






第6节课 函数基础、变量与函数内存分析
对于任何一个知识点,必须讨论的三个问题:
(1)它是啥
(2)为啥有它
(3)它能干哈
- 注释:注解说明程序代码;帮助程序员提高代码的阅读性、可读性;单行、多行
- 内置基本数据类型:就是程序中最基础的计算单元
- 运算符:就是提供方式来计算数据单元
- 关键字:程序中提供的具有特殊含义的单词,为了提供最基本的程序功能,定义数据类型、提供程序结构
- 标识符:为程序当中自定义的一些数据进行命名(变量、函数、对象、类),方便调用\引用数据
- 循环:处理重复执行代码,这些代码之间必须是有规律性的,降低代码量,减少代码冗余。
- 内置函数\内置模块:int()、print()、input()…random time math ,就是Python中提前封装好的一些功能/工具,可以方便用户快速调用,实现程序逻辑,而不需要用户从新开始创建该功能,“避免重复造轮子”。但是,用归用,最为初学者,我们必须要懂得底层的逻辑。
1.函数定义与调用
函数也是用于处理重复性代码问题的,这些代码是具有独立功能性的,我们可以将这些类似的代码进行一次封装(函数),之后再想去实现同样的功能时,可以直接复用曾经写到的这个函数。
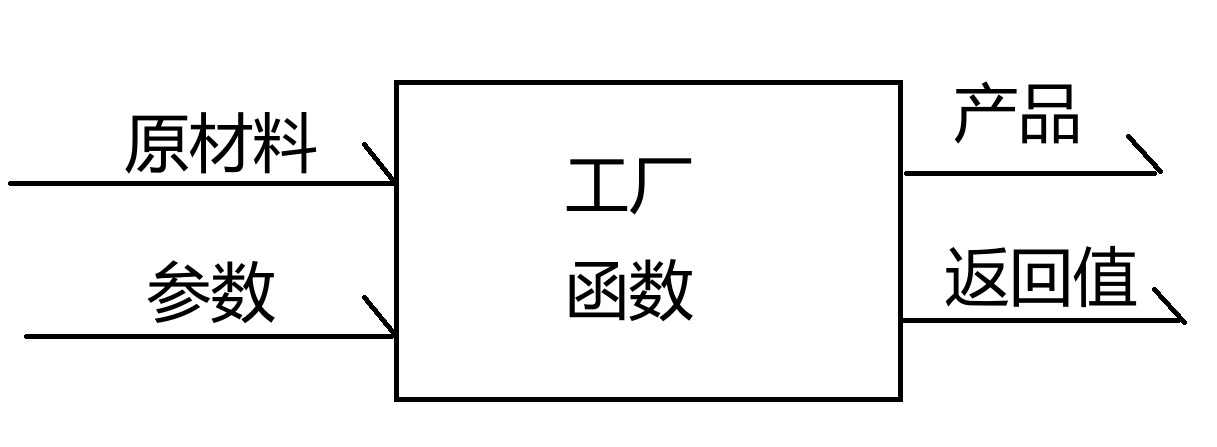
在Python中如何定义函数,语法结构:
def 函数名(参数列表):
函数体
return 返回值
def sum(a, b):
return a + b
- def :定义函数的关键字
- 函数名:自定义的函数名称,规则与标识符一致的;所有单词字母小写,单词之间用下划线分隔。
- 参数列表:就是给函数传递的一些原始数据,函数根据这些数据去做具体的计算。参数可以不指定数据类型。
- 函数体:就是上述说的具体的计算,今后在编写函数时,一定要注意缩进的问题
- return:直译 返回,实际上表示结束函数(将函数进行弹栈操作),如果有返回值的话则将结果返回给函数的调用者,如果没有返回值的话return可以不写,但不代表不存在,它是隐藏的
- 返回值:就是程序计算的结果,需要给调用者传递结果的话,就将结果写在return之后即可。
在C语言中:
int sum(int a, int b) {
return a + b;
}
- int:返回值类型 就是计算结果的数据类型
- sum:函数名
- int a, int b:参数列表,表示传递两个整数数字 -> 形式参数
- return a + b:结束函数同时将计算的结果返回给调用者的
如果给Python函数指定数据类型的话:
今后在校招笔试题当中,编程题的Python代码,大部分都会指定参数和返回值类型
def sum(a:int, b:int) -> int:
return a + b
- a:int, b:int:指定形式参数的类型
- -> int:指定返回值的类型
def sumA(a, b):
return a + b
def sumB(a:int, b:int) -> int:
return a + b
res = sumA(1,3)
print(res)
print(sumA(3.14, 5.34))
print(sumA("Hello", "Wolrd"))
res = sumB(1,3)
print(res)
print(sumB(3.14, 5.34))
print(sumB("Hello", "Wolrd"))
可以发现,上述代码中sumA和sumB的运行结果是一致的,sumB中指定参数类型和指定返回值类型实际上没有效果的,这么写的目的就是为了方便调用者了解函数的参数和返回值的情况,提供建议,方便调用使用,而不是强制要求类型,增加了函数代码的可读性
def kajsbhgdjhahsdjvgja(a, b, c):
pass
def 根据三边计算三角形面积(a, b, c):
NameError: name ‘is_prime’ is not defined
函数必须先定义后调用!!!
判断素数
# 关于函数返回值为布尔类型情况下,函数名的规范问题
# 以is开头 增加可读性
print(is_prime(13)) # NameError: name 'is_prime' is not defined
def is_prime(num):
for i in range(2, num // 2 + 1):
if num % i == 0:
return False
return True
print(is_prime(12))
在Python中实际上没有主函数的(程序的入口),Python的执行是从第一行代码开始逐行执行。如果非要写主函数的话,也可以这么操作:
- 假main():依旧是我们自定义的函数,模拟模仿一下主函数的功能
def main():
num1 = 12
num2 = 13
print(is_prime(num1)) # NameError 执行到此处时并没有发现is_prime的定义
print(is_prime(num2))
main()
def is_prime(num):
for i in range(2, num // 2 + 1):
if num % i == 0:
return False
return True
# 以下代码不报错的原因在于:两个函数的定义都已经确定了,无非就是执行顺序的问题
def main():
num1 = 12
num2 = 13
print(is_prime(num1))
print(is_prime(num2))
def is_prime(num):
for i in range(2, num // 2 + 1):
if num % i == 0:
return False
return True
main()
- 以模块的形式测试执行
def is_prime(num):
for i in range(2, num // 2 + 1):
if num % i == 0:
return False
return True
# 目前为止,简单认为是主函数
if __name__ == "__main__":
num1 = 12
num2 = 13
print(is_prime(num1))
print(is_prime(num2))
2.函数的返回值
一般有三种情况:
- 无返回值:实际上是有返回值的
None
def printName(name):
print(name)
return
ret = printName("Hello")
print(type(ret))
-
单返回值:不多说,看上面的例子
-
多返回值:在C\Java中,如果需要多返回值的话,一般都是将数据封装在一个数组或类似的序列当中,把数组或类似的序列当成一个单返回值返回的。
# Java
public int[] getPoint() {
# 获取一个坐标点 x, y
# return x, y; # 错误的
return new int[]{x, y};
}
# Python
def get_point():
# 返回坐标点的x和y数据的话
x = 10
y = 12
return x, y
x, y = get_point()
print(x, y)
# 接受变量的个数必须与返回的个数一致!
# ValueError: not enough values to unpack (expected 3, got 2)
x, y, z = get_point()
print(x, y, z)
def get_point(): # 返回坐标点的x和y数据的话 x = 10 y = 12 return x, y ret = get_point() print(ret) print(type(ret)) # (10, 12) # <class 'tuple'>实际上多返回值的思路和C\Java当中的一样,都是是将多数据进行了封装,Python是以元组的方式进行多返回值封装的。
a, b, c = map(int,input("输入三个数字:").split(" ")) print(a,b,c) ret = map(int,input("输入三个数字:").split(" ")) print(ret) print(type(ret)) # 以map映射的方式返回的 # <map object at 0x0000017431ADA140> # <class 'map'> ret = eval(input("输入三个数字:")) print(ret) print(type(ret)) # (1, 2, 3) # <class 'tuple'>
3.局部变量与全局变量
- 全局变量:定义在函数外部的变量,作用域是整个程序文件,即就是在文件的任何函数内部都可以访问的。
- 局部变量:定义在函数内部的变量,作用域是所属的函数,只能在函数内部调用,外面访问不到。
num = 10 # 全局变量 创建
def show():
num = 20 # 局部变量 创建
print(num) # 局部变量 输出20
show()
print(num) # 全局变量 输出10
####################################
num = 10
def show():
num = 10 # 局部 创建
# UnboundLocalError: cannot access local variable 'num' where it is not associated with a value
# 程序认为num是局部变量 这里给局部变量进行了 += -> num = num + 10 前提需要num有定义或者值
num += 10 # 局部 修改 但是局部没有初始化
print(num)
show()
print(num)
####################################
num = 10
def show():
global num # 声明该函数中的num是全局变量
num = 20
num += 20
print(num) # 40
show()
print(num) # 40
####################################
numA = 10 # 全局 创建
def show():
numA = 20 # 局部 创建
numB = 30 # 局部 创建
print(numA, numB) # 20 30
show()
# NameError: name 'numB' is not defined. Did you mean: 'numA'?
print(numA, numB) # numA全局 程序认为numB全局 但是没找到定义 所以报错
# 反推出 函数中的局部在外部访问不到
####################################
num1 = 10 # 全局 创建
num2 = 20 # 全局 创建
def show(num1, num2): # 形式参数 也是函数内部的局部变量 创建并赋值
# 简单理解为 函数内部如果没有global声明,一律当做局部看待
num1 = 30 # 局部 修改
num2 = 40 # 局部 修改
print(num1 + num2) # 70
return
show(num1, num2) # 实际参数 调用了全局的num1和num2 将值 传递给 形式参数
print(num1 + num2) # 全局
####################################
num1 = 10 # 全局 创建
num2 = 20 # 全局 创建
def show(num1, num2): # 形式参数 也是函数内部的局部变量 创建并赋值
# 全局变量和局部变量同时在函数中使用时 全局和局部不要重名!
global num1 # SyntaxError: name 'num1' is parameter and global
num1 = 30
num2 = 40 # 局部 修改
print(num1 + num2) # 70
return
show(num1, num2) # 实际参数 调用了全局的num1和num2 将值 传递给 形式参数
print(num1 + num2) # 全局
####################################
num = 10
def show():
# 分不清局部和全局的话 重点突看 num 在函数中 有无定义 默认全局
print(num)
# 一般不推荐使用 会造成变量二义性
show()
总结:
- 函数内部要使用全局变量时,进行全局声明
global - 函数内部但凡没有
global,变量一律当局部处理 - 全局变量和局部变量同时在函数中使用时,不能重名
- 形式参数一律都是函数内部的局部变量
- 实际参数仅仅是将**“址”**传递给了形式参数
2、 变量与函数内存分析
1.Python中变量的本质
- 静态编译型语言:C、C++、Java
- 编译型:源代码不能直接交给计算机运行,必须先编译,生成可执行的二进制文件,再将该二进制文件交给计算机执行。C/C++编译的二进制结果
.exe文件,Java编译的二进制结果.clss文件。【将一本英语书翻译为中文书】 - 静态:变量的定义必须声明数据类型,而且基本数据类型的数据是直接存储在变量内部的!(C\C++的指针和Java中的引用数据类型除外)
- 编译型:源代码不能直接交给计算机运行,必须先编译,生成可执行的二进制文件,再将该二进制文件交给计算机执行。C/C++编译的二进制结果
- 动态解释型语言:Python、JS
- 解释型:源代码依旧不能直接交给计算机运行,也是必须先编译,但是可以不生成二进制文件,二进制的代码在内存中临时存储的,运行的时候就是将二进制代码按照编译的顺序依次执行。【同声传译】
- 动态:变量的定义不需要声明数据类型,数据存储在堆内存中的,变量仅存储数据对象在堆内存中的地址而已。
# Java
public class Demo {
public static void main(String[] args) {
int a = 1231231231; //范围没超
int b = 100; //范围没超
int c = a * b; //暂时不确定 只有运行的时候才能确定大小
// 整型溢出
System.out.println(a * b);
}
}
# C
#include<stdio.h>
#include<stdio.h>
void main(){
// overflow in implicit constant conversion
// 存不下了
int a = 123123123123;
printf("%d\n", a);
}

num = 1
print(num)
print(type(num)) # <class 'int'>
print(id(num)) # 140731596990904
num = 3.14
print(num)
print(type(num)) # <class 'float'>
print(id(num)) # 1998567916656
num = "Hello"
print(num)
print(type(num)) # <class 'str'>
print(id(num)) # 1998567809472
xixi = num
# 假设xixi和num都嗝屁了 上述三个数据对象怎么办?
# 没有被任何变量指向的对象,则成为垃圾,则被GC垃圾回收器自动回收
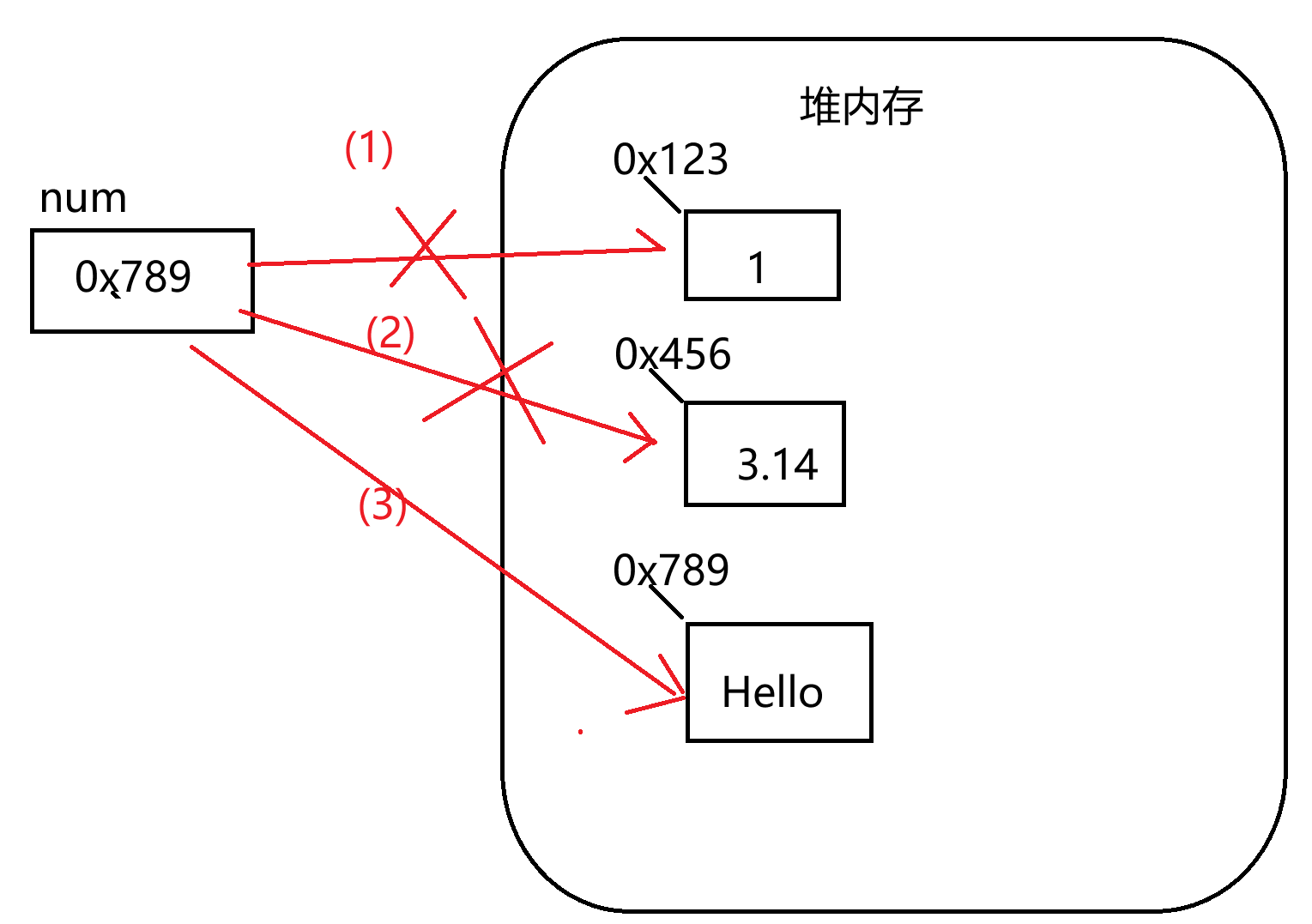
print("Hello")
haha = print
haha("World")
print = 1
haha(1 + 2)
haha(print)
print(1 + 2) # TypeError: 'int' object is not callable
"""
使用type()查看类型 id()查看地址
"""
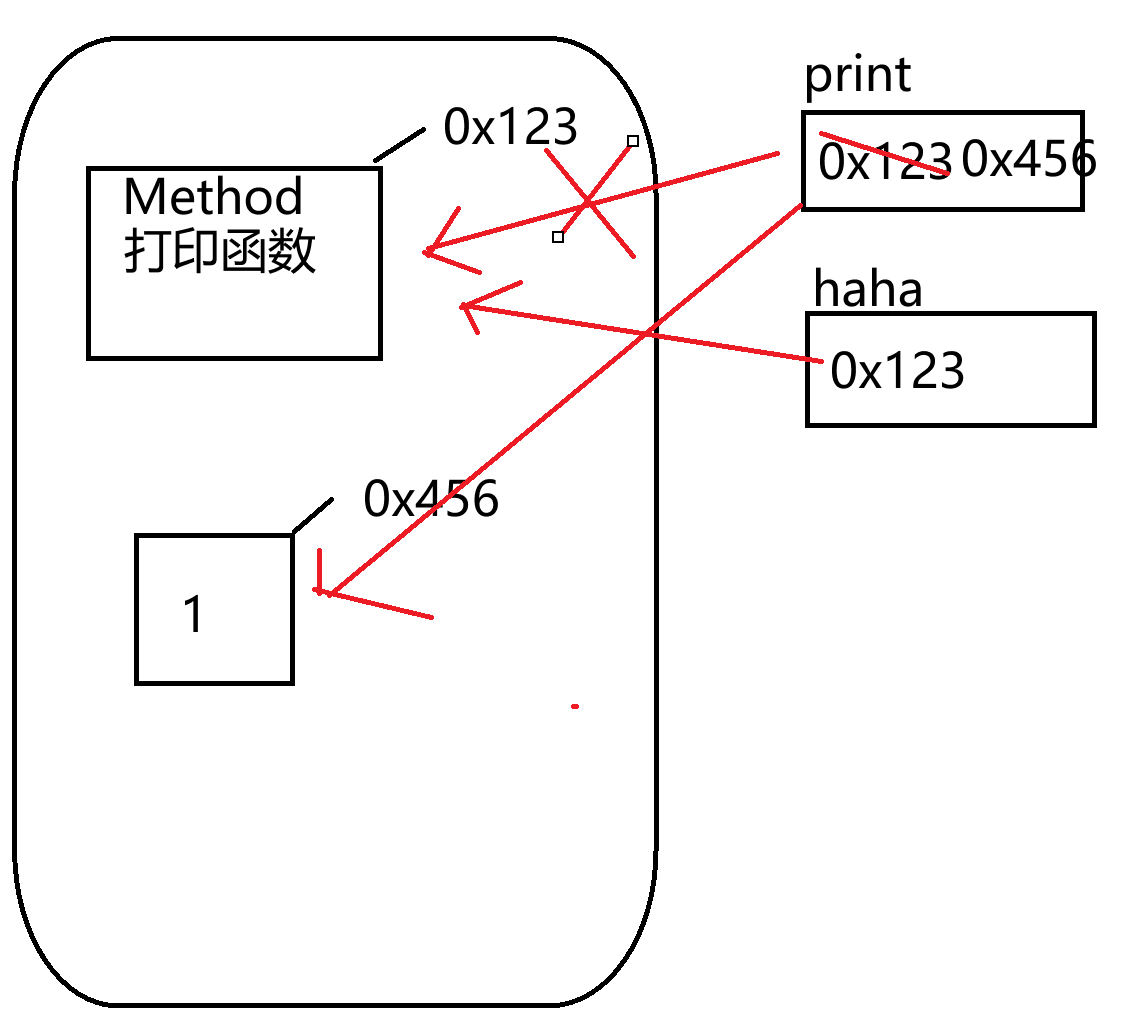
总而言之,在Python中,变量(包含函数名)一律存储的数据对象在堆内存中的地址!
def show(a, b):
print(a + b)
return
test = show
print(test(1,2))
2.常量驻留问题
常量驻留是一种优化机制,它允许Python在内存中之保留一份特定值的副本,而多个变量可以引用这个相同的副本。这样做的目的,为了节省内存空间,并提高某些操作的效率。
- 小整数驻留问题
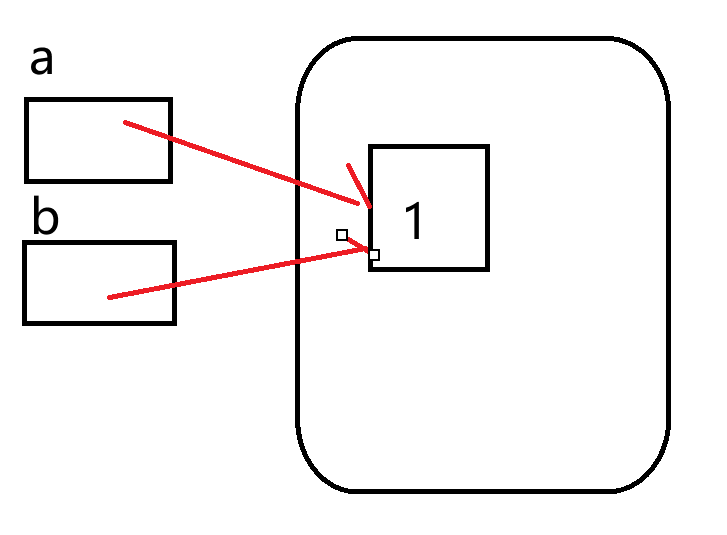
>>> a = 1
>>> b = 1
>>> a == b # 指向的对象内容是否一致
True
>>> a is b # 指向的是否是同一个对象
True
解释:a变量和b变量存储的是数据对象1的内存地址,只有一个1的数据对象。
>>> a = 300
>>> b = 300
>>> a == b
True
>>> a is b
False
解释:a变量和b变量存储的是数据对象300的内存地址,有两个300的数据对象。
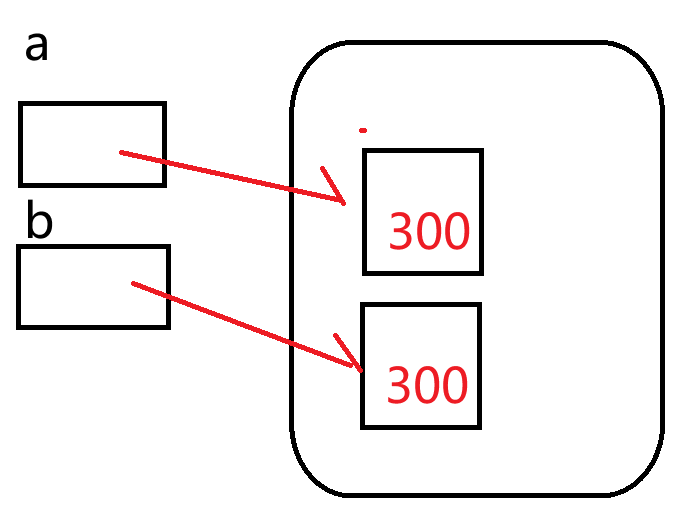
Python会为范围在[-5,256]之间的整数自动进行常量驻留。这就意味着,当你创建多个值在次范围内的话,他们实际上引用的是同一个数据对象。
上述的演示,是在控制台交互模式下的效果
在脚本模式下,有体现出了不一样的结果:
a = 1
b = 1
print(a == b)
print(a is b)
a = 300
b = 300
print(a == b)
print(a is b)
"""
True
True
True
True
"""
脚本当中,两个300是同一个数据对象,为什么呢?因为会有潜在的优化问题。
>>> id(-5)
140732088707320
>>> id(-4)
140732088707352
>>> id(-3)
140732088707384
>>> id(254)
140732088715608
>>> id(255)
140732088715640
>>> id(256)
140732088715672
>>> id(300)
1267470938224
>>> id(300)
1267470938224
>>> num = 400
>>> id(num)
1267473808912
>>> num2 = 400
>>> id(num2)
1267473808880
可以看到,自带驻留常量的地址是连续的,重新创建的再范围之外的常量,地址有可能连续也有可能不连续,但是跟常量驻留的地址连续吗?反证出300、400是新建的。
a = 300
b = 300
print(id(a))
print(id(b))
"""
3110779789776
3110779789776
"""
- 字符串驻留问题
对于字符串而言,Python也会对一些符合特定条件的字符串进行常量驻留,字符串常量只能包含字母、下划线、数字,并且在编译期间就能确定其值的字符串。
>>> s1 = "HelloWorld"
>>> s2 = "HelloWorld"
>>> s1 == s2
True
>>> s1 is s2
True
由于下面的字符串当中出现了空格,所以则不会进行常量驻留,就是两个字符串对象,只不过内容相同而已。
>>> s1 = "Hello Python"
>>> s2 = "Hello Python"
>>> s1 == s2
True
>>> s1 is s2
False
s1的值在代码编辑期间,甚至到编译的时候,它的值就已经确定了,s2的值只有程序执行的时候才能确定。虽然s1和s2最终的内容是一样的,但是s2是运行期间创建的,它是另外一个数据对象。
>>> s1 = "HelloWorld"
>>> a = "Hello"
>>> b = "World"
>>> s2 = a + b
>>> s1 == s2
True
>>> s1 is s2
False
同样,在脚本环境中,结果又有不同的表现。
3.函数在内存中的运行逻辑
函数的运行是基于栈内存的,栈就是一个先进后出的线性表
我们可以把一个函数当成是栈当中的一个元素:栈帧 -> 函数本身需要占用的内存
都包含哪些内容呢:
- 函数名-引用关系
- 参数列表
- 函数内容:函数体 return 返回值
接着来看,具体的运行机制是这样的:
(1)函数被调用时,会从堆内存中将函数的代码加载进栈内存:进栈
(2)哪个函数在栈顶,哪个函数就有限执行
(3)直到栈顶函数遇到return时,结束函数并将返回值传递给调用者:出栈
(4)在栈顶函数运行期间,如果又调用了其他函数,则当前函数暂停运行,直到成为新的栈顶则继续执行。
def pow(a, b):
c = sum(a,b) ** b
return c
def sum(a,b):
c = a + b
return c
a = 1
b = 2
ret = pow(a,b)
print(ret)
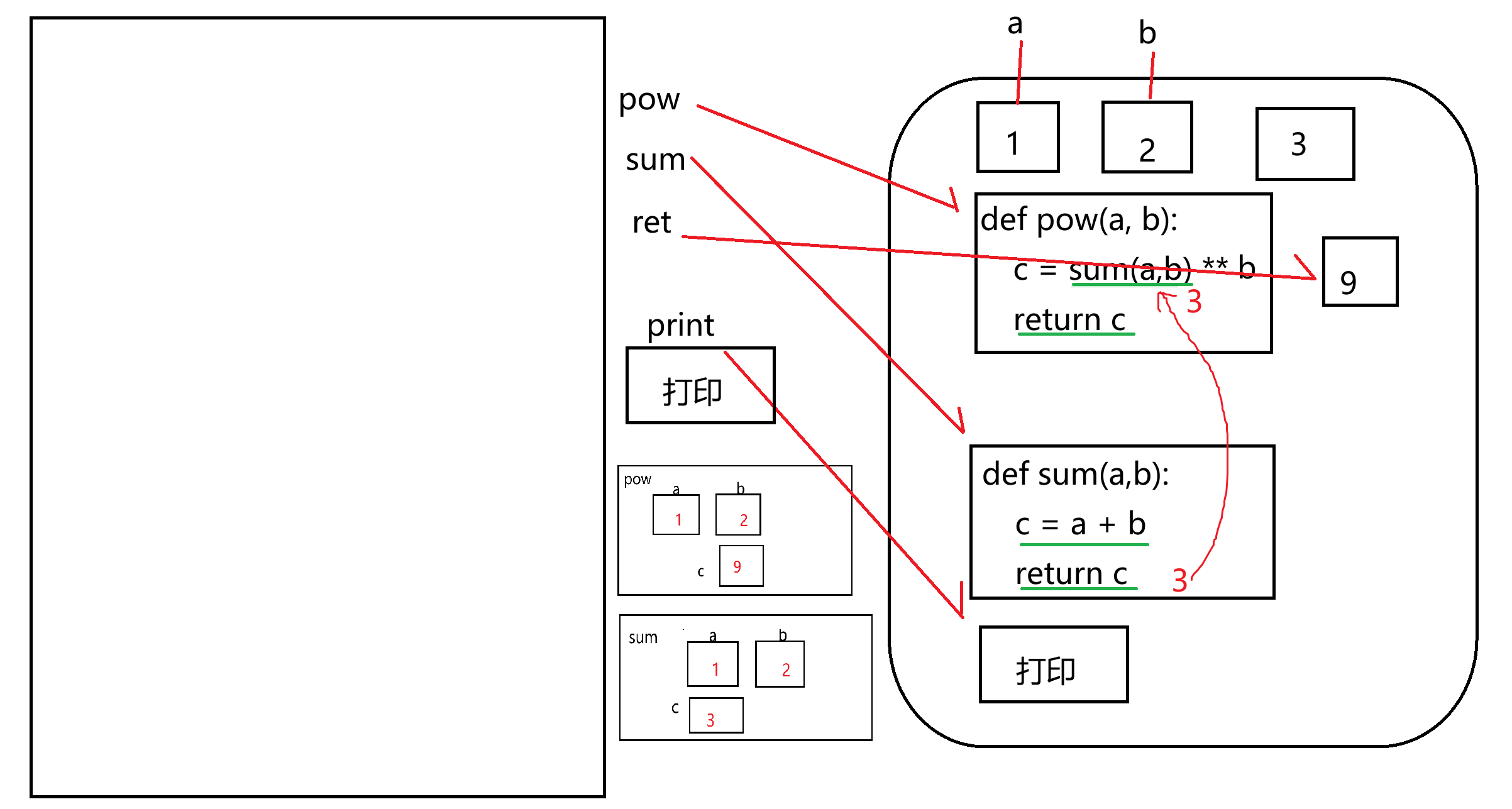
总结:
- 局部变量是随着函数的进栈而创建的,随着函数的出栈而消亡
- 全局变量是随着程序的执行而创建的,随着程序的技术而消亡
num = 10
def show():
# 函数内部寻找变量或函数的逻辑:就近原则
print(num)
show()
一般不建议在函数中直接使用全局变量,而是作为参数进行传递,为啥?一旦改变全局变量的值,那么直接调用该变量的函数在运行时就会出现有任务逻辑问题。

















 5373
5373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









