






前言:
通过一个多月的shell学习,总共写出30个案例,分批次进行发布,这次总共发布了5个案例,希望能够对大家的学习和使用有所帮助,更多案例会在下期进行发布。
案例六、批量修改指定目录下所有文件的权限
1.问题:
编写一个 Shell 脚本,实现将指定目录及其子目录下的所有文件的权限修改为指定的权限模式(例如 644)。
2.分析:
参数获取:需要获取两个参数,一个是目标目录的路径,另一个是要设置的权限模式(以数字形式表示)。
文件遍历:使用find命令遍历指定目录及其子目录下的所有文件。
权限修改:利用chmod命令将找到的文件权限修改为指定的权限模式。
3.流程图:
4.实现:
#!/bin/bash
# 检查参数个数
if [ $# -ne 2 ]; then
echo "用法: $0 [目标目录] [权限模式]"
exit 1
fi
target_dir="$1"
permission_mode="$2"
# 使用find和chmod修改文件权限
find $target_dir -type f -exec chmod $permission_mode {} +
5.实现解析:
if [ $# -ne 2 ]; then... exit 1:检查参数个数,如果不等于 2,则输出用法信息并退出。这里期望两个参数,分别是目标目录和权限模式。
target_dir="$1"和permission_mode="$2":将命令行传入的参数分别赋值给相应变量。
find $target_dir -type f -exec chmod $permission_mode {} +:find $target_dir -type f:find命令用于在$target_dir目录及其子目录中查找文件。-type f指定只查找文件类型的对象。
-exec chmod $permission_mode {} +:对于find找到的每个文件(用{}表示),执行chmod命令,将其权限修改为$permission_mode指定的模式。+表示将尽可能多的文件名作为参数传递给chmod,提高效率。
6.结果验证:
正确输出脚本结果如下,可以看到该目录内的文件都被修改成777权限

错误输出脚本结果如下:

案例七、比较两个文本文件内容是否相同
1.问题:
编写一个 Shell 脚本,实现对两个指定文本文件进行内容比较,判断它们是否完全一致,并输出相应结果。
2.分析:
参数获取:需要获取两个文件路径作为参数,分别代表要比较的两个文本文件。
比较方法:可以使用diff命令来比较两个文件的内容。如果diff命令没有输出,则表示两个文件内容相同;若有输出,则表示文件内容存在差异。
3.流程图:
4.实现:
#!/bin/bash
# 检查参数个数
if [ $# -ne 2 ]; then
echo "用法: $0 [文件1路径] [文件2路径]"
exit 1
fi
file1="$1"
file2="$2"
# 使用diff比较文件内容
diff_result=$(diff $file1 $file2)
if [ -z "$diff_result" ]; then
echo "两个文件内容相同。"
else
echo "两个文件内容不同,差异如下:"
echo "$diff_result"
fi5.实现解析:
if [ $# -ne 2 ]; then... exit 1:检查参数个数,若不等于 2,则输出脚本用法提示并退出。这里要求两个参数分别为两个要比较的文件路径。
file1="$1"和file2="$2":将命令行传入的两个参数分别赋值给file1和file2变量。
diff_result=$(diff $file1 $file2):使用diff命令比较$file1和$file2两个文件的内容,并将diff命令的输出结果存储在diff_result变量中。
if [ -z "$diff_result" ]; then... else... fi:检查diff_result变量是否为空字符串。如果为空,表示diff命令没有输出,即两个文件内容相同,输出相应信息;若不为空,则表示两个文件内容不同,输出提示信息并显示diff结果。
6.结果验证:
将该脚本文件与上一个案例的脚本文件进行对比
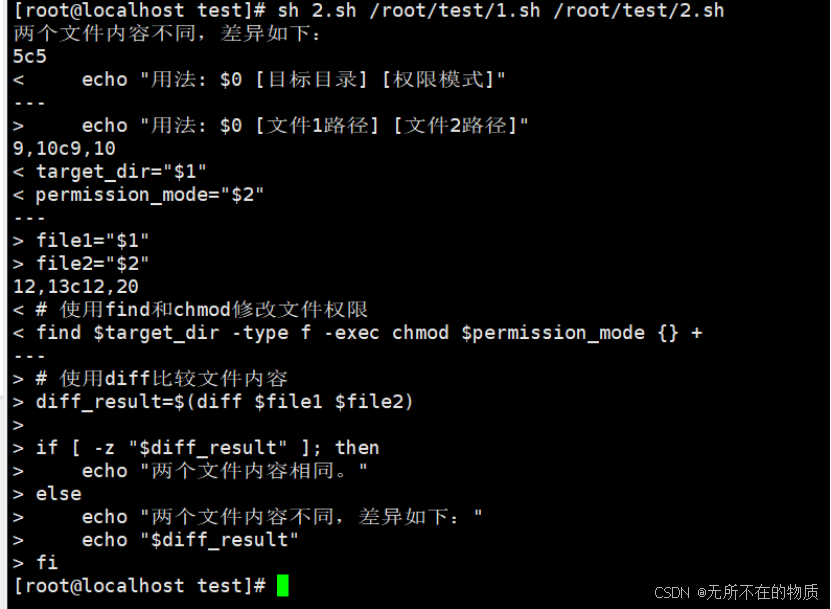
添加一个文件,内容与该案例脚本内容一致,再次执行脚本

案例八、查看网卡实时流量
1.问题:
编写一个 Shell 脚本,用于实时查看网卡的流量信息,包括接收和发送的数据量。
2.分析:
数据获取方式:在 Linux 系统中,可以通过读取/proc/net/dev文件来获取网卡的流量数据。该文件包含了各个网络接口的统计信息。
实时监测需求:使用循环结构和sleep命令来实现每隔一定时间(如每秒)读取并显示网卡流量信息,以达到实时监测的效果。
数据处理:从/proc/net/dev文件内容中提取出需要的网卡流量数据(接收字节数、发送字节数等),并进行适当的格式化输出。
3.流程图:
4.实现:
#!/bin/bash
# 网卡名称,可根据实际情况修改
interface="eno16777736"
# 时间间隔(秒)
interval=1
while true; do
# 读取/proc/net/dev文件内容
net_data=$(cat /proc/net/dev)
# 查找指定网卡行
interface_data=$(echo "$net_data" | grep "$interface:")
if [ -n "$interface_data" ]; then
# 提取接收和发送字节数,这里假设格式固定
receive_bytes=$(echo "$interface_data" | awk '{print $2}')
transmit_bytes=$(echo "$interface_data" | awk '{print $10}')
echo "网卡 $interface - 接收字节数: $receive_bytes - 发送字节数: $transmit_bytes"
else
echo "未找到网卡 $interface 的数据。"
fi
sleep $interval
done5.实现解析:
interface="eno16777736":定义要监测的网卡名称,这里默认是eth0,用户可根据实际情况修改。
interval=1:设置每次读取流量数据的时间间隔为 1 秒。
while true; do... done:创建一个无限循环来实现持续监测。net_data=$(cat /proc/net/dev):读取/proc/net/dev文件的内容,该文件包含了网络接口的统计信息,将其存储在net_data变量中。
Interface_data=$(echo "$net_data" | grep "$interface:"):从net_data中查找指定网卡($interface)的那一行数据。
if [ -n "$interface_data" ]; then... else... fi:判断是否找到了网卡数据。如果找到了,receive_bytes=$(echo "$interface_data" | awk '{print $2}')和transmit_bytes=$(echo "$interface_data" | awk '{print $10}'):使用awk从网卡数据行中提取接收字节数(第 2 个字段)和发送字节数(第 10 个字段)。然后输出网卡名称、接收字节数和发送字节数。
如果没找到,输出提示信息。
sleep $interval:暂停指定的时间间隔(1 秒)后再次读取和显示流量数据。
6.结果验证:
若将网卡设置为未知的网卡,则输出以下内容
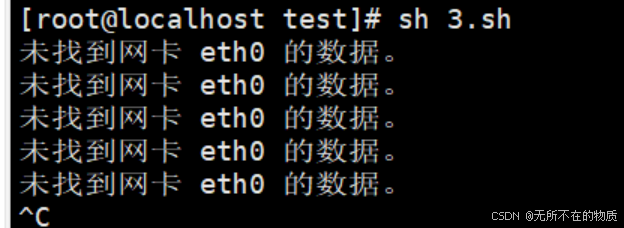
正确输入如下所示

案例九、在服务器上清理指定天数前的日志文件
1.问题:
编写一个 Shell 脚本,实现自动删除服务器上指定目录下超过指定天数的日志文件,以释放磁盘空间。
2.分析:
参数获取:需要获取两个参数,一个是日志文件所在的目录路径,另一个是保留日志文件的天数。
文件筛选:遍历指定目录及其子目录下的所有文件,获取每个文件的修改时间,通过与当前时间比较来确定文件是否超过指定天数。
文件删除:对于超过指定天数的文件,使用rm命令将其删除。
3.流程图:
4.实现:
#!/bin/bash
# 检查参数个数
if [ $# -ne 2 ]; then
echo "用法: $0 [日志目录] [保留天数]"
exit 1
fi
log_dir="$1"
days_to_keep="$2"
current_timestamp=$(date +%s)
# 一天的秒数
seconds_in_a_day=86400
for file in $(find $log_dir -type f); do
file_timestamp=$(stat -c %Y $file)
age_in_seconds=$((current_timestamp - file_timestamp))
age_in_days=$((age_in_seconds / seconds_in_a_day))
if [ $age_in_days -gt $days_to_keep ]; then
rm -f $file
echo "已删除文件: $file"
fi
done5.实现解析:
if [ $# -ne 2 ]; then... exit 1:检查参数个数,如果不等于 2,则输出用法信息并退出。这里期望两个参数,即日志目录和保留天数。
log_dir="$1"和days_to_keep="$2":将命令行传入的参数分别赋值给相应变量。
current_timestamp=$(date +%s):获取当前时间的时间戳(以秒为单位)。
seconds_in_a_day=86400:定义一天的秒数,用于后续计算文件年龄。
(-type f表示只查找文件)。对于每个文件:file_timestamp=$(stat -c %Y $file):使用stat命令获取文件的修改时间戳(%Y表示以秒为单位的时间戳)。
age_in_seconds=$((current_timestamp - file_timestamp)):计算文件距离当前时间的秒数。
age_in_days=$((age_in_seconds / seconds_in_a_day)):将文件年龄从秒转换为天数。
if [ $age_in_days -gt $days_to_keep ]; then... fi:如果文件年龄超过指定的保留天数,则使用rm -f $file删除该文件,并输出已删除文件的信息。-f选项用于强制删除,避免出现提示信息。
6.结果验证:
创建两个文件,将时间分别设置成一天前和两天前
touch -d "2 days ago" file1.log
touch -d "1 day ago" file2.log运行脚本,只保留一天前的日志文件,其他的删除
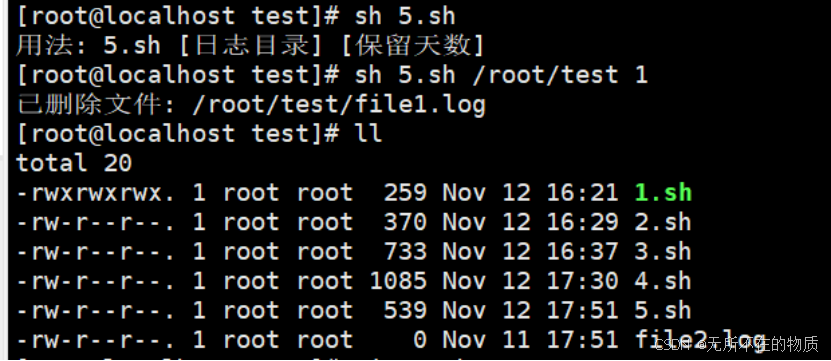
可以看到file1已经被删除掉,只剩下了file2
将保留天数设置成0,表示只保留今天的日志文件,执行脚本,结果如下
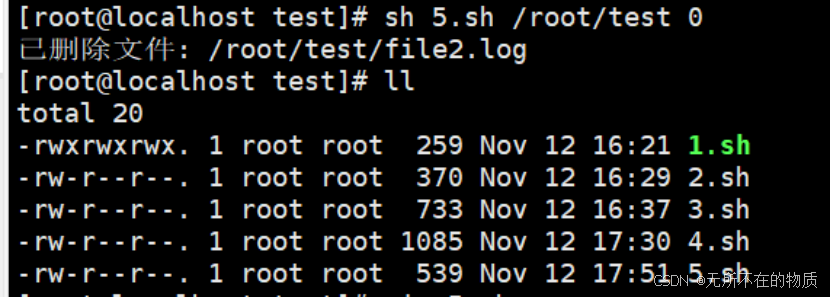
可以看到file2已经被删除
案例十、将指定目录下的所有文件压缩成一个压缩包
1.问题:
编写一个 Shell 脚本,实现将指定目录下的所有文件(包括子目录中的文件)打包成一个压缩文件。
2.分析:
参数获取:需要获取要压缩的目标目录路径作为参数。
文件遍历与压缩:使用tar命令来遍历目标目录下的所有文件,并将它们压缩成一个tar.gz文件。可以指定压缩文件名与目标目录相关,比如使用目标目录名加上.tar.gz作为压缩文件名。
3.流程图:
4.实现:
#!/bin/bash
# 检查参数个数
if [ $# -ne 1 ]; then
echo "用法: $0 [目标目录]"
exit 1
fi
target_dir="$1"
compressed_file="${target_dir##*/}.tar.gz"
# 使用tar命令压缩文件
tar -czvf $compressed_file $target_dir5.实现解析:
if [ $# -ne 1 ]; then... exit 1:检查参数个数,若不等于 1,则输出脚本用法并退出。这里期望的唯一参数是要压缩的目标目录。
target_dir="$1":将传入的参数(目标目录)赋值给target_dir变量。
compressed_file="${target_dir##*/}.tar.gz":${target_dir##*/} 是一种 Shell 参数扩展方式,它会删除$target_dir中匹配从左边开始最长的*/模式的部分,也就是获取目标目录的基本名称(不包含路径部分)。
然后将这个基本名称加上.tar.gz后缀,得到压缩文件名,并赋值给compressed_file变量。
tar -czvf $compressed_file $target_dir:tar是用于打包和压缩文件的命令。
-c选项表示创建新的归档文件。
-z选项表示使用gzip压缩算法。
-v选项表示在压缩过程中显示详细信息。
-f选项后面紧跟压缩文件名,这里是$compressed_file。
最后$target_dir指定要压缩的目录。
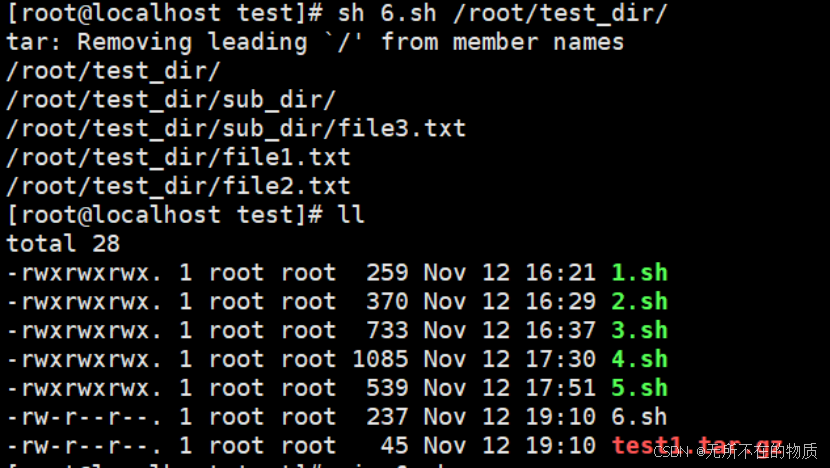
6.结果验证:
创建一个目录,并且在目录里面创建一些文件
mkdir -p test_dir/sub_dir
touch test_dir/file1.txt test_dir/file2.txt test_dir/sub_dir/file3.txt执行脚本,可以得到test1.tar.gz压缩包


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









