






目录
3.为什么要用Xxl-job,而不用Spring Task等其它任务调度框架?
5.Spring Security 与 Shiro 的对比?
2.你们为什么不直接使用 Redis,而是选择了 Spring Cache?
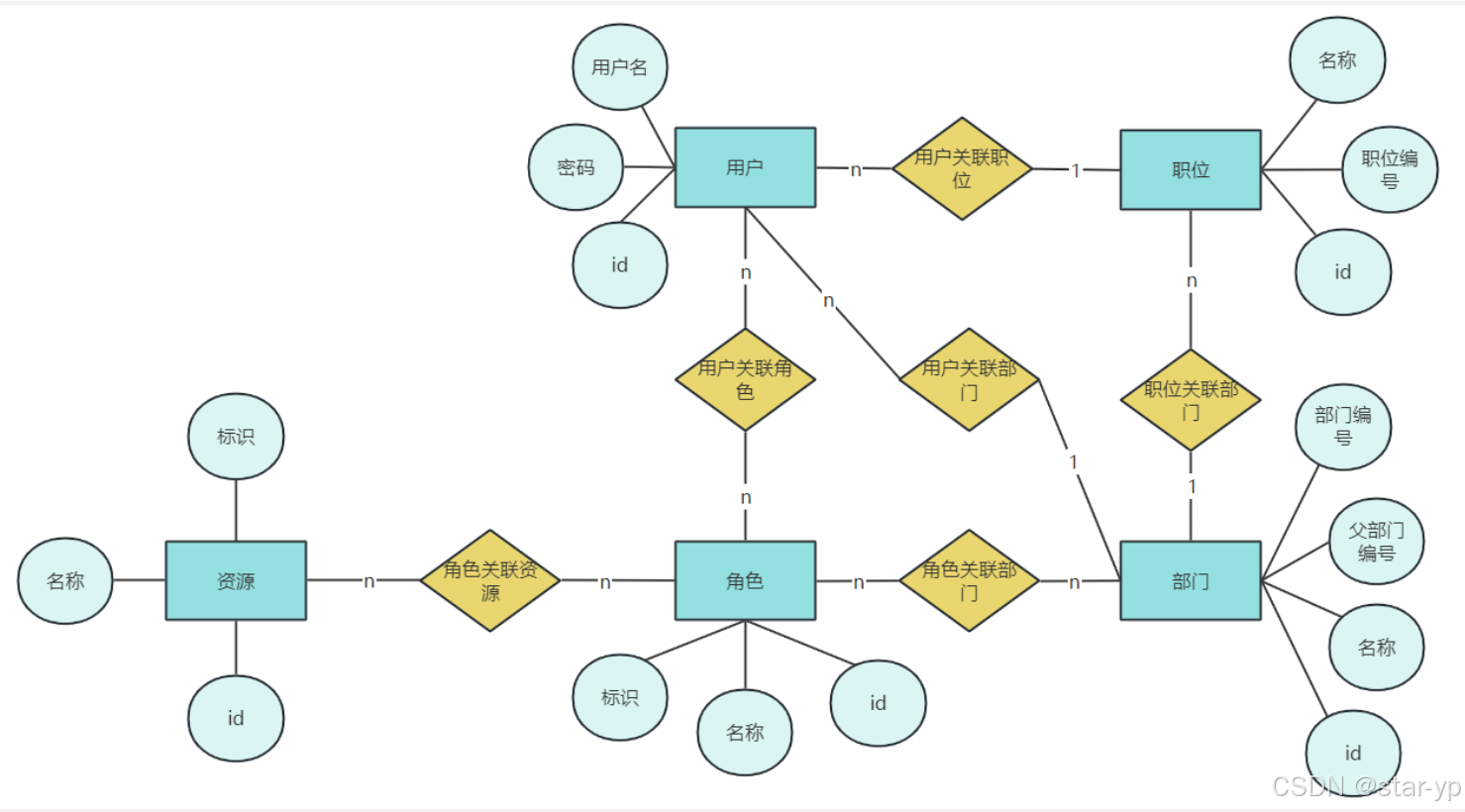
1.服务管理,包括:护理等级、护理计划、护理项目、负责老人、任务安排这5个子模块。
5.在你的项目里,有没有做过性能调优?如果有,请具体说明你是如何做的。
一、项目基本情况
1.行业背景
中国老龄化程度加深,我国老龄事业和养老服务体系的发展得到了国家的高度重视,在国家政策的支持下,我国智慧养老产业主体持续增多,产业链不断整合,发展前景较好。我国正在形成一个多元化“互联网+养老”的智慧老年护理服务系统,智慧养老是我国的必然趋势
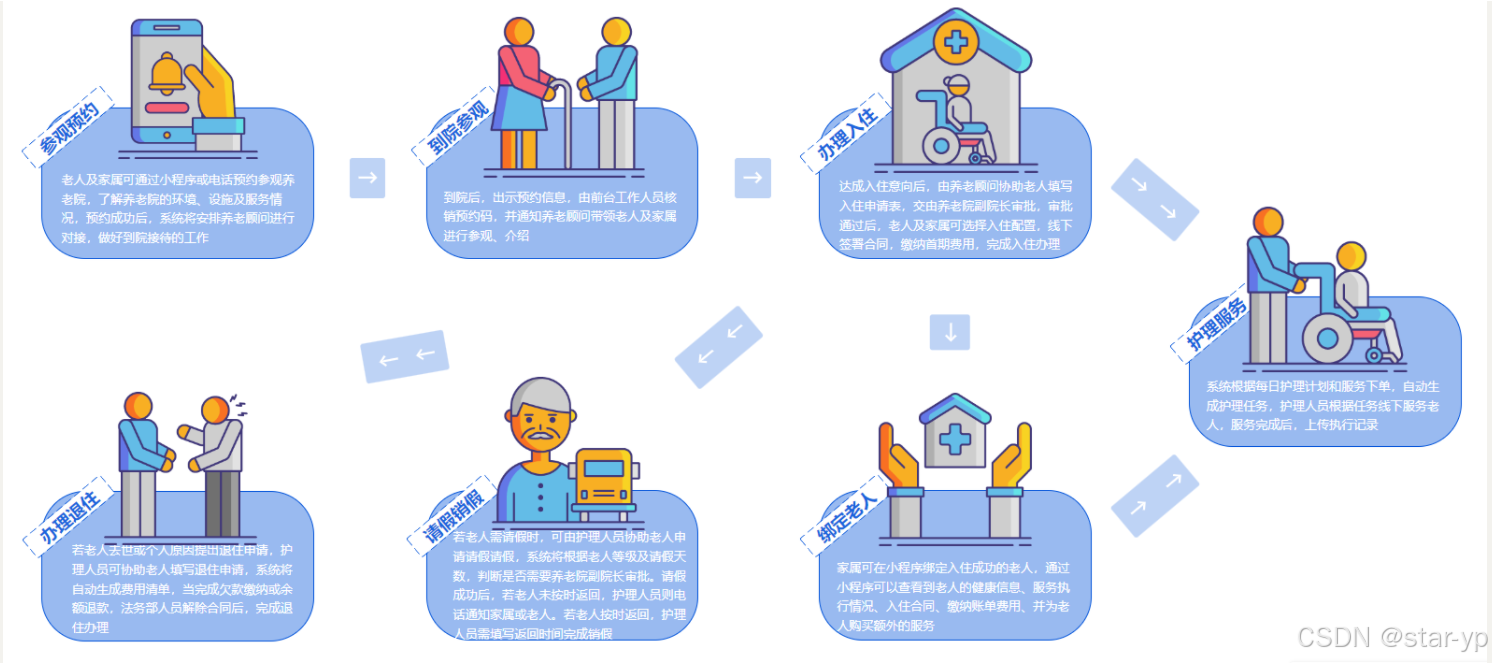
2.整体业务流程
慧养阁系统为养老院量身定制开发专业的养老管理软件产品;涵盖来访管理、入退管理、在住管理、服务管理、财务管理等功能模块,涉及从来访参观到退住办理的完整流程。
3.系统架构
慧养阁项目分为两端,一个是管理后台,另外一个是家属端
- 管理后台:养老院员工使用,入住、退住,给老人服务记录等等
- 家属端:养老院的老人家属使用,查看老人信息,缴费,下订单等等
4.技术架构
前端:vue3、TDesign、vite、Pinia、ts、Uni-app。
代理层:nginx 。
后端:springboot、springMVC、spring Security、Spring Cache、Xxl-job、Knife4j、Lombok、WebSocket。
数据库:Redis、Mysql。
第三方:OSS。
二、简历上写的要问的内容(重点准备的):
1.说一下你在项目中使用微信小程序登陆的实现流程?
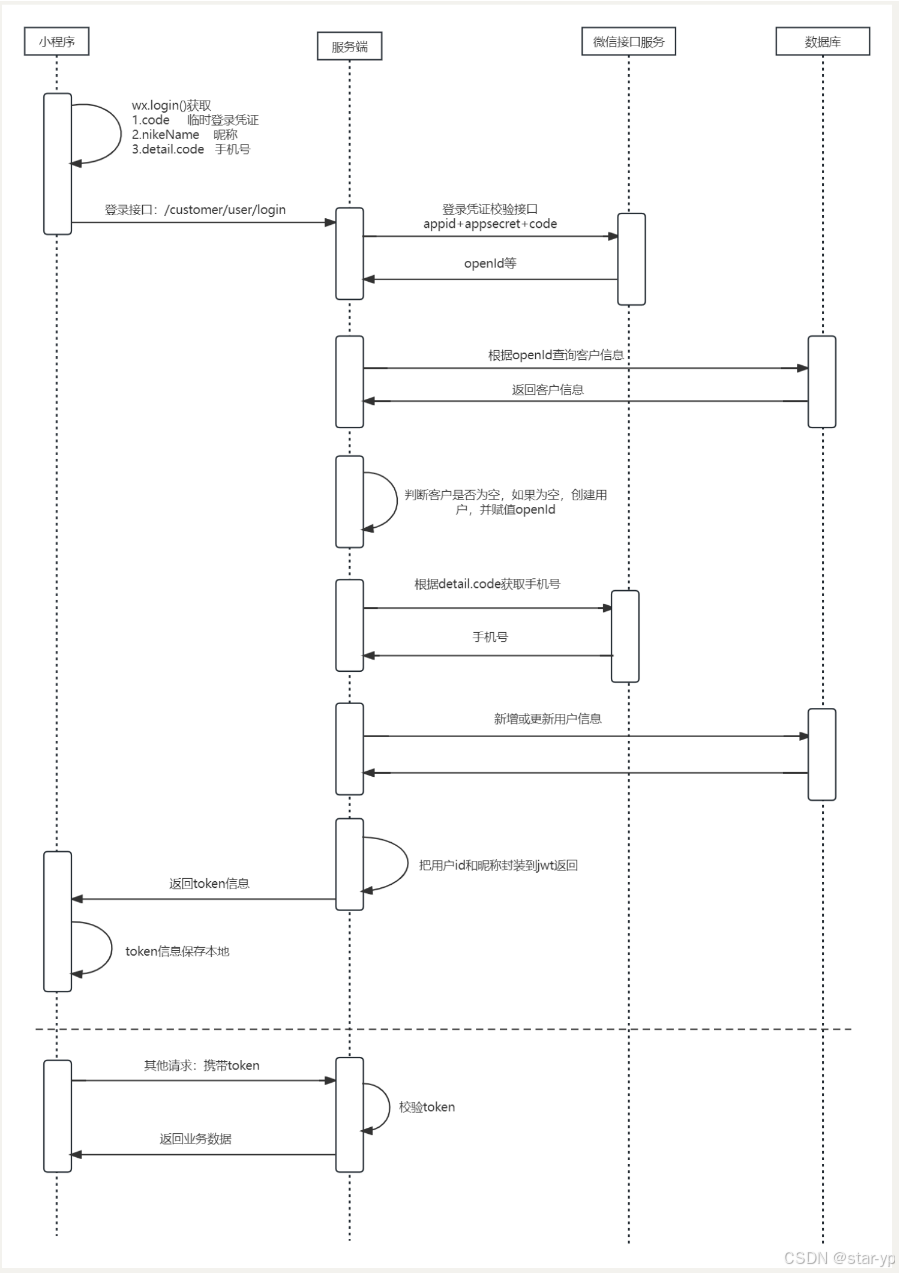
标准回答
嗯~~,好的,首先小程序端调用 wx.login() 获取 临时登录凭证code(此时小程序端向微信服务端发送了网络请求) ,然后把code(临时登陆凭证)、nikeName(昵称)、detail.code(手机号凭证)传回到我们的服务端,服务端接受到请求后然后先根据已经配置好的appid、appsecret、code向微信服务器请求获得openId。然后后端根据传回的openId查询数据库的用户信息,如果没有用户信息就创建一个用户,并赋值openId。然后根据detail.code(电话临时凭证)向微信服务端发送请求获得用户的手机号信息(这里需要先根据appid、appsecret获取token,将token拼接到请求路径中),看是否与数据库中该用户的手机号一致,不一致则新增/更新数据库的用户信息。然后将用户id和昵称封装到jwt中,生成token并返回给小程序端。小程序将其保存到storage里面,在当前会话中,以后每次请求其它服务都携带该token在请求头里面,服务端通过拦截器验证请求头中的token信息,成功后放行请求,获取并返回业务信息。
1.请你讲一下ThreadLocal?
对于小程序端:用户登录成功后,在当前会话中,以后每次请求其它服务都要先经过拦截器,获取token中的用户信息,如果获取成功就将用户信息(userId)存到ThreadLocal中,获取到业务信息后再次到达拦截器,此时将ThreadLocal中的用户信息删除,释放内存。此外,该线程在其他业务中使用到登录用户的信息时,能方便的从ThreadLocal中取出。
2.一个请求传送到mvc里面都经历了什么?
3.请给我讲一下你的项目里面是如何使用JWT的?
我们是根据用户id和用户昵称以及密钥来生成具有指定过期时间的token,在解析的时候根据保存在配置中的密钥来解析获得token里面的用户信息(用户id),然后把信息保存在ThreadLocal里面以便后面使用。
4.为什么使用微信小程序登陆?(它的好处和不足)
2.介绍一下你在项目中如何使用xxl-job的?
标准回答
预约管理定时修改状态:
嗯~~好的,在我们的项目中当用户需要来访的时候会预约来访信息,当用户没有按时来访之后,会把预约的状态修改为已过期,如果进行人工操作的话,那效率也太低了,并且可能造成数据遗漏。这时我们可以用xxl-job来做任务调度,我们可以每隔半个小时查询一次数据,如果状态是未到访并且已经过了预约时间,则设置为已过期。
相关八股
1.什么是任务调度?如何实现任务调度?
任务调度是指系统为了自动完成特定任务,在约定的特定时刻去执行任务的过程。有了任务调度即可解放更多的人力,而是由系统自动去执行任务。
实现方法:
- 多线程方式,结合sleep
- JDK提供的API,例如:Timer、ScheduledExecutor
- 框架,例如Quartz ,它是一个功能强大的任务调度框架,可以满足更多更复杂的调度需求
- spring task
- 分布式任务调度框架(例如:xxl-job)
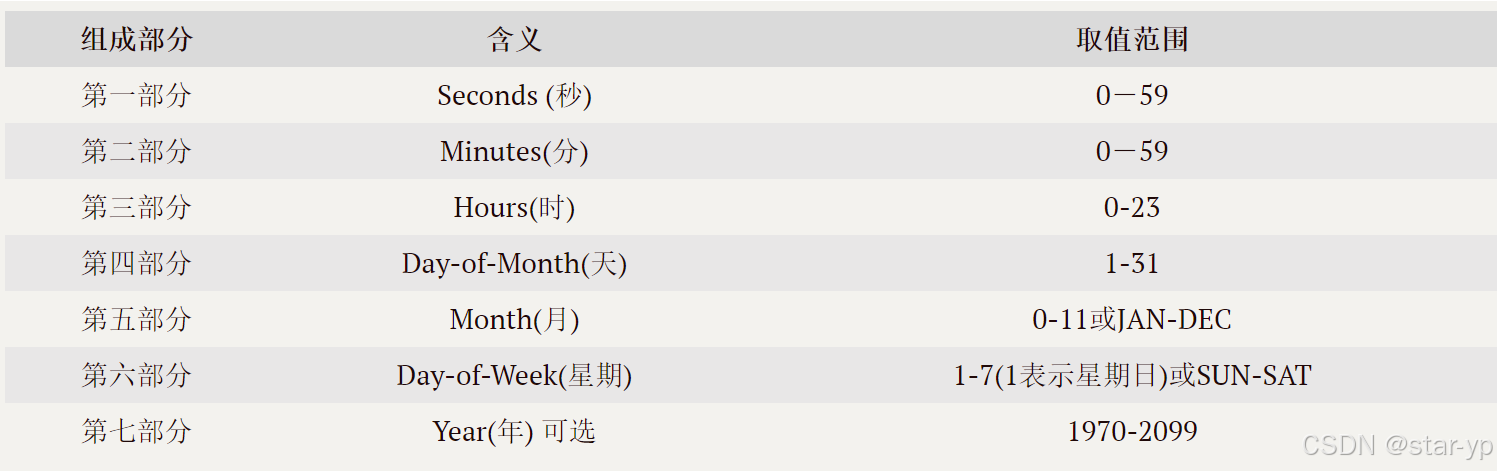
2.什么是cron表达式?
在我们使用调度任务技术的时候,特别是调度框架,里面都支持使用日历的方式来设置任务制定的时间、频率等,通常情况下都会使用cron表达式来表达。
cron表达式是一个字符串, 用来设置定时规则, 由七部分组成, 每部分中间用空格隔开, 每部分的含义如下表所示:
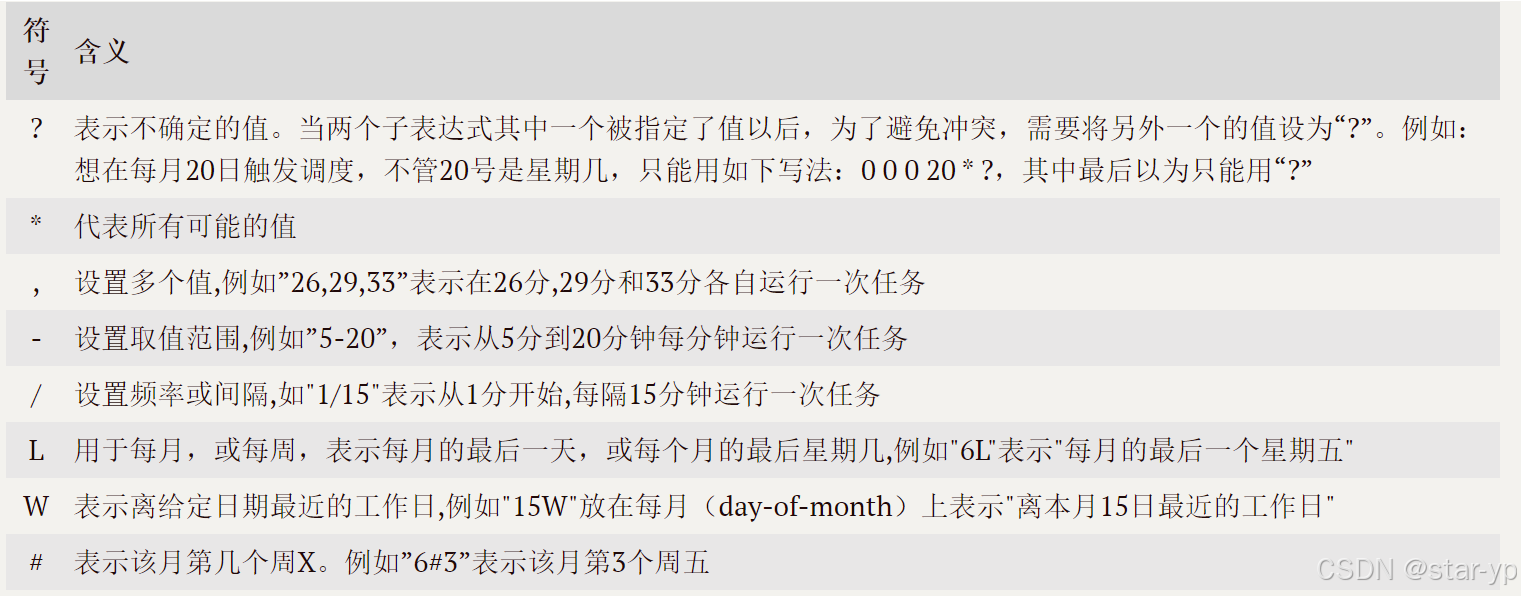
另外, cron表达式还可以包含一些特殊符号来设置更加灵活的定时规则, 如下表所示:
3.为什么要用Xxl-job,而不用Spring Task等其它任务调度框架?
1.如果只是单体项目的话,定时任务执行是不会有任何问题的,但是如果后期业务量较大,单体项目做了集群部署,那集群中每一台服务的代码都是一样的,都会按照规定的时间来执行任务,这样就会造成定时任务重复执行。
2.XXL-JOB 提供了可视化界面,任务管理更方便。
3.它支持分布式任务调度,即使单体项目未来扩展成分布式系统也容易迁移。
4.它的集群部署和故障转移功能比较强大。
(①:解决集群情况下,任务重复执行问题
②:方便管理定时cron表达式(提供了一个调度中心)
③:方便查看任务的错误情况(邮件通知,日志、重试)
④:分片广播)
相关八股
集群和分布式的区别?
单体项目集群部署 是把同一个项目部署到多台服务器上,适合中小型应用,扩展方式是水平扩展(加更多服务器)。
分布式系统 是把应用的功能拆分成多个独立的服务,每个服务独立部署,适合大型复杂应用,扩展方式是针对某个服务单独扩展。
4.你如何保证任务的可靠性?
1.XXL-JOB 支持任务失败重试,可以在任务配置中设置重试次数和间隔。
2.可以通过邮件、短信等方式配置告警通知。
3.如果任务失败后需要人工干预,可以设计一个任务监控页面。
5.如何避免任务重复执行?
1.XXL-JOB 自带任务分片机制,确保同一个任务只会被一个节点执行。
2.如果任务是幂等的(比如写数据库时加唯一约束),可以通过业务逻辑避免重复执行。
3.如果任务是非幂等的,可以通过分布式锁(比如 Redis 锁)来确保任务只被执行一次。
6.性能方面有哪些考虑
1.XXL-JOB 的调度中心和执行器是分离的,调度中心的压力较小,但执行器的压力取决于任务量。
2.如果任务量很大,可以通过增加执行器节点来水平扩展。
3.对于耗时任务,可以考虑异步执行或者队列化处理。
7.日志管理和监控怎么做?
1.默认情况下,XXL-JOB 的任务日志存储在数据库中。
2.如果日志量很大,可以定期清理旧日志,或者将日志导出到外部存储(比如 Elasticsearch 或文件系统)。
3.还可以通过日志聚合工具(比如 ELK)来集中管理日志。
3.请讲一下在你的项目中是如何实现认证授权的?
标准回答
在我们的项目中引入了市面上比较流行的Spring Security,基于RBAC模型(权限跟角色绑定,用户通过拥有角色来获得权限)来进行JWT无状态的前后端分离的认证(authentication)授权(authorization)。
首先我们导入了相关依赖,然后注册了配置类SecurityConfig,注册了 BCryptPasswordEncoder来保证密码校验的安全。在里面放行了一些不需要登录就可以访问的接口,比如登录、登出、静态资源这些。其他所有请求都必须通过认证和授权才能访问。
1. 登录认证(Authentication)
当用户调用 /login 接口登录的时候,会传用户名和密码。我们会根据用户名从数据库里查出用户信息,然后用 BCryptPasswordEncoder 来校验密码对不对,如果没问题,就生成一个叫 userToken 的 UUID存入redis,并生成存储了用户信息的JWT Token,里面包含了用户的身份、角色以及具体的权限信息,存入redis中 并返回给前端。这样就算登录成功了。
2. 请求鉴权(Authorization)
每次用户发起请求时,都会经过我们自定义的授权管理器类,这个类实现了 Spring Security 的对应接口。在这首先会从请求头里拿到UUID(userToken),然后去 Redis 里找对应的 JWT Token。
接着解析这个 JWT Token,从中提取出用户信息(UserVo),其中包括了资源路径列表(UserVo的一个成员变量)。然后判断当前请求的 URL 是否在这些允许的路径里。如果是,就放行;否则就拒绝访问。 另外,这里还有两个额外的功能。1.自动续期的机制:当发现JWT Token剩下的有效期小于 10 分钟时就会自动续期,更新 Redis 里的缓存时间。这样用户在不感知的情况下就能完成续期,以防出现用户意外下线的情况。2.踢人”功能:如果 Redis 里最新的 userToken 跟请求里带的不一样,说明这个用户可能已被强制下线,此时会拒绝他的请求。
为什么选择SpringSecurity?
这套方案是无状态的,适合分布式部署,权限控制也比较灵活,后续如果要接入 OAuth2 或者多租户也很容易扩展。
(注意:授权管理器类是JwtAuthorizationManager ,对应接口是AuthorizationManager<RequestAuthorizationContext>)
(old:嗯~~好的,在我们的项目中引入了市面上比较流行的Spring Security基于RBAC模型来进行根据jwt无状态的前后端分离的认证(authentication)授权(authorization)的。首先我们导入了相关依赖,然后注册了配置类(securityconfig),注册了 BCryptPasswordEncoder来保证密码校验的安全。为对应的角色分配可以获得URL资源。拦截所有请求,除了静态资源和login和logout接口外都需要认证,在这里我们自定义了一个JwtAuthorizationManager来实现AuthorizationManager接口来完成自定义认证和授权。具体内容是解析token,获取里面的用户信息,同时判断当前用户资源是否包含当前URL,如果成功则返回授权成功,否则失败。当用户登陆时会调用login接口进行登陆功能,我们通过实现Userdetailservice来根据userName查询数据库获得用户信息进行认证,之后生成jwt(里面包含了用户的所拥有的资源角色等信息)返回给前端。)
然后我们引入了Spring Security来进行认证和授权。
认证的流程图:
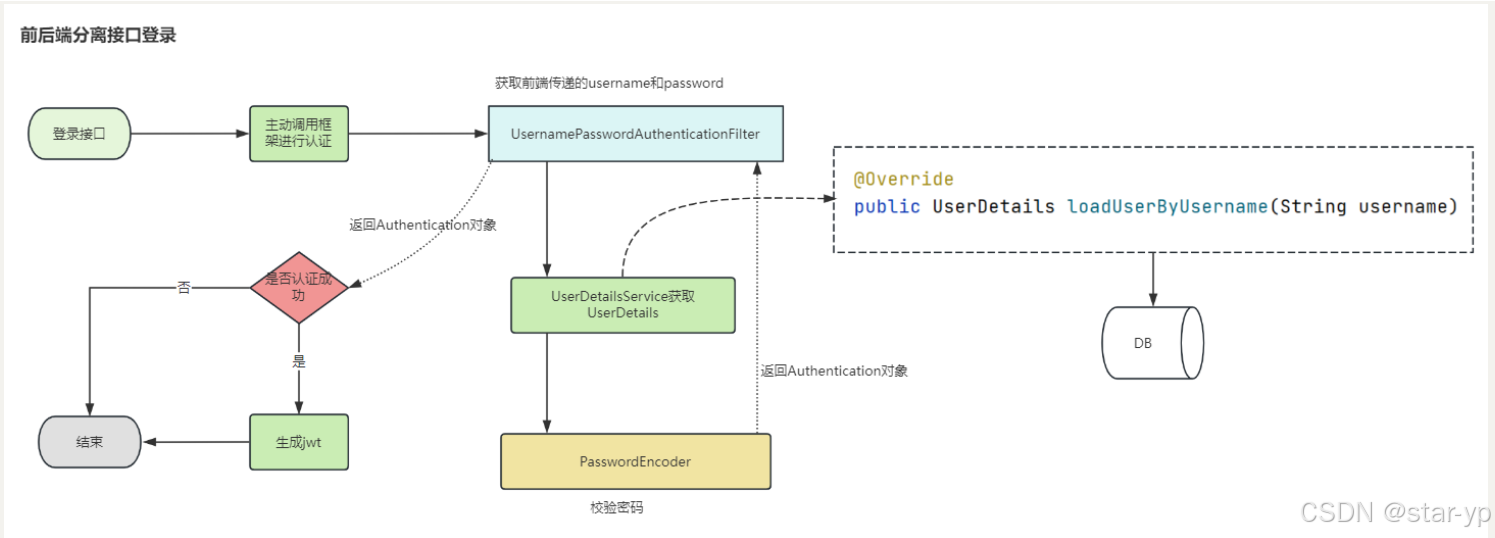
授权的流程图
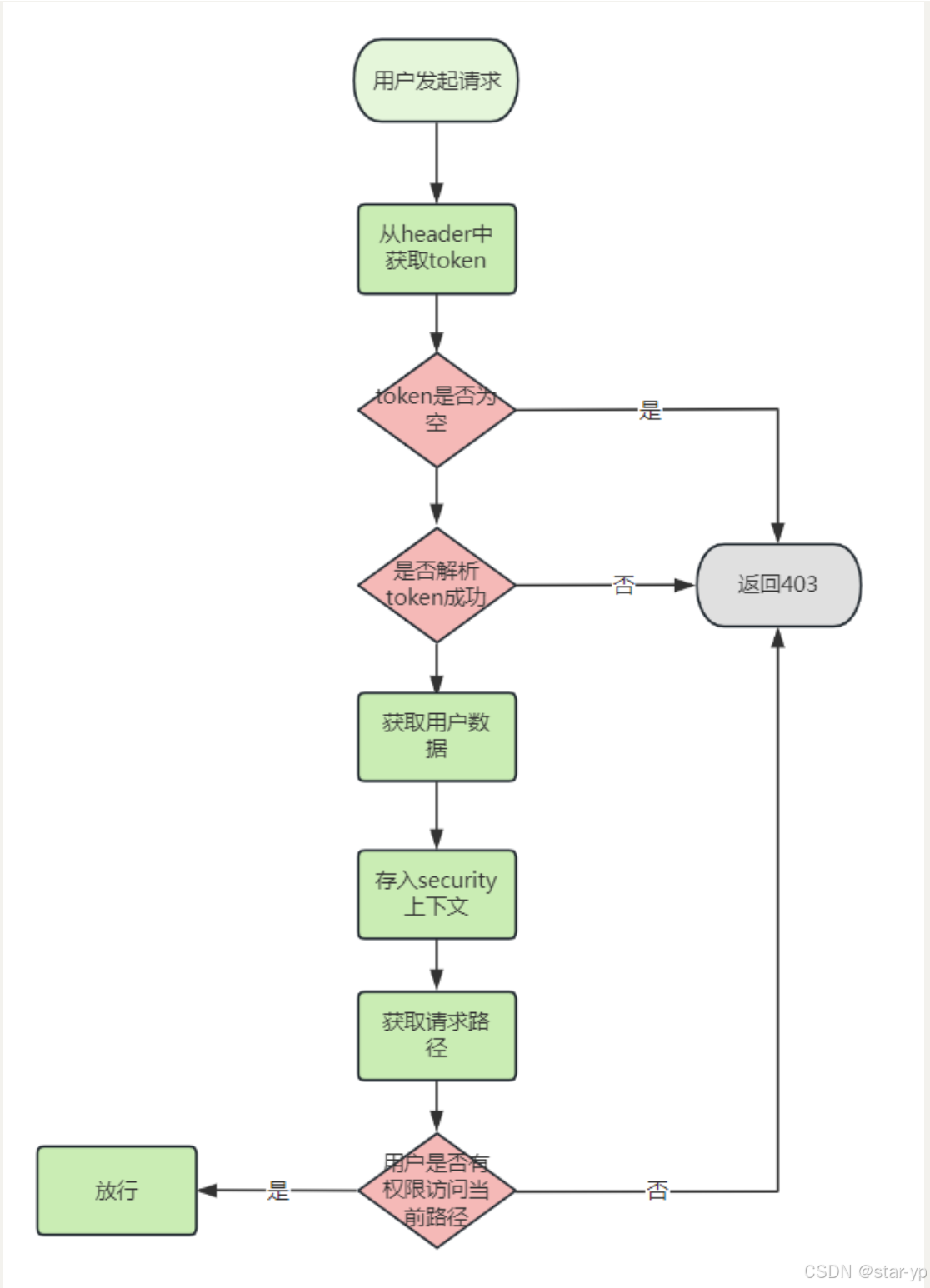
在本项目中的认证授权流程为:
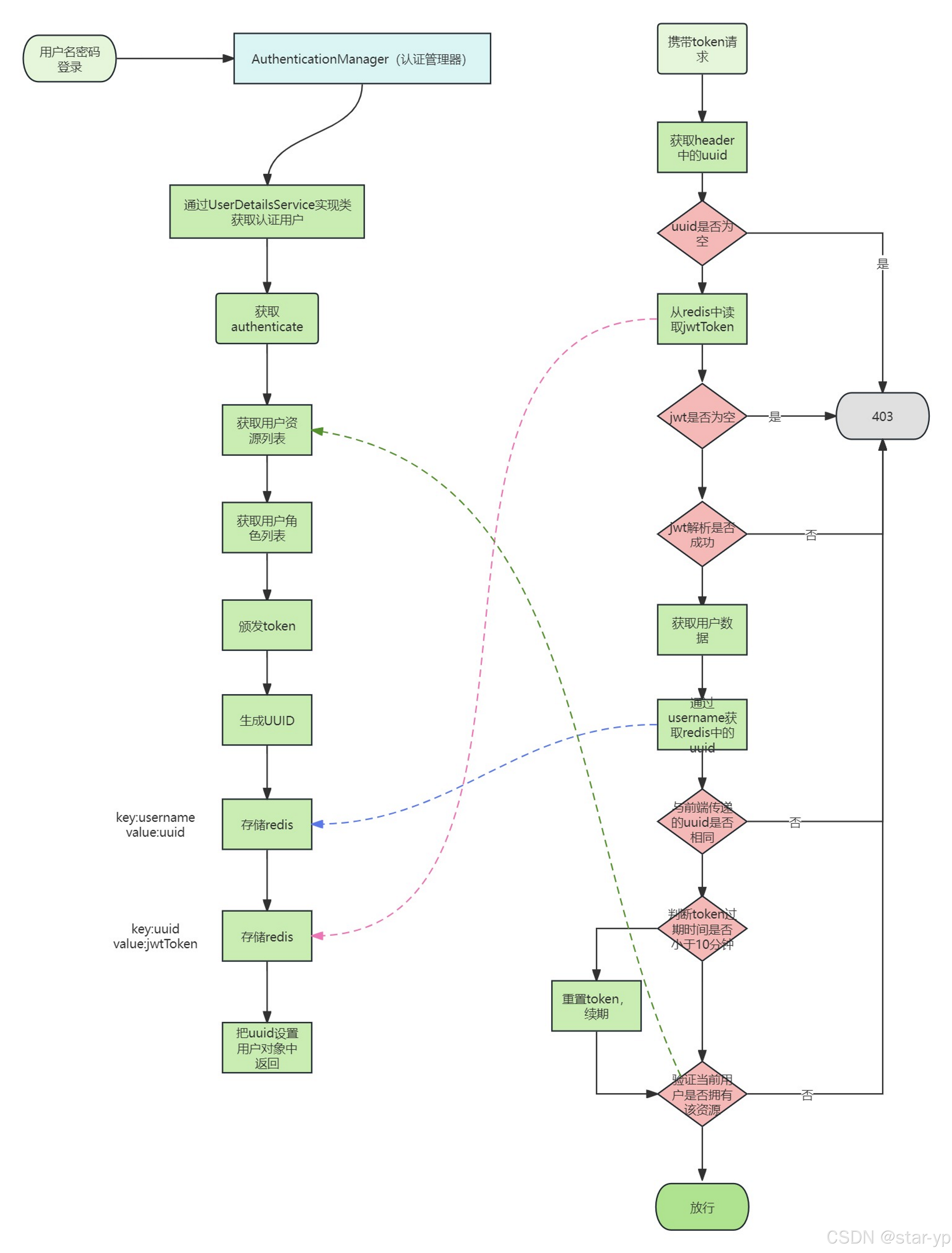
(流程回顾:)
1.你的项目中是如何实现认证的?
基于 JWT 的无状态认证:
用户登录时生成一个 JWT 令牌,将令牌放在 HTTP Header 中(通常是 Authorization: Bearer <token>)。
每次请求时,Spring Security 验证令牌的有效性。
2.如何实现自定义认证逻辑?
实现 UserDetailsService 接口,从数据库加载用户信息来和提交的信息比对是否正确进行认证的。
3.如何实现授权?
我们在项目中是通过基于 URL 的授权,在配置中指定哪些 URL 需要认证或特定角色才能访问,相比与基于方法的授权耦合度更低。
4.你遇到过哪些坑?
曾经遇到过 CSRF 防护导致前端请求失败的问题,通过禁用 CSRF 解决。
曾经遇到过 JWT 令牌过期后无法自动刷新的问题,通过引入 Refresh Token 解决。
5.Spring Security 与 Shiro 的对比?

6.springsecurity是怎么搭建的?
其核心特点是基于 JWT (JSON Web Token) 的无状态认证授权机制。具体搭建步骤和要点如下:
1.先引入其相关依赖
2.如何配置它的核心配置类:
使用 @Configuration 标记 SecurityConfig 类。
密码加密:注册了 BCryptPasswordEncoder Bean,用于对用户密码进行安全的哈希处理。
HTTP 安全规则 (SecurityFilterChain):
2.1 定义忽略路径:从配置文件 (SecurityConfigProperties) 读取不需要认证的 URL 列表(如登录接口、静态资源),并设置为 permitAll()。
2.1 JWT 授权:对于所有其他需要保护的请求,配置了一个自定义的 JwtAuthorizationManager。这个管理器负责拦截请求,解析请求头中的 JWT,验证其有效性,并根据 Token 中包含的用户信息(权限、角色)来决定是否放行。
禁用 CSRF:关闭了 CSRF 防护,因为 JWT 本身能提供一定的保护。
暴露 AuthenticationManager:将 AuthenticationManager 注册为 Bean,主要用于处理用户的登录认证请求(验证用户名/密码)。
4.你们的项目中是如何使用Spring Cache的?
嗯~~,好的,在我们查询部门数据的时候,特别是树形结构,要把所有的属性结构数据都展示出来,这个是会对数据库的访问造成一定的压力,并且从数据库查询效率也不是很高,所以我们通常都会添加缓存来提升效率。在我们的项目中我们使用了spring提供的Spring Cache框架来简化缓存操作。当第一次查询部门信息的时候会把信息放到redis里面,第二次访问可以根据key来访问redis缓存。当更新、添加、删除的时候会清除redis缓存里面的所有信息。
1.可以说一下Spring Cache的常用注解嘛?
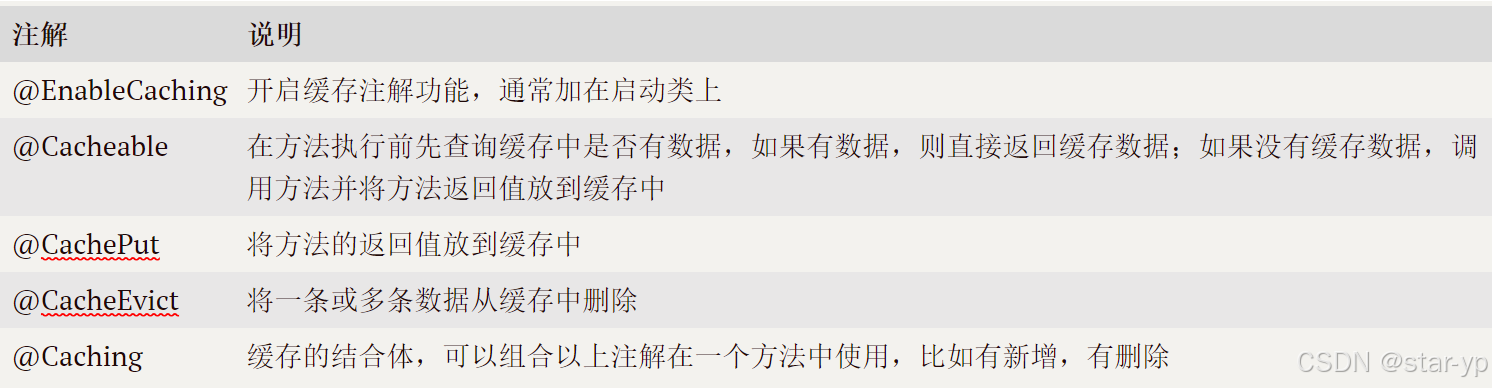
2.你们为什么不直接使用 Redis,而是选择了 Spring Cache?
嗯~~~,其实这个问题我也思考过。当时我们项目里确实也想过直接操作 Redis,但后来还是选择了 Spring 提供的 Spring Cache 框架。说白了,我们通过 Spring Cache 来统一管理 Redis 的缓存操作。这样做的话 开发效率更高,代码也更干净。
我们有一个部门树的接口,每次访问都要查数据库、递归组装成树形结构,数据量一大响应就慢。为了提升性能,我们就加了个缓存。这时候如果自己写 Redis 的代码,就得考虑 key 怎么设计、值怎么序列化、异常怎么处理等等,挺麻烦的。而用了 Spring Cache 之后,只需要一个注解 @Cacheable,就能把第一次查询的结果自动缓存到 Redis 里,下次请求直接走缓存,特别方便。修改或新增部门的时候,再用 @CacheEvict 把缓存清掉,保证数据一致性。而且还有一个很重要的点是:Spring Cache 是一个统一的抽象层,如果我们以后想换成本地缓存比如 Caffeine 或者别的缓存中间件,改起来也更容易,不需要动业务代码。
当然啦,如果是那种对性能要求特别高、操作特别复杂的场景,比如要控制 Redis 的过期策略、数据结构、或者要用 Lua 脚本之类的,那可能还是得直接操作 RedisTemplate 会更灵活一些。
所以我们在项目中选择 Spring Cache + Redis,主要是为了兼顾开发效率和系统性能,这种做法相对来说比较平衡。
三.高频问题(简历上并没有写,但会问的):
1.你可以简单的介绍一下你的项目嘛?
把行业背景,自己负责的部分(整体业务流程),系统架构,技术架构顺一遍,ai协助提高开发效率(ChatGPT协助编写swagger注释、)
2.你在其中的角色和贡献(业务方面)?
1.服务管理,包括:护理等级、护理计划、护理项目、负责老人、任务安排这5个子模块。
2.预约管理
预约分为了两种,分别是探访预约和参观预约
- 探访预约是指家里有老人已经入住了养老院,家人可以点击探访预约,看望绑定的老人
- 参观预约是指想要参观一下养老院,了解养老院的环境、设施及服务情况
3.部门管理
4.岗位管理
5.老人入住全流程
3.为什么选择这些技术而不是其他替代方案?
4.你们遇到了哪些主要的技术挑战或困难?是如何解决的?
5.在你的项目里,有没有做过性能调优?如果有,请具体说明你是如何做的。
6.如果有机会重新设计这个系统,你会做出哪些改变?为什么?
我会考虑引入微服务架构,将系统拆分为更小的服务单元,以便于扩展和维护。同时,我会加强系统的可扩展性设计,为未来的功能扩展预留更多空间


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









