我们首先调用父类AbstractClusterInvoker中的select方法,并将该方法返回的Invoker对象保存到一个invoked集合中,表示该Invoker对象已经被选择和使用。
一旦确定了目标Invoker对象,我们就可以通过该对象所提供的invoke方法执行远程调用。调用过程可能成功也可能失败,而失败的结果也分两种情况,如果是业务失败则直接抛出异常,反之我们就继续执行循环。如果整个循环都结束了还是没有成功的完成调用过程,那么最终也会抛出异常。
至此,基于FailoverClusterInvoker的集群容错机制讲解完毕。Dubbo中的其他集群容错实现方案交由读者自行进行理解和分析。
本讲讨论了Dubbo中的服务容错机制。服务容错是一个很大的主题,也是分布式系统实现过程中必不可少的一个环节。目前市面上关于如何实现服务容错的工具并不是非常多,今天介绍的Dubbo是其中的代表性实现框架。Dubbo中采用的服务容错机制是集群容错。集群容错的实现策略有很多,我们基于Dubbo给出了该框架中内置的Failover集群容错实现方案的底层原理。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









