







文章目录
一、队列的概念
队列:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出FIFO(First In First Out) 入队列:进行插入操作的一端称为队尾 出队列:进行删除操作的一端称为队头。
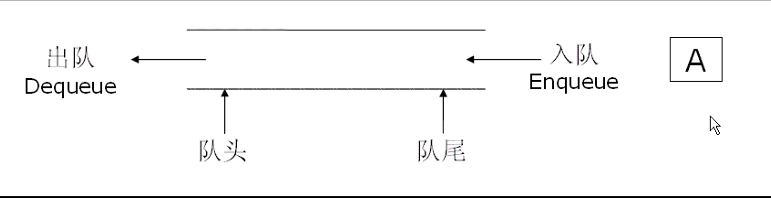
队列可以使用数组和链表两个方式来实现,但是使用数组的话,动态数组和静态数组都有局限性,所以用链表来实现是最方便的方法。
二、队列的实现
构建队列的需求有三个文件,包括Queue.c(用来书写逻辑的内容)、Queue.h(用来书写逻辑的声明)、test.c(用来测试我们所书写的代码)。
1、Queue.h(用来书写逻辑的声明)
运用链表,我们要先创建一个结构体变量,对其进项重命名操作,方便我们后面的使用。
首先,创建一个结构体QListNode表示链表中的节点,将其重命名为QNode。
typedef struct QListNode
{
struct QListNode* next;
int val;
}QNode;
在以后使用的时候,我们可能会在链表中存取其他类型的变量,所以将链表中的int类型也进行重命名操作,方便以后得更改
typedef int QDataType;
typedef struct QListNode
{
struct QListNode* next;
QDataType val;
}QNode;
创建完节点以后,我们要考虑到传参问题,如果需要实现队列的功能,“先进先出”,那么就需要用两个指针来分别标记头节点和尾节点。所以我们如果要实现插入数据的功能时,就要将函数写成以下形式。
void QueuePush(pQNode** phead,pQNode** ptail,QDataType x);
后面的每个函数都要传两个参数,并且是二级指针,这样太麻烦了而且容易出错,所以可以将头节点,尾节点分装成一个结构体,来表示整个队列的信息,并且可以额外加入一个变量 size 来记录队列中的数据个数。
结构体如下,同样进行重命名以便后续使用:
typedef struct Queue
{
QNode* phead;
QNode* ptile;
int size;
}Queue;
下面,我们将要实现大函数整理一遍,方便后面使用:
// 初始化队列
void QueueInit(Queue* pq);
// 队尾入队列
void QueuePush(Queue* pq, QDataType x);
// 队头出队列
void QueuePop(Queue* pq);
// 获取队列头部元素
QDataType QueueFront(Queue* pq);
// 获取队列队尾元素
QDataType QueueBack(Queue* pq);
// 获取队列中有效元素个数
int QueueSize(Queue* pq);
// 检测队列是否为空,如果为空返回非零结果,如果非空返回0
bool QueueEmpty(Queue* pq);
// 销毁队列
void QueueDestroy(Queue* pq);
2、Queue.c(用来书写逻辑的内容)
这一部分的代码还是比较简单的,所以我们直接来实现代码。
1、初始化队列
对于队列的初始化,代码如下:
void QueueInit(Queue* pq)
{
assert(pq);
pq->phead = pq->ptile = NULL;
pq->size = 0;
}
2、队尾入队列
队尾入队列要先申请一个空间来存放新的节点,同时判断队内节点个数
代码如下:
void QueuePush(Queue* pq, QDataType x)
{
assert(pq);
//申请空间
QNode* new = (QNode*)malloc(sizeof(QNode));
if (new == NULL)
{
perror("QueuePush:malloc");
return;
}
new->next = NULL;
new->val = x;
if (pq->ptile == NULL)//一个节点
{
pq->phead = pq->ptile = new;
}
else //多个节点
{
pq->ptile->next = new;
pq->ptile = new;
}
pq->size++;
}
3、队头出队列
队头出队列 要判断队内有几个节点
代码如下:
void QueuePop(Queue* pq)
{
assert(pq);
assert(pq->size != 0);
//一个节点
if (pq->phead == pq->ptile)
{
free(pq->phead);
pq->phead = pq->ptile = NULL;
}
else//多个节点
{
QNode* cur = pq->phead->next;
free(pq->phead);
pq->phead = cur;
}
pq->size--;
}
4、获取队列头部元素
获取队列头部元素 直接返回头结点的数据
代码如下:
QDataType QueueFront(Queue* pq)
{
assert(pq);
assert(pq->size != 0);
return pq->phead->val;
}
5、获取队列队尾元素
获取队列队尾元素直接返回尾结点的数据
代码如下:
QDataType QueueBack(Queue* pq)
{
assert(pq);
assert(pq->size != 0);
return pq->ptile->val;
}
6、获取队列中有效元素个数
获取队列中有效元素个数,返回Queue结构体中的size即可
代码如下:
int QueueSize(Queue* pq)
{
assert(pq);
assert(pq->size != 0);
return pq->size;
}
7、检测队列是否为空,如果为空就返回true,如果不为空返回false
检测队列是否为空,如果为空就返回true,如果不为空返回false
代码如下:
bool QueueEmpty(Queue* pq)
{
assert(pq);
return pq->size == 0;
}
8、销毁队列
代码如下:
void QueueDestroy(Queue* pq)
{
assert(pq);
QNode* cur = pq->phead;
while (cur)
{
QNode* next = cur->next;
free(cur);
cur = next;
}
pq->phead = pq->ptile = NULL;
pq->size = 0;
}
三、完整代码展示
Queue.h
#include<stdio.h>
#include<stdbool.h>
#include<assert.h>
#include<stdlib.h>
// 链式结构:表示队列
typedef int QDataType;
typedef struct QListNode
{
struct QListNode* next;
QDataType val;
}QNode;
// 队列的结构
typedef struct Queue
{
QNode* phead;
QNode* ptile;
int size;
}Queue;
// 初始化队列
void QueueInit(Queue* pq);
// 队尾入队列
void QueuePush(Queue* pq, QDataType x);
// 队头出队列
void QueuePop(Queue* pq);
// 获取队列头部元素
QDataType QueueFront(Queue* pq);
// 获取队列队尾元素
QDataType QueueBack(Queue* pq);
// 获取队列中有效元素个数
int QueueSize(Queue* pq);
// 检测队列是否为空,如果为空返回非零结果,如果非空返回0
bool QueueEmpty(Queue* pq);
// 销毁队列
void QueueDestroy(Queue* pq);
Queue.c
#include"Queue.h"
// 初始化队列
void QueueInit(Queue* pq)
{
assert(pq);
pq->phead = pq->ptile = NULL;
pq->size = 0;
}
// 队尾入队列
void QueuePush(Queue* pq, QDataType x)
{
assert(pq);
QNode* new = (QNode*)malloc(sizeof(QNode));
if (new == NULL)
{
perror("QueuePush:malloc");
return;
}
new->next = NULL;
new->val = x;
if (pq->ptile == NULL)//一个节点
{
pq->phead = pq->ptile = new;
}
else //多个节点
{
pq->ptile->next = new;
pq->ptile = new;
}
pq->size++;
}
// 队头出队列
void QueuePop(Queue* pq)
{
assert(pq);
assert(pq->size != 0);
if (pq->phead == pq->ptile)
{
free(pq->phead);
pq->phead = pq->ptile = NULL;
}
else
{
QNode* cur = pq->phead->next;
free(pq->phead);
pq->phead = cur;
}
pq->size--;
}
// 获取队列头部元素
QDataType QueueFront(Queue* pq)
{
assert(pq);
assert(pq->size != 0);
return pq->phead->val;
}
// 获取队列队尾元素
QDataType QueueBack(Queue* pq)
{
assert(pq);
assert(pq->size != 0);
return pq->ptile->val;
}
// 获取队列中有效元素个数
int QueueSize(Queue* pq)
{
assert(pq);
assert(pq->size != 0);
return pq->size;
}
// 检测队列是否为空,如果为空返回非零结果,如果非空返回0
bool QueueEmpty(Queue* pq)
{
assert(pq);
return pq->size == 0;
}
// 销毁队列
void QueueDestroy(Queue* pq)
{
assert(pq);
QNode* cur = pq->phead;
while (cur)
{
QNode* next = cur->next;
free(cur);
cur = next;
}
pq->phead = pq->ptile = NULL;
pq->size = 0;
}
test.c
#include"Queue.h"
int main()
{
Queue q;
QueueInit(&q);
QueuePush(&q, 1);
QueuePush(&q, 2);
QueuePush(&q, 3);
QueuePush(&q, 4);
/*printf("%d ", QueueFront(&q));
printf("%d\n", QueueBack(&q));
QueuePop(&q);
printf("%d ", QueueFront(&q));
printf("%d\n", QueueBack(&q));
QueuePop(&q);
printf("%d ", QueueFront(&q));
printf("%d\n", QueueBack(&q));
QueuePop(&q);
printf("%d ", QueueFront(&q));
printf("%d\n", QueueBack(&q));
QueuePop(&q);*/
printf("%d", QueueSize(&q));
QueueDestroy(&q);
return 0;
}

















 2681
2681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









