






- 开启三台linux虚拟机
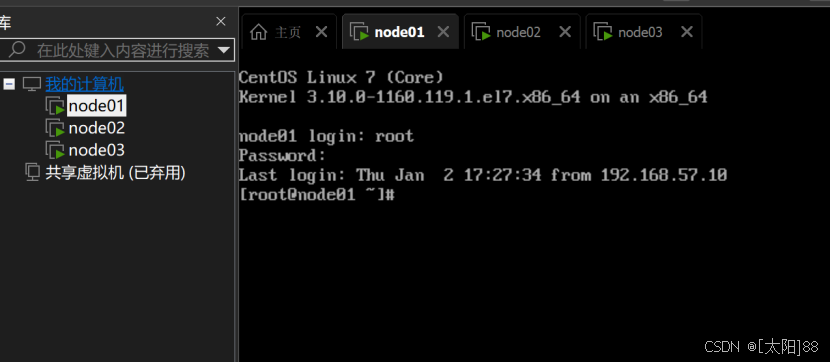
2.准备好spark的压缩包
步骤:
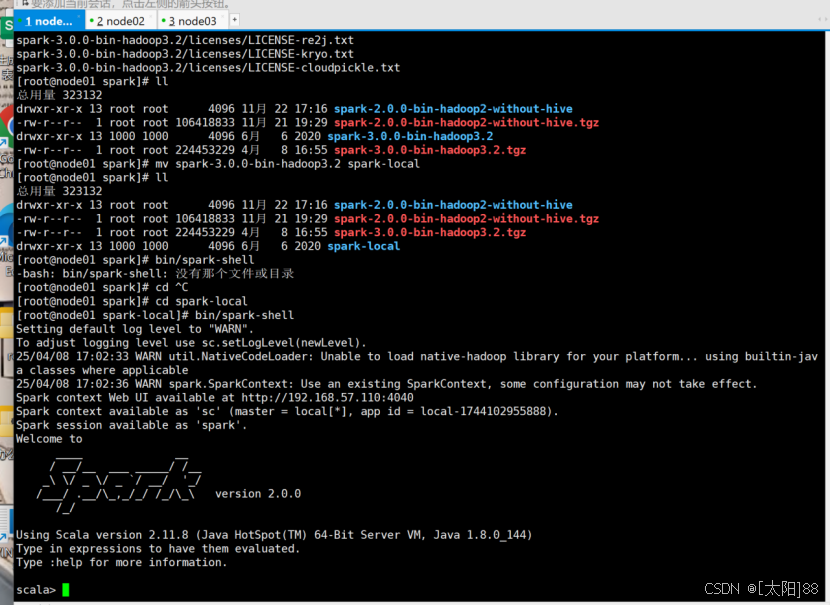
- 将spark的安装包上传到虚拟机node01中(建议路径:/opt/software/spark)并解压缩文件。将解压文件夹重命名为spark-local
解压:tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz
重命名:mv spark-3.0.0-bin-hadoop3.2.tgz spark-local
- 启动Local环境。进入spark-local中,执行如下命令:
bin/spark-shell
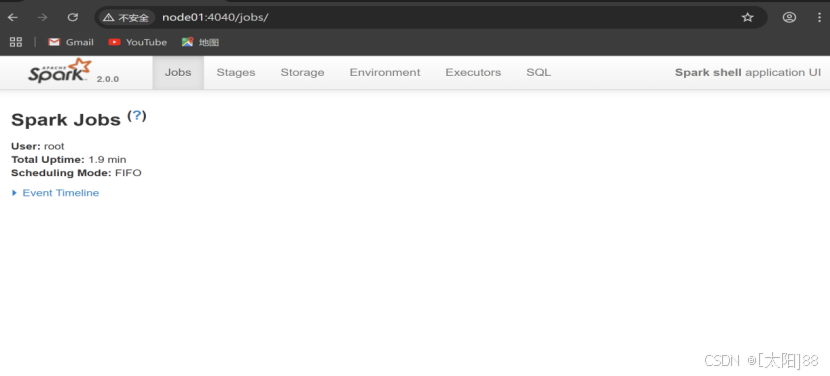
启动成功后,可以输入网址进行Web UI监控页面进行访问。
- 命令行工具
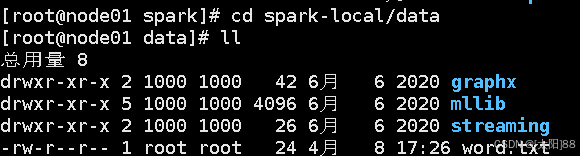
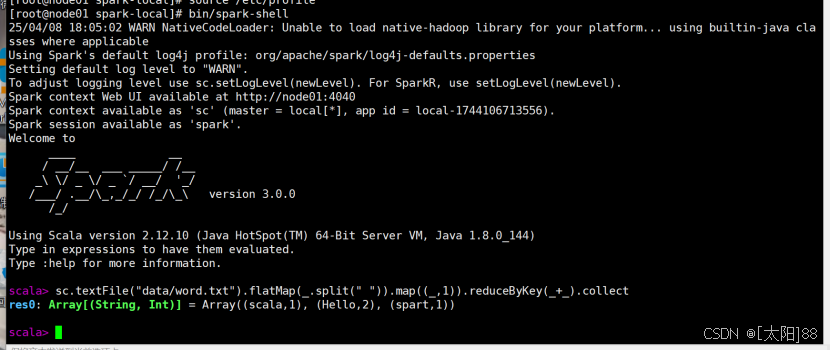
在解压缩文件夹下的 data 目录中,添加 word.txt 文件。

在命令行工具中执行如下代码指令。
sc.textFile("data/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
- 提交测试应用
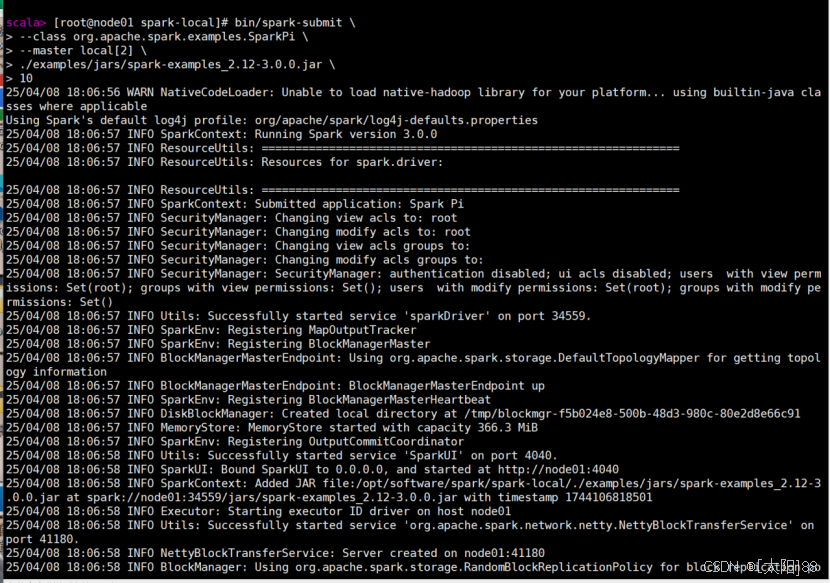
在spark-local路径中输入以下指令:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.0.0.jar \
5.
指令说明:
1) --class 表示要执行程序的主类,此处可以更换为咱们自己写的应用程序
2) --master local[2] 部署模式,默认为本地模式,数字表示分配的虚拟 CPU 核数量
3) spark-examples_2.12-3.0.0.jar 运行的应用类所在的 jar 包,实际使用时,可以设定为咱们自己打的 jar 包
4) 数字 10 表示程序的入口参数,用于设定当前应用的任务数量
运行结果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









