







欢迎拜访:雾里看山-优快云博客
本篇主题:枚举、联合、大小端计算
发布时间:2025.1.15
隶属专栏:C语言

枚举
概念
枚举顾名思义就是一一列举,把可能取到的值一一列举出来。枚举的内容必须是有限的。
例如:
一周有七天,从星期一到星期日时可以一一列举出来的。
性别有:男,女,保密, 也可以一一列举。
月份有十二个月,从一月到十二月也是可以一一列举出来的。
对于以上情况可以使用枚举。
定义
在C语言中,实现枚举需要使用 enum 关键字。
enum Day//星期
{
Mon,//成员之间用逗号隔开
Tues,
Wed,
Thur,
Fri,
Sat,
Sun//最后一个成员后面不加逗号
};//结尾加分号
enum Sex//性别
{
MALE,
FEMALE,
SECRET
};
enum Month//月份
{
Jan,
Feb,
Mar,
Apr,
May,
Jun,
Jul,
Aug,
Sep,
Oct,
Nov,
Dec
};
以上的enum Day, enum Sex, enum Month 都被称为枚举类型。{}中的内容是枚举类型的可能取值,也叫枚举常量。
这些可能取值是有大小的,默认从 0 开始, 每次递增一,或者在定义的时候赋初始值。
例如:
enum Color//颜色
{
RED = 1,
GREEN = 3,
BLUE = 4
};
优点
C语言可以使用#define 定义常量,为什么非要使用枚举?
枚举的优点:
- 增加代码的可读性和可维护性。
#define定义的标识符没有类型检查,枚举类型有,更加严谨。- 枚举进行了封装,避免了命名污染。
- 便于调试。
- 使用方便,一次可以定义多个常量。
使用
枚举类型的使用可以在日志中有较好的体现。
enum Level
{
DEBUG = 0,//调试
INFO,//常规
WARING,//警告
ERROR,//错误
FATAL//致命
};
enum Level log = DEBUG;
只有使用枚举常量对枚举变量进行赋值,才不会出现问题
联合
概念
联合是C语言里一种特殊的自定义类型,这种类型的变量包含一系列成员,特征是这些成员共用同一块内存空间。(联合体特可以称为共用体)
定义
//联合体的声明
union Un
{
char c;
int i;
};
//联合体的定义
union Un un;
//联合体的大小
printf("un = %d\n", siozeof(un));
特点
联合体的成员是共用同一块内存空间的,为了能保证存下任意一个成员,所以一个联合变量的大小,至少是最大成员的大小。
#include <stdio.h>
int main()
{
union Un
{
int i;
char c;
};
union Un un;
// 下面输出的结果是一样的吗?
printf("%p\n", &(un.i));
printf("%p\n", &(un.c));
//下面输出的结果是什么?
un.i = 0x11223344;
un.c = 0x55;
printf("%x\n", un.c);
printf("%x\n", un.i);
return 0;
}
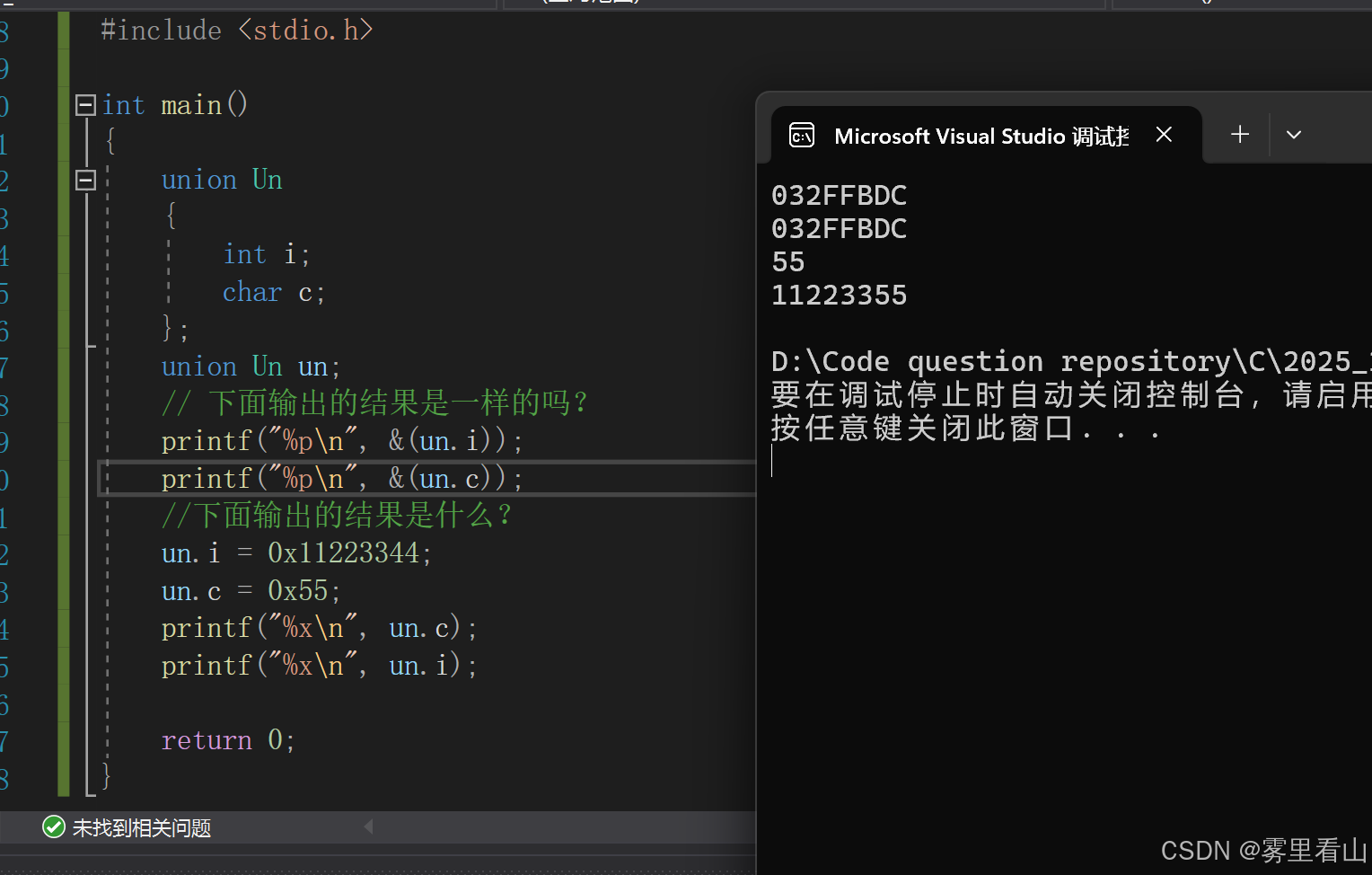
从运行结果可以看出,变量i 和 c的起始地址一样,说明用的是同一块内存空间。
大小计算
- 联合体的大小至少是最大成员的大小。
- 当最大成员大小不是最大对齐数的整数倍的时候,需要对齐到最大对齐数的整数倍。
例如在最大对齐数为8的环境下:
#include <stdio.h>
int main()
{
union Un1
{
char c[5];//大小为5
int i;//大小为4
};
union Un2
{
short c[7];//大小为14
int i;//大小为4
};
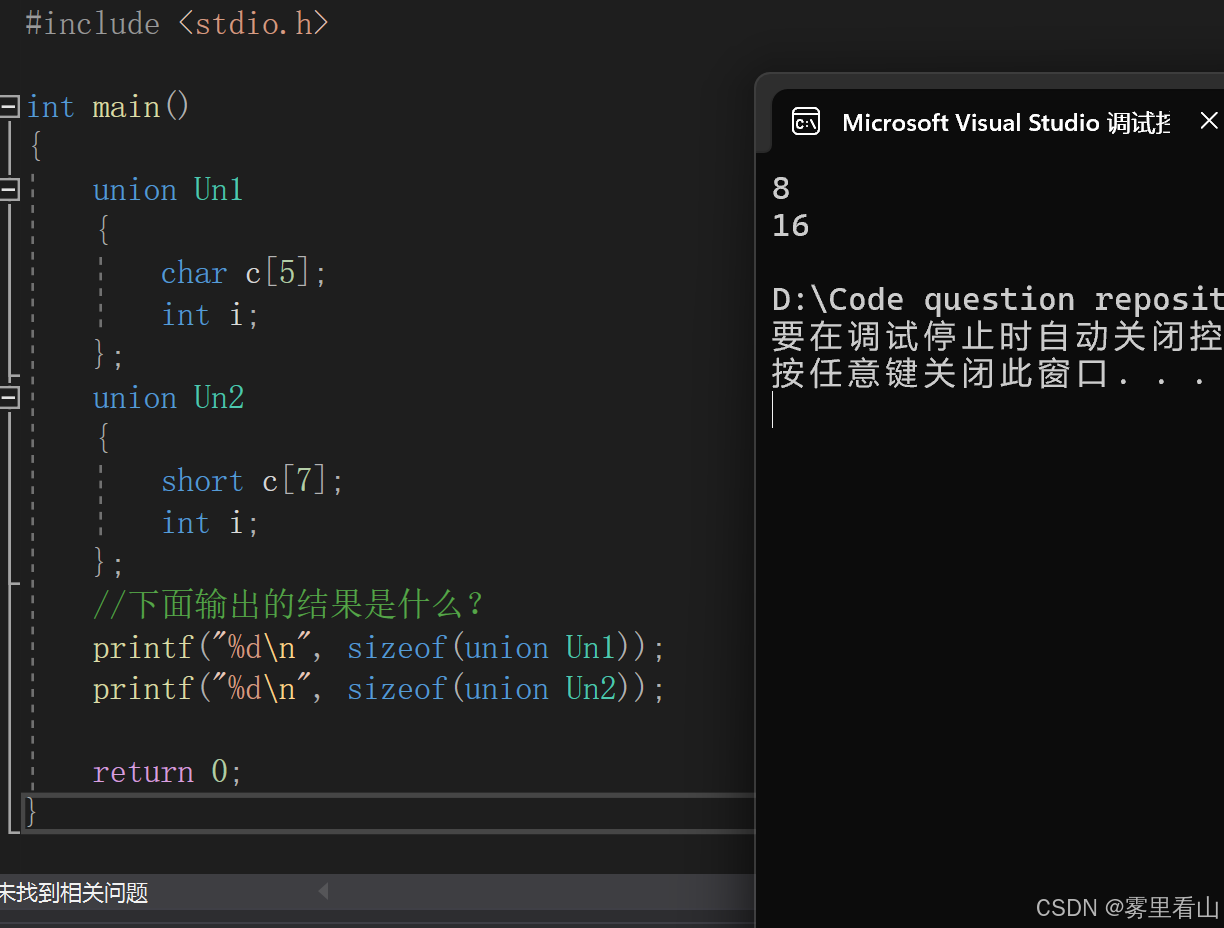
//下面输出的结果是什么?
printf("%d\n", sizeof(union Un1));
printf("%d\n", sizeof(union Un2));
return 0;
}
机器大小端
字节序
计算机是以二进制的形式将数据存储到内存中,内存的基本单位是字节(Byte),内存的读写是以字节为单位的。1 Byte = 8 bit。当我们需要存储的数据超过一个字节所能存储的大小时,就会将多个字节连在一起,例如 char是一个字节int是四个字节double是八个字节。
那么将多个字节依次存储到内存中时, 就会有顺序的区分,这种顺序,也被称为字节序。
因为数据的不同,所以出现了大小端的概念。
什么是大小端
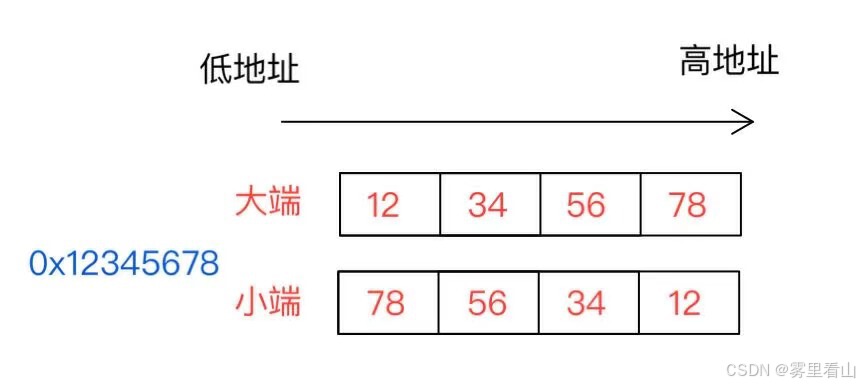
大端模式:高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
大端字节序有符号数的最高位占据内存最低地址,符号位的判定固定在第1个字节处,符号直接可以取出来,容易判断正负;另外大端字节序更贴近从左到右的书写方式,所以更符合我们人类的习惯
大端常常用于网络协议,被称为网络端序,大端用于网络协议,并不意味它比小端多好,而是网络的核心是通信,所以大家必须要有共同的标准,即网络通信的标准化
所以在TCP/IP协议中,RFC1700规定使用大端字节序为网络字节序,如果使用小端的计算机,接发数据时需要自行将主机字节序转换为网络字节序
小端模式:低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
小端字节序序最大的好处是强制转换数据类型效率较高,比如小数强制转大数只需要在高位添0;如果大数强制转小数,直接将高位数据丢弃即可,不需要额外再调整宇节。
大小端的历史
1960s:大小端的概念最早可以追溯到20世纪60年代,IBM的System/360系列计算机采用了大端字节序。这种字节序的设计与人类阅读数字的方式相似,即从高位到低位。
1970s:在20世纪70年代,DEC公司推出了PDP-11系列计算机,采用了小端字节序。小端字节序的优势在于,对于多字节整数的部分访问和计算更加方便,因为低位字节总是存储在最低的地址。
1980s:随着计算机技术的发展,许多不同的处理器架构开始出现。例如,Motorola 68000系列处理器采用大端字节序,而Intel x86系列处理器采用小端字节序。这导致了计算机领域内的大小端之争。
1990s:在20世纪90年代,随着网络技术的普及,计算机之间的数据交换变得越来越重要。因此,网络字节序(Network Byte Order)的概念应运而生。网络字节序采用大端字节序,以确保不同处理器架构之间的数据交换能够顺利进行。
2000s至今:在21世纪,计算机技术继续发展,处理器架构也趋于多样化。许多处理器,如ARM和PowerPC,支持大小端可配置,使得系统设计者可以根据实际需求选择合适的字节序。此外,一些编程语言和库也提供了跨平台的字节序转换功能,以便在不同字节序的系统之间进行数据交换。
在早期的计算机体系结构中,大端字节序是主流的存储方式。但是,后来随着英特尔处理器的流行,小端字节序逐渐成为主流。英特尔处理器采用小端字节序的主要原因是,其实现简单且效率高。同时,小端字节序的处理方式也更符合人的直观感觉,因为我们通常是从低位到高位依次读取数据。总之,大小端的发展历史反映了计算机技术的演进和处理器架构的多样化。如今,大小端问题已经不再是一个严重的障碍,因为现代处理器和软件都提供了灵活的解决方案来应对字节序差异。
如何判断大小端
- 利用指针进行判断。
bool IsLittleEndian()
{
short x = 0x1234;
char *y = (char*)&x;
if(*y == 0x34)
return true;
return false;
}
- 利用联合体进行判断
union Un
{
int i;
char c;
};
bool IsLittleEndia()
{
union Un un;
un.i = 0x12345678;
if(un.c == 0x78)
{
return true;
}
return false;
}
- 利用Linux系统函数
bool IsLittleEndia()
{
if(0x01 != htons(x01))
{
return true;
}
return false;
}
- 通过编译器内存检测窗口进行查看
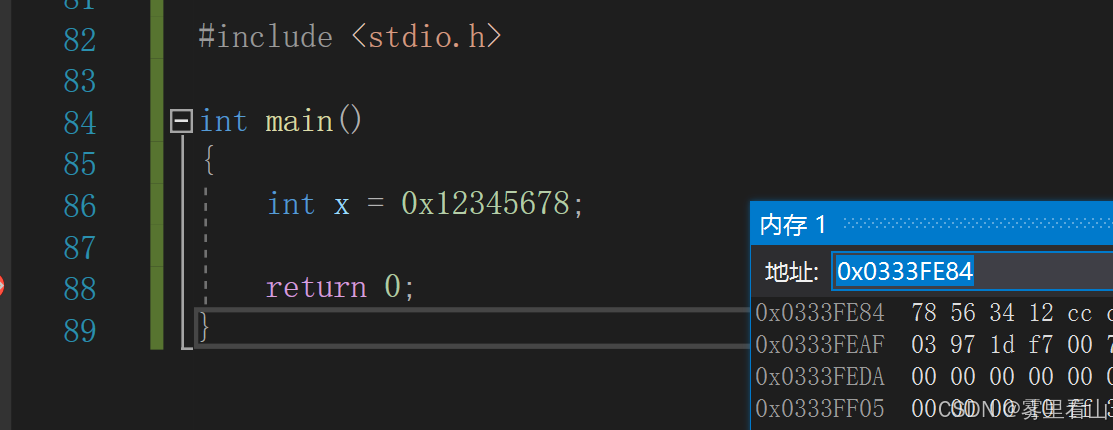
可以根据内存判断我使用的机器是小端的。
⚠️ 写在最后:以上内容是我在学习以后得一些总结和概括,如有错误或者需要补充的地方欢迎各位大佬私信我交流!!!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











