







目录
快速排序的思想
快速排序(Quick Sort)是一种高效的排序算法,采用分治法的策略来把一个序列分为较小和较大的两个子序列,然后递归地排序两个子序列。快速排序的基本思想是选择一个“基准”元素,将元素分为两部分:比基准小的元素和比基准大的元素,然后递归地对这两部分进行排序
快速排序的工作原理
- 选择基准值:从待排序的数组中选择一个元素作为基准值
- 分区操作:将数组中小于基准值的元素移到基准值的左边,大于基准值的元素移到右边。这个过程称为分区
- 递归排序:对基准值左边的子数组和右边的子数组分别进行快速排序,直到所有子数组都有序,整个数组自然有序
快速排序的性能特点
- 时间复杂度:快速排序的平均时间复杂度为
,但在最坏的情况下(例如,每次选择的基准值使得一侧完全没有元素)时间复杂度退化为
- 空间复杂度:快速排序的空间复杂度为
,因为它是一个递归算法
- 稳定性:快速排序是不稳定的排序算法,因为相同的元素在排序后可能会改变它们的相对位置
Hoare版本
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
int PartSort(int* a, int left, int right)
{
int key = left;
int begin = left, end = right;
while (begin < end)
{
//左边做key,右边先走,可以保证相遇位置一定比key小
//右边找小
while (begin < end && a[end] >= a[key])
end--;
//左边找大
while (begin < end && a[begin] <= a[key])
begin++;
Swap(&a[begin], &a[end]);
}
Swap(&a[key], &a[begin]);
//返回中间
return begin;
}
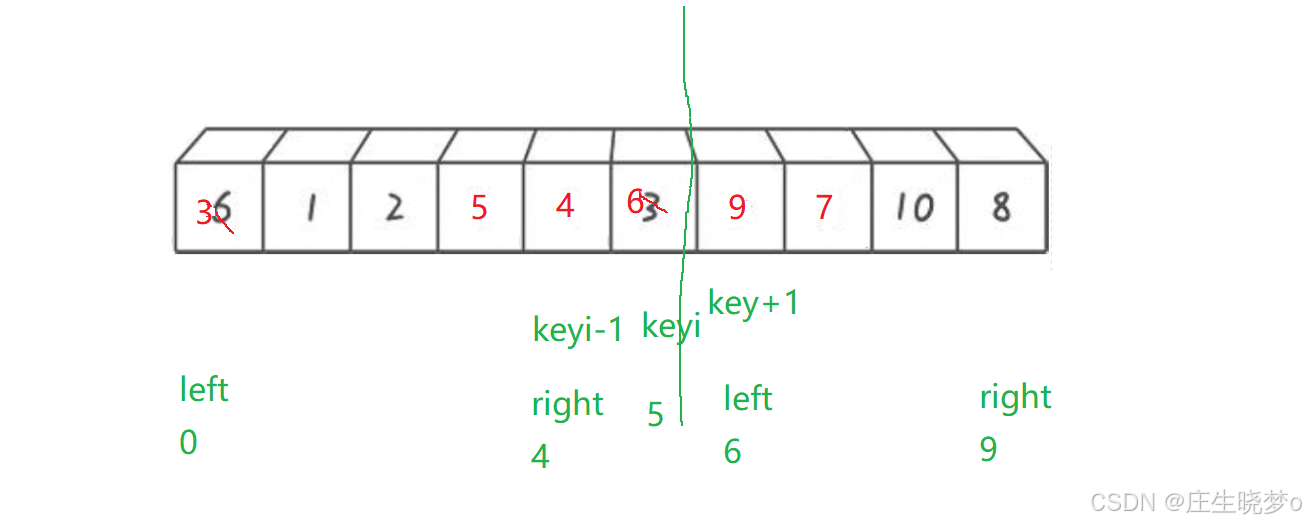
void QuickSort(int* a, int left, int right)
{
if (left >= right)
return;
int key = PartSort(a, left, right);
//[left,key-1] key [key+1,right]
QuickSort(a, left, key - 1);
QuickSort(a, key + 1, right);
}
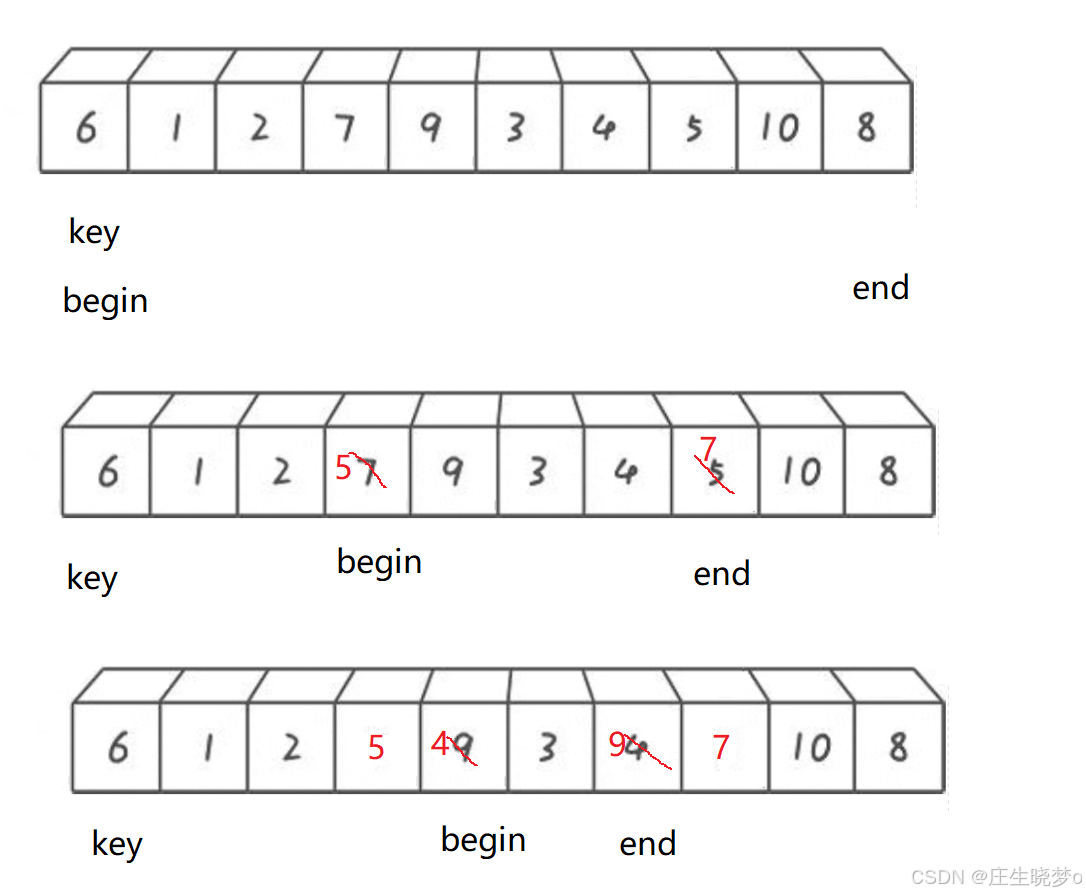
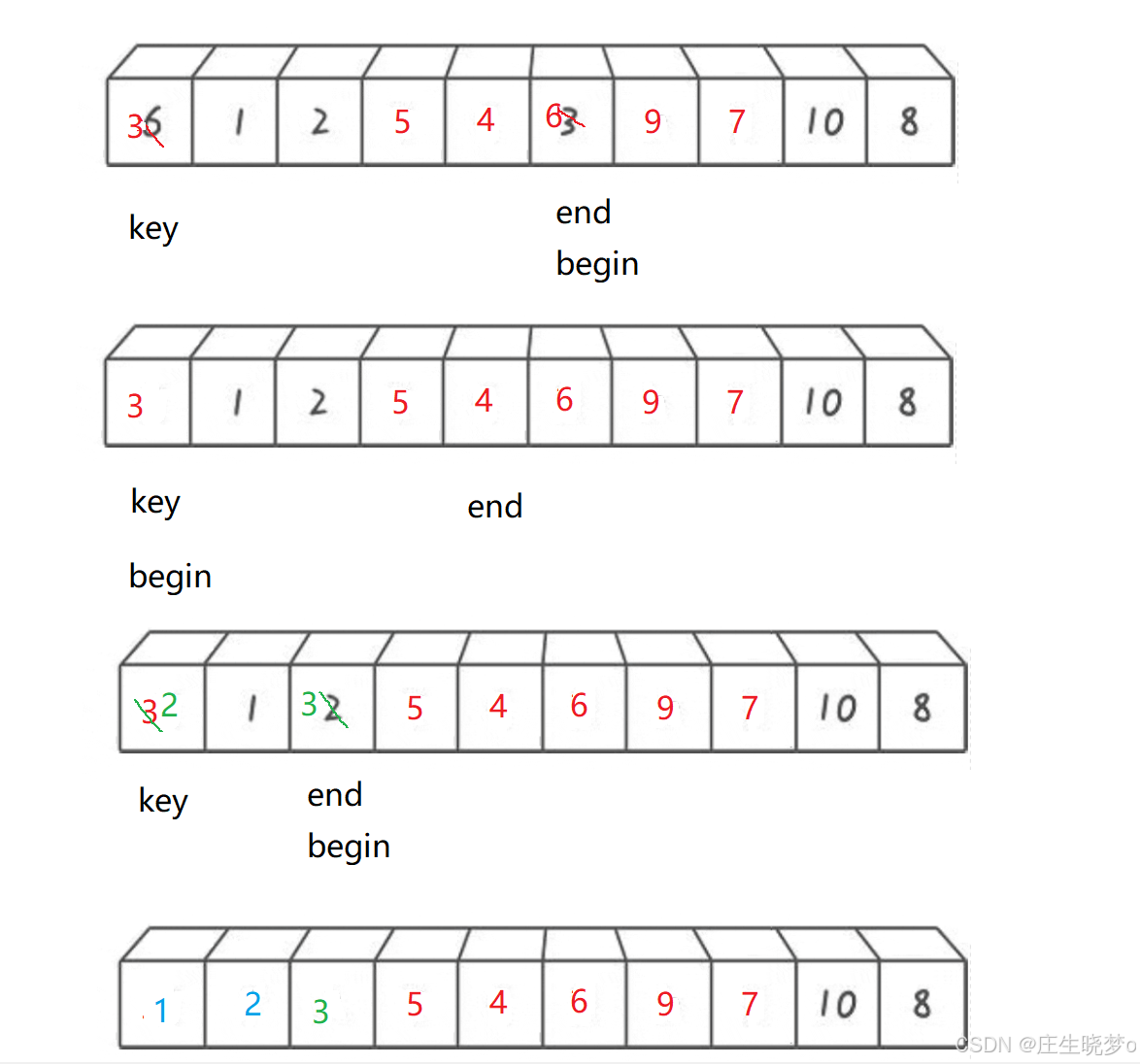
过程示意图
代码解析:
- 首先,定义一个变量key,用于保存基准值的下标,初始值为left。
- 进入一个循环,循环条件是left < right,即左右指针没有相遇。
- 在循环中,首先从右边开始,找到第一个小于等于基准值的元素的下标,将right指针左移,直到找到符合条件的元素或者left和right相遇。
- 然后从左边开始,找到第一个大于基准值的元素的下标,将left指针右移,直到找到符合条件的元素或者left和right相遇。
- 如果left < right,说明找到了需要交换的元素,将a[left]和a[right]交换位置。
- 重复步骤3到步骤5,直到left和right相遇。
- 最后,将基准值a[key]和a[left]交换位置,将基准值放在正确的位置上。
- 返回分割点的下标left。
优化1:三数取中
//三个数,取中间的那个数
void Getmid(int* a, int left, int right)
{
int mid = (left + right) / 2;
if (a[left] < a[mid])
{
if (a[mid] < a[right])
return mid;
else if (a[left] < a[right])
return right;
else
return left;
}
else // a[left] > a[mid]
{
if (a[mid] > a[right])
return mid;
else if (a[right] > a[left])
return left;
else
return right;
}
}为什么要三数取中?
- 三数取中是为了选择一个更好的基准值,以提高快速排序的效率。在快速排序中,选择一个合适的基准值是非常重要的,它决定了每次分割的平衡性。
- 快速排序是通过一趟排序将待排序的数据分割成独立的两部分,其中一部分的所有数据都比另一部分的小,然后再对这两部分分别进行快速排序,递归地进行下去,直到整个序列有序。
- 如果每次选择的基准值都是最左边或最右边的元素,那么在某些情况下,快速排序的效率可能会降低。例如,当待排序序列已经有序时,如果每次选择的基准值都是最左边或最右边的元素,那么每次分割得到的两个子序列的长度差可能会非常大,导致递归深度增加,快速排序的效率降低。
- 而通过三数取中的优化,可以选择一个更好的基准值,使得每次分割得到的两个子序列的长度差更小,从而提高快速排序的效率。
- 具体来说,三数取中的优化是选择待排序序列的左端、右端和中间位置的三个元素,然后取它们的中值作为基准值。这样选择的基准值相对于最左边或最右边的元素,更接近整个序列的中间位置,可以更好地平衡分割后的两个子序列的长度,从而提高快速排序的效率。
- 通过三数取中的优化,可以减少递归深度,提高分割的平衡性,使得快速排序的效率更稳定,适用于各种不同的输入情况。
优化2:小区间优化
小区间优化是指在快速排序中,当待排序的子序列的长度小于一定阈值时,不再继续使用快速排序,而是转而使用直接插入排序。
void _QuickSort(int* a, int left, int right)
{
if (left >= right)
return;
//如果长度小于10,直接插入排序
if (right - left + 1 > 10)
{
int keyi = PartSort(a, left, right);
QuickSort(a, left, keyi - 1);
QuickSort(a, keyi + 1, right);
}
else
{
InsertSort(a + left, right - left + 1);
}
}小区间优化的好处
- 减少递归深度:使用插入排序来处理较小的子序列,可以减少递归的深度,从而减少了函数调用的开销。
- 提高局部性:插入排序是一种稳定的排序算法,它具有良好的局部性,可以充分利用已经有序的部分序列。对于较小的子序列,插入排序的效率更高。
- 减少分割次数:对于较小的子序列,使用插入排序可以减少分割的次数。快速排序的分割操作需要移动元素,而插入排序只需要进行元素的比较和交换,因此在较小的子序列中使用插入排序可以减少分割操作的次数。
小区间优化可以在一定程度上提高快速排序的性能。它通过减少递归深度、提高局部性和减少分割次数来优化算法的效率, 特别适用于处理较小的子序列。
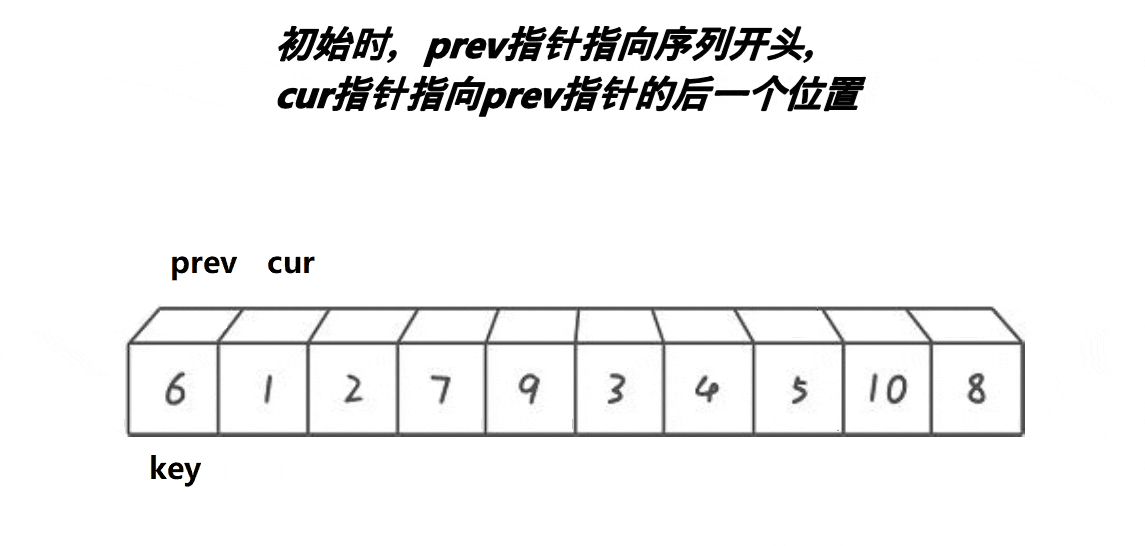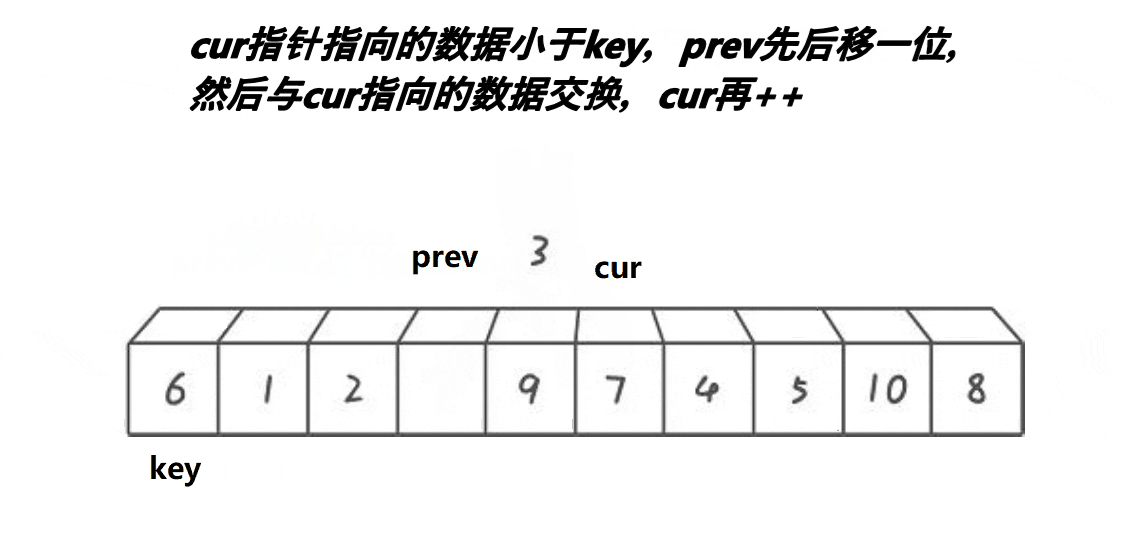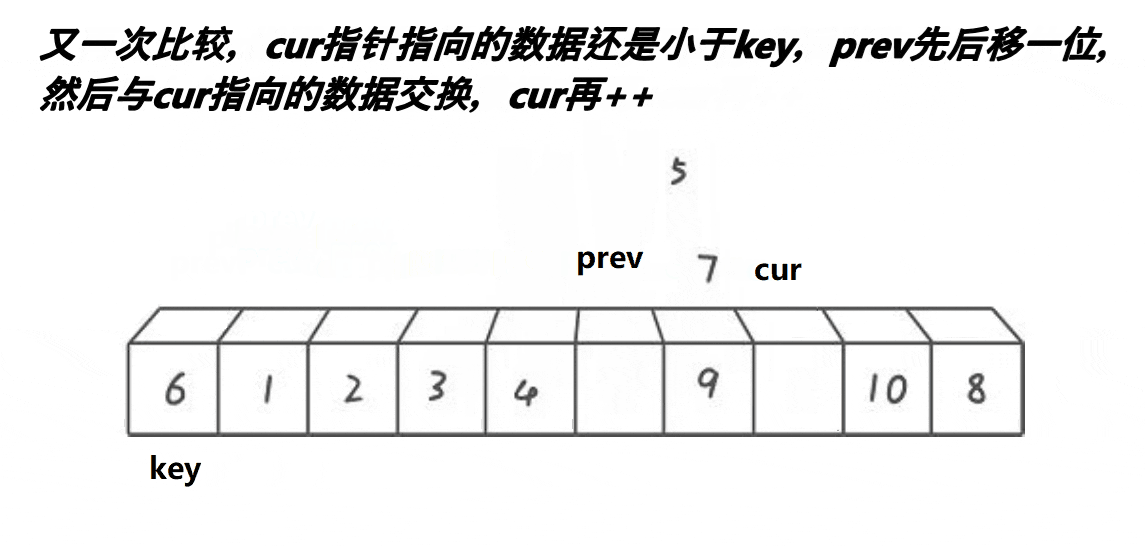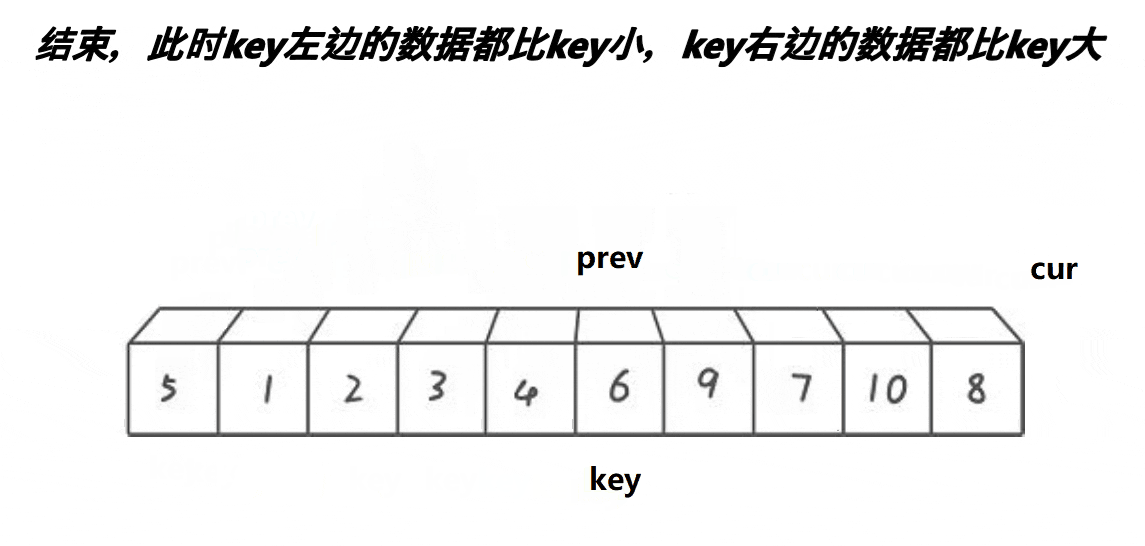
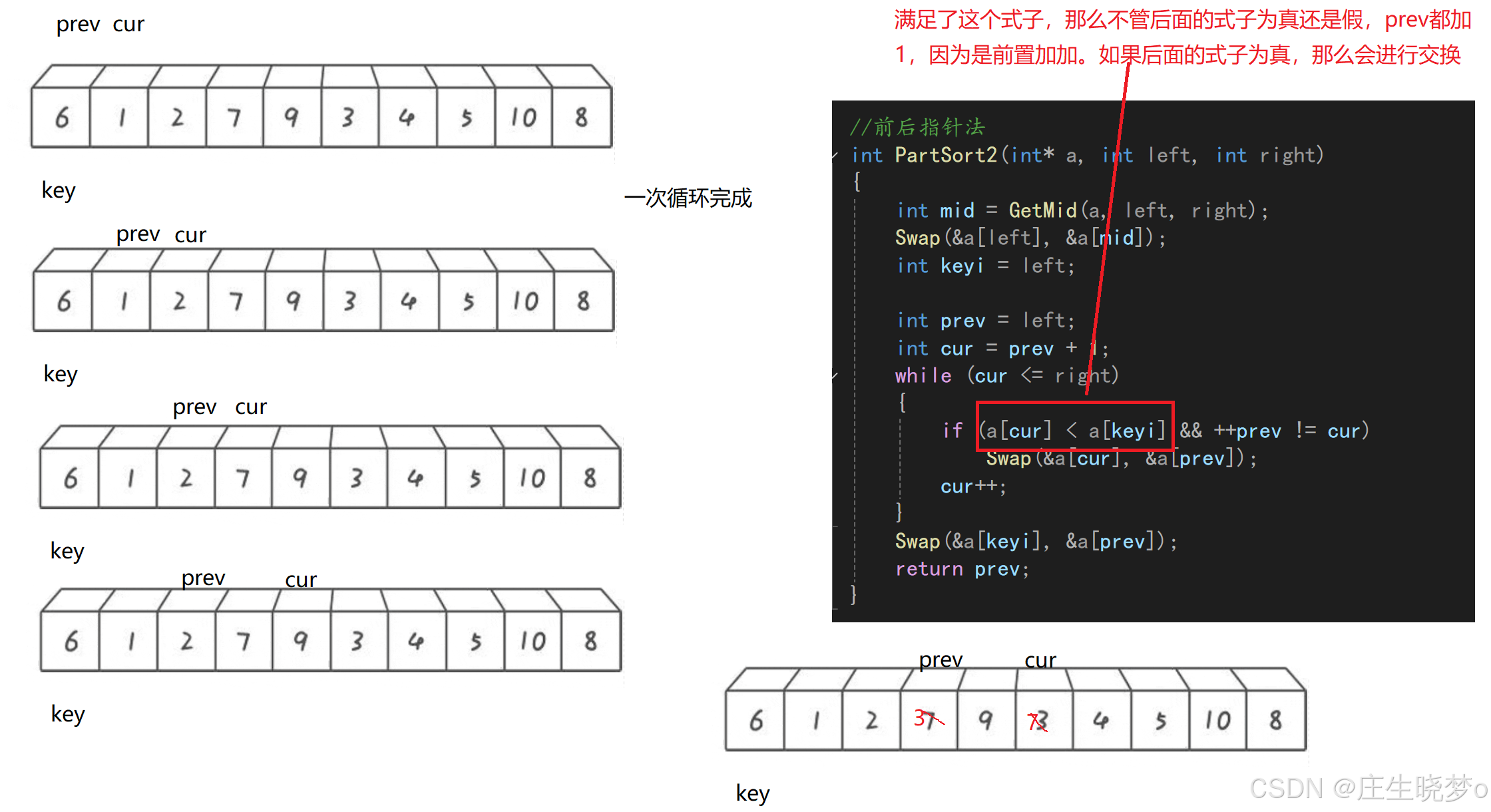
前后指针法
int PartSort2(int* a, int left, int right)
{
int mid = GetMid(a, left, right);
Swap(&a[left], &a[mid]);
int keyi = left;
int prev = left;
int cur = prev + 1;
while (cur <= right)
{
if (a[cur] < a[keyi] && ++prev != cur)
Swap(&a[cur], &a[prev]);
cur++;
}
Swap(&a[keyi], &a[prev]);
return prev;
}代码解析
- 定义两个指针prev和cur,分别指向left和left+1。
- 定义一个变量keyi,用于保存基准值的下标,初始值为left。
- 进入一个循环,循环条件是cur <= right,即cur指针没有越界。
- 在循环中,如果a[cur]小于基准值a[keyi],则将prev指针右移一位,并交换a[prev]和a[cur]的值,保证prev指针之前的元素都小于基准值。
- 将cur指针右移一位。
- 重复步骤4到步骤6,直到cur指针越界。
- 最后,将基准值a[keyi]和a[prev]交换位置,将基准值放在正确的位置上。
- 返回分割点的下标prev。
挖坑法
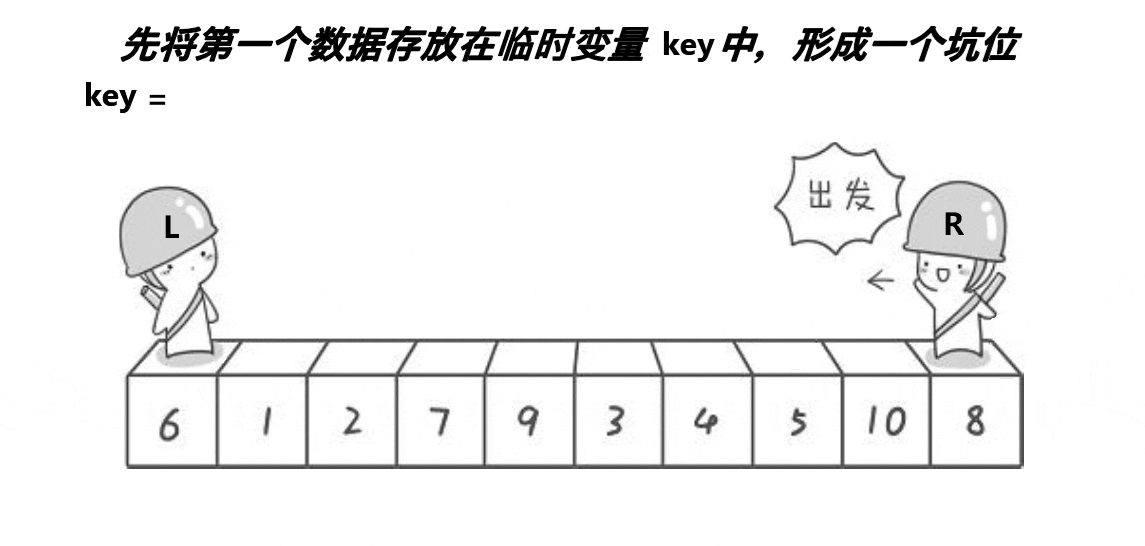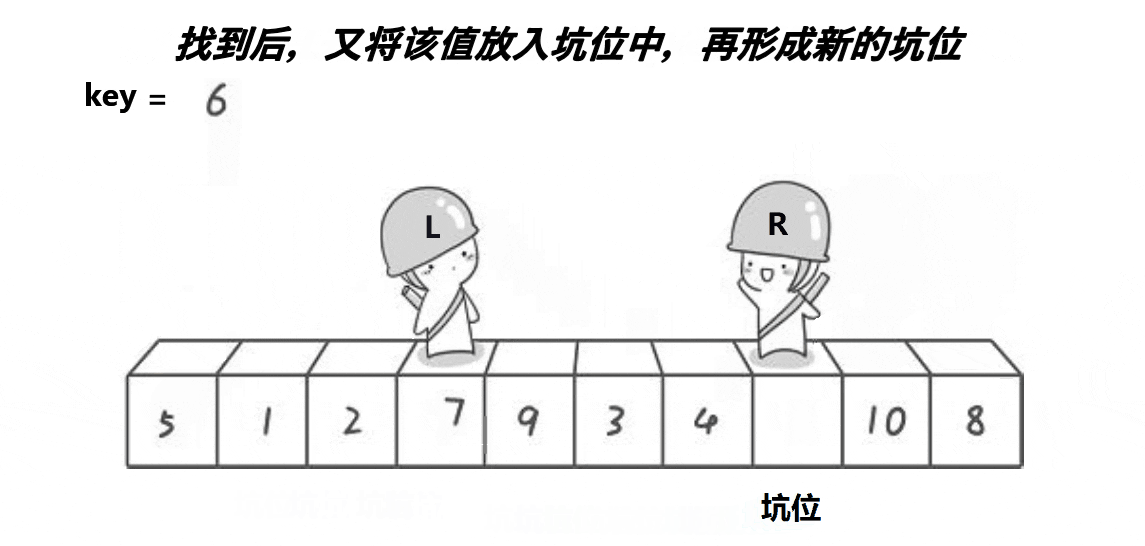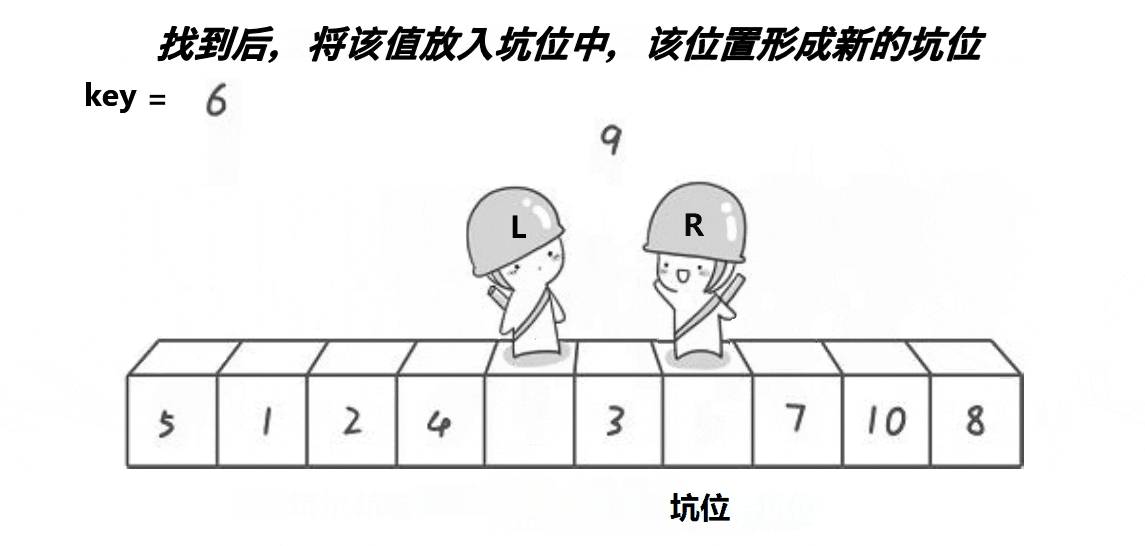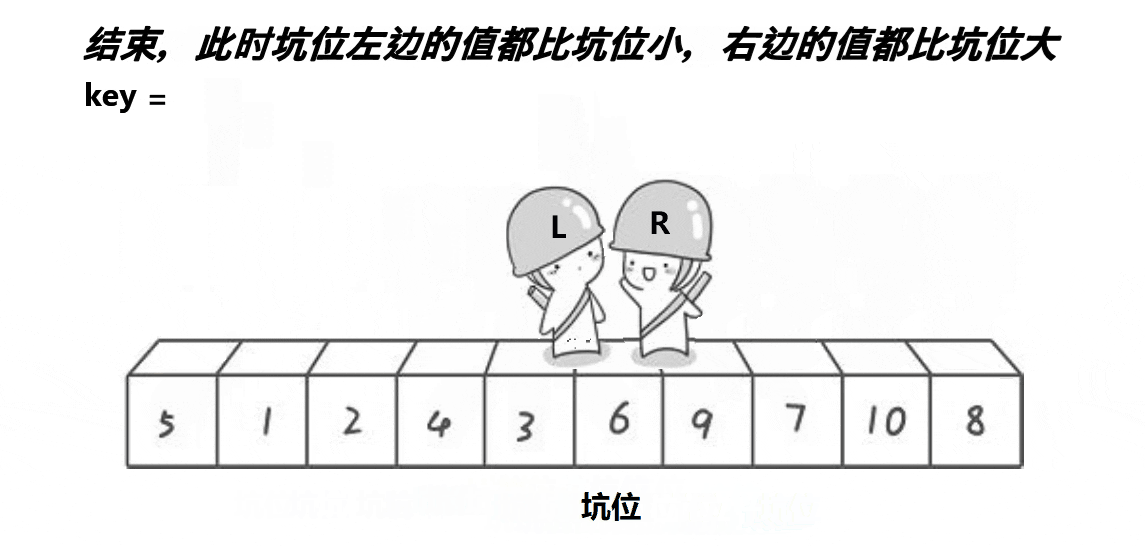
//挖坑法
int PartSort3(int* a, int left, int right)
{
int key = a[left];
int hole = left; // 第一个坑
while (left < right)
{
while (left < right && key <= a[right])
--right;
a[hole] = a[right]; // 元素交换位置
hole = right; // 坑位交换
while (left < right && key >= a[left])
++left;
a[hole] = a[left];
hole = left;
}
a[hole] = key; // 填坑位
//此时这个坑左边小于坑值,右边大于坑值
return hole;
}代码解析:
- 定义一个变量key,用于保存基准值,初始值为a[left]。
- 定义一个变量hole,用于保存空洞的位置,初始值为left。
- 进入一个循环,循环条件是left < right,即左右指针没有相遇。
- 在循环中,首先从右边开始,找到第一个小于基准值的元素的下标,将right指针左移,直到找到符合条件的元素或者left和right相遇。
- 将a[right]的值赋给a[hole],将空洞的位置移动到right。
- 然后从左边开始,找到第一个大于基准值的元素的下标,将left指针右移,直到找到符合条件的元素或者left和right相遇。
- 将a[left]的值赋给a[hole],将空洞的位置移动到left。
- 重复步骤4到步骤7,直到left和right相遇。
- 最后,将基准值key放入空洞的位置a[hole],将基准值放在正确的位置上。
- 返回空洞的位置hole。
同样实现了将数据分成两部分,左边的元素都小于等于基准值,右边的元素都大于基准值。
快速排序非递归版
void QucikSortNonR(int* a, int left, int right)
{
ST st;
STInit(&st);
STPush(&st, right);
STPush(&st, left);
while (!STEmpty(&st))
{
int begin = STTop(&st);
STPop(&st);
int end = STTop(&st);
STPop(&st);
int keyi = PartSort(a, begin, end);
if (keyi + 1 < end)
{
STPush(&st, end);
STPush(&st, keyi + 1);
}
if (keyi - 1 > begin)
{
STPush(&st, keyi - 1);
STPush(&st, begin);
}
}
STDestroy(&st);
}快速排序非递归版需要用到栈结构
代码解析:
- 将整个序列的起始位置和结束位置入栈。然后,进入循环,不断从栈中取出子序列的起始位置和结束位置。
- 每次循环,就相当于一次递归。在每次循环中,通过PartSort函数将当前子序列分割成两部分,并得到基准值的下标keyi。如果基准值右边的子序列长度大于1,则将右边子序列的起始和结束位置入栈。如果基准值左边的子序列长度大于1,则将左边子序列的起始和结束位置入栈。
- 循环继续,知道栈为空,表示所有的子序列都已经排序完成。
通过使用栈来模拟递归的过程,非递归实现避免了递归调用的开销,提高了快速排序的效率。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









