






现在很多人所谓的本地运行R1教程,基本上都在讲如何部署7B蒸馏版模型,说实话,跟满血R1比起来,这不叫“又笨又慢”,叫“连个资格都不够用”。所以,用第三方服务,几乎成了最优解。
国内已经支持DeepSeek API调用的云服务有百度云、腾讯云、华为云、阿里云等等不过,最适合小白的,还是硅基流动+Chatbox AI的组合,体验无敌,还约等于不要钱。
硅基流动负责部署DeepSeek R1并提供API key,Chatbox AI则是前端对话产品,支持自定义API key,并且有Mac、Win、安卓、IOS四端产品可用,简直是完美的组合。
教程很简单,分两步走: 第一步:获取硅基流动的API key 第二步:下载Chatbox AI并配置
步骤一:获取硅基流动API key
- 登录硅基流动官网硅基流动统一登录,直接进入模型广场
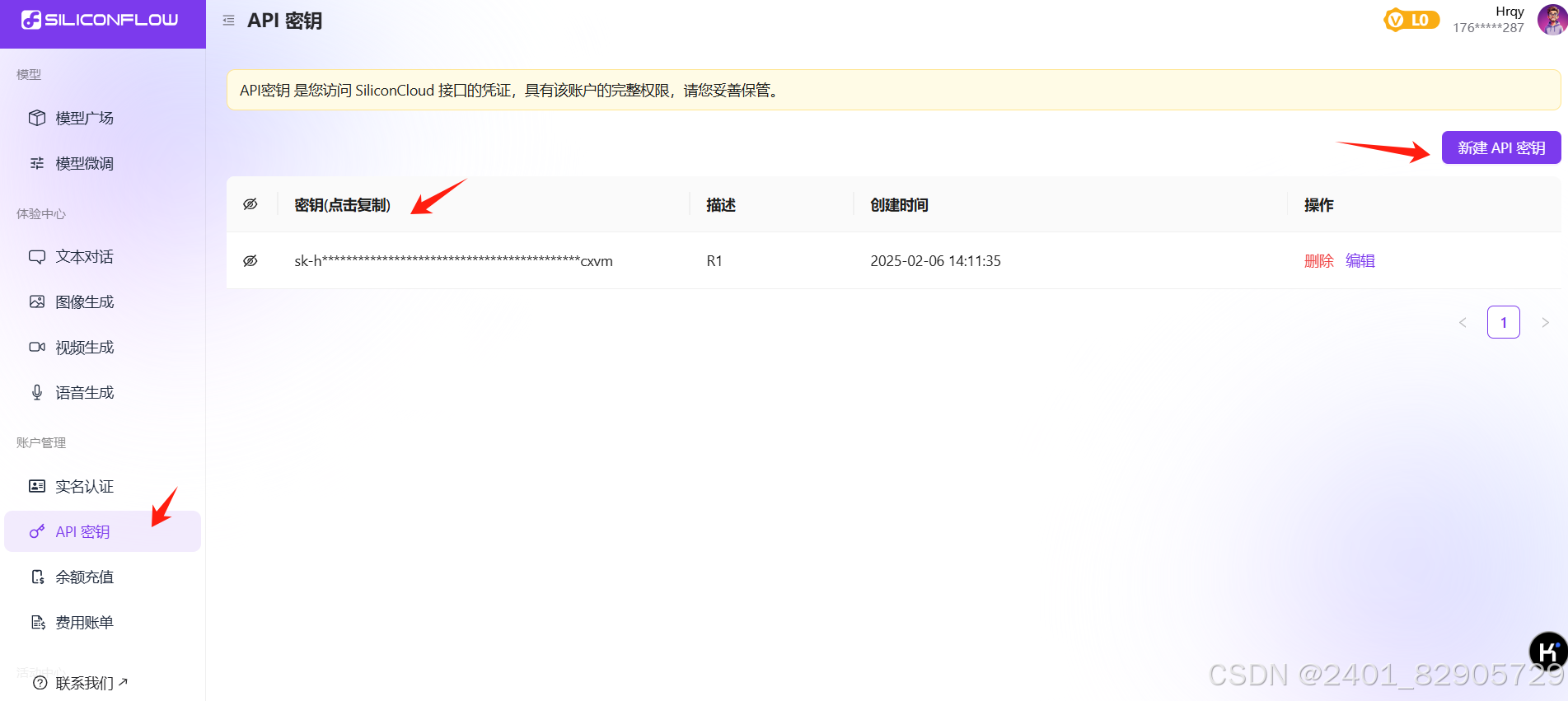
- 在最左边导航栏找到【API密钥】,点击新建API密钥,建个密钥,记得保存密码,方便后面使用,新建完成,得到加密的API Key,复制下来
步骤二:下载Chatbox AI
- 下载链接:Chatbox AI官网:办公学习的AI好助手,全平台AI客户端,官方免费下载
- 根据设备选择客户端, mac/Windows/安卓/iOS都行,网页版也行
- 打开后,点击左下角设置
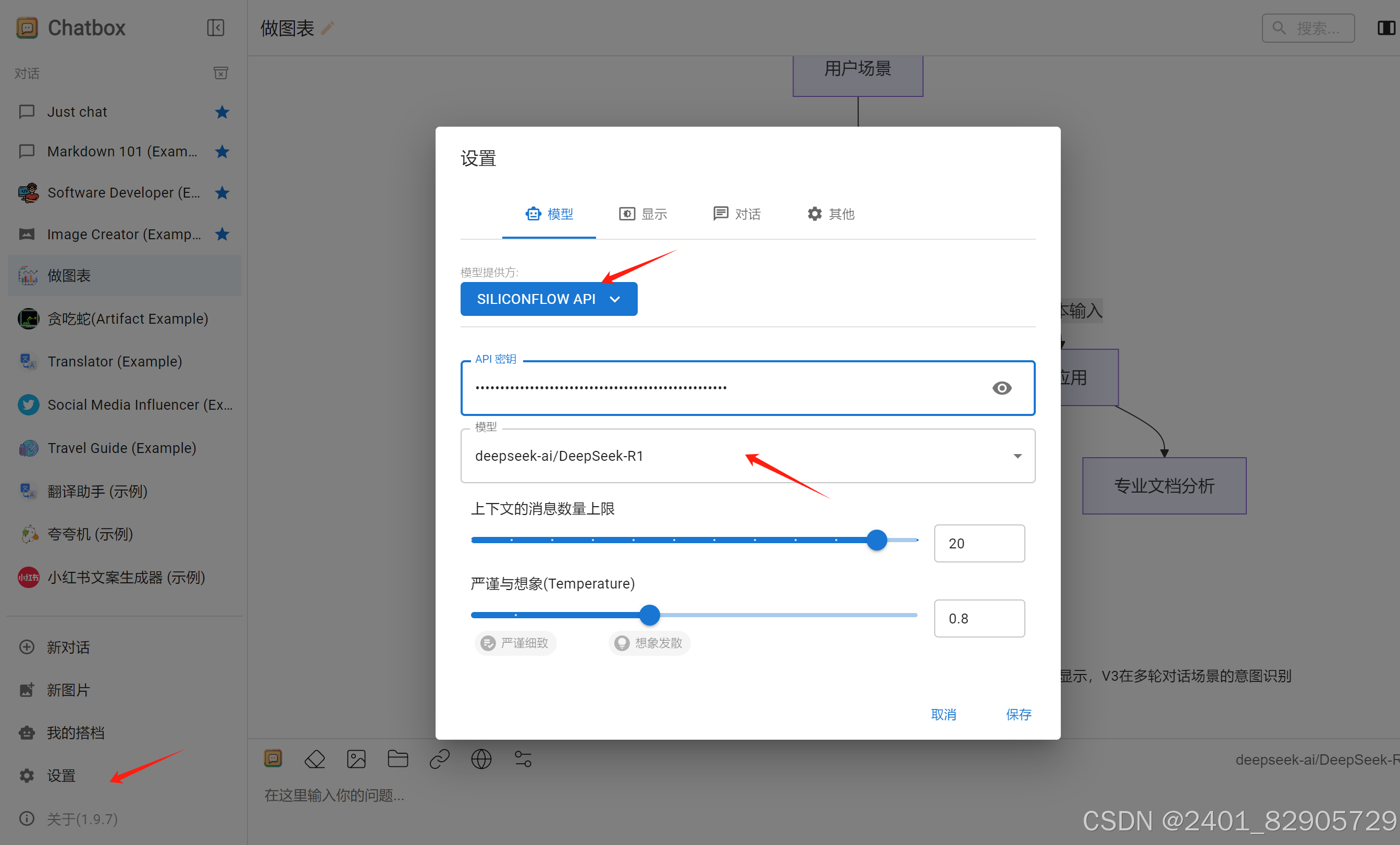
- 在模型提供方里选择SiliconFlow
- 在API密钥里输入刚才复制的密钥
- 选择DeepSeek R1模型,保存后就大功告成了

















 4553
4553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









