






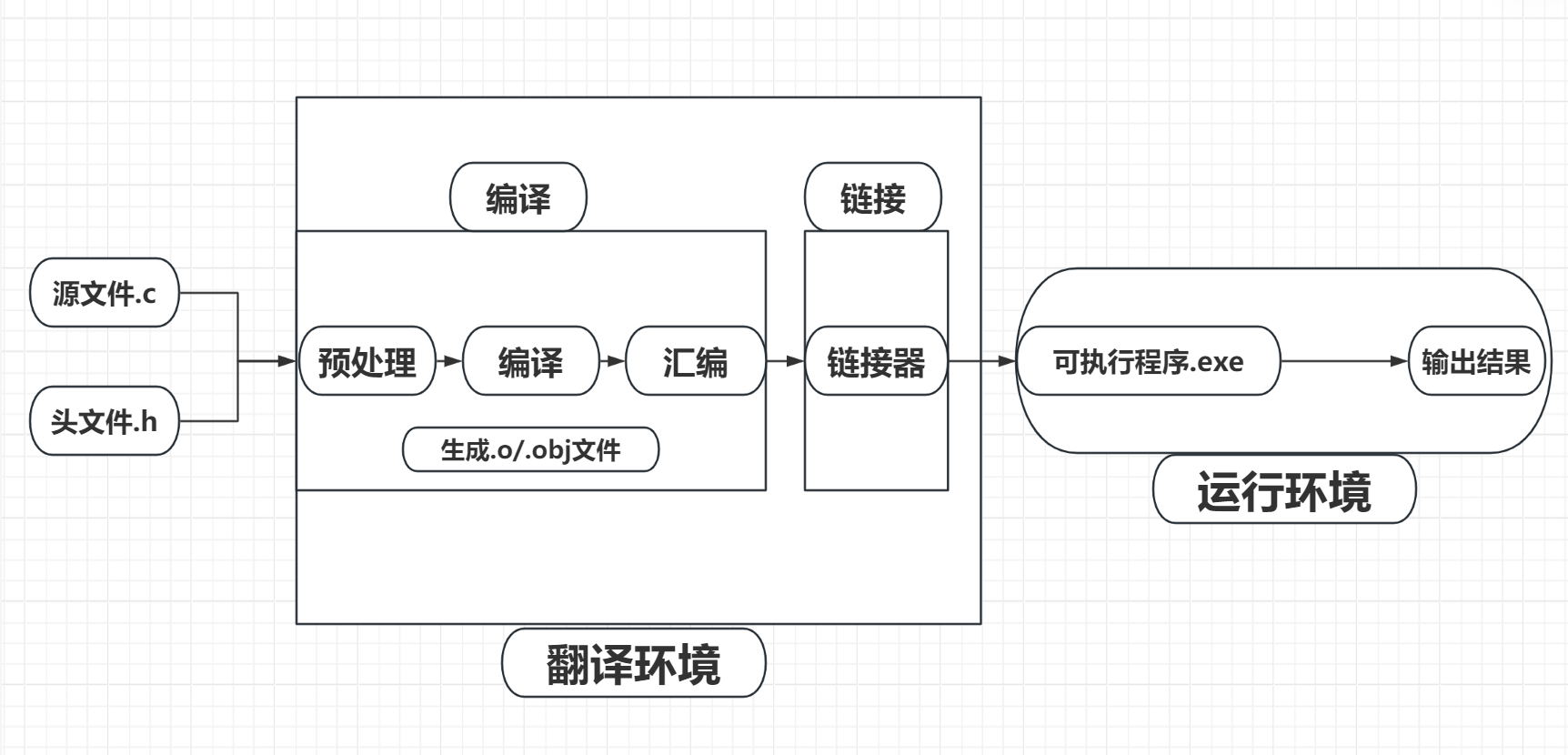
一、程序诞生的两大环境
1. 翻译环境
将源代码转换为可执行文件(.exe或ELF文件)的完整流程
# 典型翻译过程(Linux示例)
main.c → 预编译 → main.i → 编译 → main.s → 汇编 → main.o
↓
utils.c → 预编译 → utils.i → 编译 → utils.s → 汇编 → utils.o
↓
链接器 → 最终可执行文件a.out2. 运行环境
可执行程序被加载到内存中执行的生命周期
// 示例程序:理解运行时环境
#include <stdio.h>
int global_var = 10; // 全局变量 → 数据段
int main() {
int stack_var = 20; // 局部变量 → 栈区
int *heap_var = malloc(sizeof(int)); // 堆内存分配
*heap_var = 30;
free(heap_var);
return 0;
}二、翻译环境深度拆解
1. 预编译(Preprocessing)
C语言中的预处理环节是编译过程的一个重要阶段,它在正式编译代码之前由预处理器完成。预处理器会对源代码进行一些文本替换、宏展开、条件编译等操作,从而生成经过修改的中间代码(称为“预处理后的代码”)。这个环节的主要目的是简化代码开发、提高代码可维护性以及实现跨平台编程。
(1) 预处理器的作用
预处理器是一个独立于编译器的工具,它根据预处理指令对源代码进行文本级别的处理。这些指令以#开头,例如#include、#define、#ifdef等。
预处理器的作用包括以下几个方面:
- 文件包含:通过
#include指令将头文件或其他源文件的内容插入到当前文件中。 - 宏定义与替换:使用
#define定义常量或宏函数,并在代码中替换它们。 - 条件编译:通过
#if、#ifdef、#ifndef等指令控制代码的编译与否,用于实现跨平台或调试功能。 - 错误与警告:通过
#error和#warning指令生成编译时的错误或警告信息。 - 行号和文件名:通过
#line指令修改编译器记录的行号和文件名信息。
(2)常见的预处理指令
以下是一些常见的预处理指令及其用法:
1- #include
- 作用:用于包含头文件或源文件的内容。
- 语法:
#include <header_file> // 系统头文件(如标准库) #include "user_file" // 用户自定义头文件 - 示例:
#include <stdio.h> // 包含标准输入输出库 #include "my_header.h" // 包含用户自定义头文件
2- #define
- 作用:定义宏或常量。
- 语法:
#define MACRO_NAME value #define MACRO_FUNCTION(param) (expression) - 示例:
#define PI 3.14159 // 定义一个常量 #define SQUARE(x) ((x) * (x)) // 定义一个宏函数
3- 条件编译
- 作用:根据条件决定是否编译某段代码。
- 常用指令:
#if、#elif、#else、#endif#ifdef、#ifndef
- 示例:
#ifdef DEBUG printf("Debug mode is enabled.\n"); #endif #ifndef VERSION #define VERSION "1.0" #endif
4-#undef
- 作用:取消已定义的宏。
- 语法:
#undef MACRO_NAME - 示例:
#define MAX 100 #undef MAX // 取消定义MAX
5-#pragma
- 作用:提供特定于编译器的指令(非标准)。
- 示例:
#pragma once // 确保头文件只被包含一次(某些编译器支持)
6- #error 和 #warning
- 作用:生成编译时的错误或警告信息。
- 示例:
#ifndef __cplusplus #error "This code must be compiled with a C++ compiler." #endif #warning "This is a warning message."
7-#line
- 作用:修改编译器记录的行号和文件名。
- 示例:
#line 10 "custom_file.c"
(3)预处理的工作流程
预处理器会按照以下步骤对源代码进行处理:
-
删除注释:
- 预处理器会移除所有的注释(
//和/* ... */),以便后续处理。
- 预处理器会移除所有的注释(
-
处理
#include指令:- 将指定的头文件内容插入到当前文件中。例如,
#include <stdio.h>会将标准输入输出库的内容复制到当前文件中。
- 将指定的头文件内容插入到当前文件中。例如,
-
展开宏定义:
- 替换所有宏定义和宏函数。例如,
SQUARE(5)会被替换为((5) * (5))。
- 替换所有宏定义和宏函数。例如,
-
执行条件编译:
- 根据条件编译指令(如
#ifdef)决定哪些代码需要保留或删除。
- 根据条件编译指令(如
-
生成中间代码:
- 预处理器生成一个经过修改的中间文件,供编译器使用。
(4)示例:完整的预处理过程
以下是一个完整的示例,展示了预处理环节如何工作:
#include <stdio.h>
#define PI 3.14159
#define AREA(radius) (PI * (radius) * (radius))
int main() {
float r = 5.0;
#ifdef DEBUG
printf("Radius: %f\n", r);
#endif
printf("Area: %f\n", AREA(r));
return 0;
}预处理后代码(假设未定义DEBUG):
// 插入stdio.h的内容(省略具体细节)
float r = 5.0;
printf("Area: %f\n", (3.14159 * (r) * (r)));
return 0;可以看到:
#define宏被替换了。#ifdef DEBUG块被移除了,因为DEBUG未定义。
(5)注意事项
1- 宏定义的风险
- 宏展开是简单的文本替换,可能导致意外的行为。例如:
解决方法:始终使用括号包裹表达式:#define SQUARE(x) x * x int result = SQUARE(2 + 3); // 展开后为 2 + 3 * 2 + 3,结果错误#define SQUARE(x) ((x) * (x))
2- 头文件重复包含问题
- 如果多次包含同一个头文件,可能会导致重复定义错误。解决方法:
#ifndef HEADER_FILE_H #define HEADER_FILE_H // 头文件内容 #endif
3- 调试预处理结果
- 使用编译器选项查看预处理后的代码。例如:
- GCC:
gcc -E source.c -o preprocessed.i - MSVC:
cl /P source.c
- GCC:
(6)总结
预处理环节是C语言编译过程的重要组成部分,其主要功能包括:
- 文件包含(
#include)。 - 宏定义与替换(
#define)。 - 条件编译(
#ifdef、#ifndef等)。 - 其他辅助功能(如
#error、#pragma)。
通过合理使用预处理指令,可以提高代码的灵活性和可维护性,但也需要注意潜在的风险(如宏展开问题)。理解预处理环节的工作原理,有助于编写更高效、更安全的C代码。
2. 编译(Compilation)
编译阶段的主要任务是将经过预处理后的代码转换为汇编语言代码。具体来说,编译器会检查代码的语法正确性,并将其转化为一种中间表示形式,即汇编语言。将预处理后的代码转换为汇编代码(.s文件)。
(1)词法分析
将源代码分解成一系列的标记(tokens),如关键字、标识符、运算符等,源代码分解为Token流
// 源代码片段
if (x > 0) { y = x * 2; }
// Token序列示例:
[KEYWORD_IF] [LEFT_PAREN] [IDENTIFIER(x)] [OPERATOR_>] [INTEGER(0)] ...(2)语法分析
根据语言的语法规则,将这些标记组织成语法树(parse tree)或抽象语法树(AST)。
IfStmt
/ \
Condition CompoundStmt
(x > 0) |
AssignExpr
/ \
y (左值) BinaryExpr(*)
/ \
x (右值) 2(3)语义分析
-
类型检查:
int x = "hello";→ 报错 -
符号表管理:记录变量/函数的作用域和类型
-
检查程序是否符合语言的语义规则,例如变量是否声明过、类型是否匹配等
(4)优化与代码生成
生成优化的汇编代码(以x86为例):
; main.s(简化版)
section .text
global main
main:
cmp dword [x], 0
jle .L1
mov eax, dword [x]
shl eax, 1 ; 优化为移位代替乘法
mov dword [y], eax
.L1:
ret3. 汇编(Assembly)
汇编阶段的任务是将上一步生成的汇编语言代码转换为目标机器的二进制指令集,即目标文件(object file)。每个目标文件包含的是机器码,但它们还不能直接运行,因为它们可能引用了其他模块中的符号(如函数调用)。总的来说是将汇编代码转换为可重定位目标文件(.o)
- 将汇编语言翻译成机器码。
- 创建一个目标文件,其中包含了机器指令、数据以及符号表(symbol table),后者用于记录函数名和全局变量的位置信息。
# 查看符号表(Linux命令)
readelf -s main.o
Symbol table '.symtab':
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS main.c
2: 0000000000000000 35 FUNC GLOBAL DEFAULT 1 main4. 链接(Linking)
链接阶段负责将多个目标文件合并成一个完整的可执行文件。在这个过程中,链接器还会解决跨文件的符号引用问题,即将一个文件中对另一个文件定义的函数或变量的引用连接起来。
主要工作
- 重定位:调整各个目标文件中的地址,使得所有代码段和数据段能够正确地加载到内存中。
- 符号解析:查找并替换每个未定义的符号引用为其定义的实际位置。
- 库链接:如果程序使用了标准库或其他外部库,则链接器会在这些库中查找所需的函数和变量定义,并将其包含进来。
核心任务:合并多个目标文件并解析符号引用
(1)符号解析
确保所有符号(函数/变量)有唯一定义
// utils.c
void print_msg() { // 符号定义
printf("Hello");
}
// main.c
extern void print_msg(); // 符号声明(2)重定位(Relocation)
-
合并相同类型的段(如.text段合并)
-
修正符号地址:将相对地址转为绝对地址
; 链接前(main.o中的call指令)
call 0x00000000 ; 临时占位地址
; 链接后(a.out中的正确地址)
call 0x4004f6 <print_msg>(3)生成可执行文件
构建ELF文件头部,定义程序入口(_start)
三、运行环境详解
1. 内存布局(Linux x86-64)
高地址
+------------------+
| 内核空间 |
+------------------+
| 栈(向下生长) | ← %rsp
| ... |
+------------------+
| 共享库映射区 |
+------------------+
| 堆(向上生长) | ← malloc分配区域
+------------------+
| 未初始化数据段(.bss)|
+------------------+
| 已初始化数据段(.data)|
+------------------+
| 代码段(.text) | ← 程序指令
低地址2. 程序启动过程
-
加载器(Loader) 读取ELF文件头
-
分配虚拟内存空间
-
建立代码段/数据段映射
-
初始化堆栈:
-
栈指针
%rsp指向栈顶 -
%rdi保存命令行参数个数(argc) -
%rsi保存参数数组地址(argv)
-
-
跳转到入口函数
_start→ 调用main()
3. 运行时关键操作
-
栈帧管理:函数调用时压入返回地址/局部变量
; 函数调用示例
push rbp ; 保存旧栈帧基址
mov rbp, rsp ; 新栈帧基址
sub rsp, 16 ; 为局部变量分配空间
...
leave ; 相当于 mov rsp, rbp; pop rbp
ret-
堆内存管理:通过
malloc/free调用glibc的内存分配器
四、实战:观察编译全过程
# 分步编译(GCC示例)
gcc -E main.c -o main.i # 预编译
gcc -S main.i -o main.s # 生成汇编
gcc -c main.s -o main.o # 汇编
gcc main.o utils.o -o app # 链接
# 查看目标文件结构
objdump -d main.o # 反汇编
readelf -l app # 查看程序头表五、延伸思考
-
静态链接 vs 动态链接:
- 静态链接:在编译时将所有需要的库代码复制到最终的可执行文件中。优点是可以独立运行,无需依赖外部库;缺点是可执行文件较大,且每次更新都需要重新编译整个程序。
- 动态链接:仅在编译时记录对共享库的引用,在程序运行时才加载这些库。优点是可以减少可执行文件大小,允许多个程序共享同一个库实例;缺点是在没有相应库的情况下无法运行。
-
现代编译器优化技术:
-
循环展开(Loop Unrolling)
-
内联函数(Function Inlining)
-
死代码消除(Dead Code Elimination)
-
-
安全编译选项:
gcc -fstack-protector -D_FORTIFY_SOURCE=2 -Wl,-z,relro # 内存保护
通过理解编译链接的全流程,开发者能够:
-
更高效地调试链接错误(如undefined reference)
-
优化关键代码段的性能
-
深入理解程序与操作系统的交互机制
-
为学习操作系统内核打下坚实基础
推荐实验:尝试修改链接脚本(.ld文件),自定义内存布局!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









