







Task1:数据抽取
编写Scala工程代码,将MySQL的shtd_store库中表CUSTOMER、NATION、PART、PARTSUPP、REGION、SUPPLIER的数据全量抽取到Hive的ods库中对应表customer,nation,part,partsupp,region,supplier中,将表ORDERS、LINEITEM的数据增量抽取到Hive的ods库中对应表ORDERS,LINEITEM中。
表含义:
CUSTOMER : 客户
NATION :国家
REGION :区域
SUPPLIER : 供应商
ORDERS :订单
PART、PARTSUPP、LINEITEM
全量抽取
1、 抽取shtd_store库中CUSTOMER的全量数据进入Hive的ods库中表customer。字段排序、类型不变,同时添加静态分区,分区字段类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。并在hive cli执行show partitions ods.customer命令,将结果截图复制粘贴至对应报告中;
2、 抽取shtd_store库中NATION的全量数据进入Hive的ods库中表nation。字段排序、类型不变,同时添加静态分区,分区字段类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。并在hive cli执行show partitions ods.nation命令,将结果截图复制粘贴至对应报告中;
3、 抽取shtd_store库中PART的全量数据进入Hive的ods库中表part。字段排序、类型不变,同时添加静态分区,分区字段类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。并在hive cli执行show partitions ods.part命令,将结果截图复制粘贴至对应报告中;
4、 抽取shtd_store库中PARTSUPP的全量数据进入Hive的ods库中表partsupp。字段排序、类型不变,同时添加静态分区,分区字段类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。并在hive cli执行show partitions ods.partsupp命令,将结果截图复制粘贴至对应报告中;
5、 抽取shtd_store库中REGION的全量数据进入Hive的ods库中表region,字段排序、类型不变,同时添加静态分区,分区字段类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。并在hive cli执行show partitions ods.region命令,将结果截图复制粘贴至对应报告中;
6、 抽取shtd_store库中SUPPLIER的全量数据进入Hive的ods库中表supplier,字段排序、类型不变,同时添加静态分区,分区字段类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。并在hive cli执行show partitions ods.supplier命令,将结果截图复制粘贴至对应报告中;
增量抽取
7、 抽取shtd_store库中ORDERS的增量数据进入Hive的ods库中表orders,要求只取某年某月某日及之后的数据(包括某年某月某日),根据ORDERS表中ORDERKEY作为增量字段(提示:对比MySQL和Hive中的表的ORDERKEY大小),只将新增的数据抽入,字段类型不变,同时添加动态分区,分区字段类型为String,且值为ORDERDATE字段的内容(ORDERDATE的格式为yyyy-MM-dd,分区字段格式为yyyyMMdd)。并在hive cli执行select count(distinct(etldate)) from ods.orders命令,将结果截图复制粘贴至对应报告中;
8、抽取shtd_store库中LINEITEM的增量数据进入Hive的ods库中表lineitem,根据LINEITEM表中orderkey作为增量字段,只将新增的数据抽入,字段类型不变,同时添加静态分区,分区字段类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。并在hive cli执行show partitions ods.lineitem命令,将结果截图复制粘贴至对应报告中。
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
class Tools {
def createSpark(): SparkSession = {
System.setProperty("HADOOP_USER_NAME","root")
val spark = new SparkConf().setMaster("local[*]").setAppName("test")
SparkSession.builder()
.config(spark)
.config("dfs.client.use.datanode.hostname", "true")
.config("dfs.replication", "3")//
.config("set hive.exec.dynamic.partition","true")
.config("hive.exec.dynamic.partition.mode", "nonstrict")
.config("hive.exec.max.dynamic.partitions", "5000")//max 10000
.config("spark.task1.first.sql.crossJoin.enabled", "true")
.enableHiveSupport()
.getOrCreate()
}
def loadMysql(spark:SparkSession,database:String,table:String): DataFrame = {
val prop=Map(
"url"->s"jdbc:mysql://localhost:3306/$database?useSSL=false&characterEncoding=UTF-8",
"driver"->"com.mysql.jdbc.Driver",
"dbtable"->table,
"user"->"root",
"password"->"8888"
)
spark.read.format("jdbc").options(prop).load().toDF().na.drop()
}
def showTableData(spark: SparkSession, table: String): Unit = {
println("==========打印分区数据==========")
spark.sql(s"show partitions ods.$table").show()
println(s"==========打印 $table 数据==========")
spark.sql(s"select * from ods.$table").show(5)
}
}import com.ibm.icu.text.SimpleDateFormat
import org.apache.spark.sql.functions._
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK
import java.util.Calendar
object Test {
def main(args: Array[String]): Unit = {
val spark=new Tools().createSpark()
val table=Array("customer", "lineitem", "part", "partsupp", "region", "orders", "nation", "supplier")
for (i <- 0 until table.length ) {
println(s"==========准备抽取${table(i)}==========")
val df = new Tools().loadMysql(spark, "contest", table(i))
df.persist(MEMORY)
df.cache()
table(i) match {
case "lineitem"=>println(s"=========${table(i)}增量抽取(静态)=========");increment(spark,df,table(i))
case "orders"=>println(s"=========${table(i)}增量抽取(动态)=========");increment(spark,df,table(i))
case _=>println(s"===========${table(i)}全量抽取===========");full(df,table(i))
}
new Tools().showTableData(spark,table(i))
}
spark.stop()
}
def increment(spark:SparkSession,dataFrame: DataFrame,table:String): Unit = {
println("===========获取增量字段==========")
var icrclm: Any = spark.table(s"ods.$table")
.select(max("orderkey"))
.collect()(0).get(0)
println(icrclm)
icrclm match {
case null=>
icrclm=0
println(s"==========增量字段:$icrclm==========")
case _=>
println(s"==========增量字段:$icrclm==========")
}
println(s"final value:$icrclm")
table match {
case "lineitem"=>
println("==========增量抽取静态分区开始==========")
val simple=new SimpleDateFormat("yyyyMMdd")
val calendar=Calendar.getInstance()
calendar.add(Calendar.DATE,-1)
val nowdate=simple.format(calendar.getTime)
println(s"==========当前时间:$nowdate==========")
dataFrame.where(s"orderkey>=$icrclm")
.withColumn("etldata",lit(nowdate))
.write
.format("Hive")
.mode("append")
.partitionBy("etldata")
.saveAsTable(s"ods.$table")
case _=>
println("==========增量抽取动态分区开始==========")
val df1=dataFrame.where(s"orderkey>$icrclm")
println("==========添加分区字段==========")
val df2=df1.withColumn("etldata",
date_format(
col("orderdate") ,"yyyyMMdd"
)
)
println("==========分区字段添加完成==========")
df2.write
.format("Hive")
.mode("append")
.partitionBy("etldata")
.saveAsTable(s"ods.$table")
println("==========orders数据抽取完成==========")
}
}
def full(dataFrame: DataFrame,table:String): Unit = {
val simple=new SimpleDateFormat("yyyyMMdd")
val calendar=Calendar.getInstance()
calendar.add(Calendar.DATE,-1)
val nowdate=simple.format(calendar.getTime)
println(s"==========当前时间:$nowdate==========")
dataFrame
.withColumn("etldata",lit(nowdate))
.write.mode("overwrite")
.partitionBy("etldata")
.saveAsTable(s"ods.$table")
}
}Task2:数据清洗
编写Scala工程代码,将ods库中相应表数据全量抽取到Hive的dwd库中对应表中。表中有涉及到timestamp类型的,均要求按照yyyy-MM-dd HH:mm:ss,不记录毫秒数,若原数据中只有年月日,则在时分秒的位置添加00:00:00,添加之后使其符合yyyy-MM-dd HH:mm:ss。
1、 将ods库中customer表数据抽取到dwd库中dim_customer的分区表,分区字段为etldate且值与ods库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”,dwd_insert_time、dwd_modify_time均填写操作时间,并进行数据类型转换。在hive cli中按照cust_key顺序排序,查询dim_customer前1条数据,将结果内容复制粘贴至对应报告中;
2、 将ods库中part表数据抽取到dwd库中dim_part的分区表,分区字段为etldate且值与ods库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”,dwd_insert_time、dwd_modify_time均填写操作时间,并进行数据类型转换。在hive cli中按照part_key顺序排序,查询dim_part前1条数据,将结果内容复制粘贴至对应报告中;
3、 将ods库中nation表数据抽取到dwd库中dim_nation的分区表,分区字段为etldate且值与ods库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”,dwd_insert_time、dwd_modify_time均填写操作时间,并进行数据类型转换。在hive cli中按照nation_key顺序排序,查询dim_nation前1条数据,将结果内容复制粘贴至对应报告中;
4、 将ods库中region表数据抽取到dwd库中dim_region的分区表,分区字段为etldate且值与ods库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中 dwd_insert_user、dwd_modify_user均填写“user1”,dwd_insert_time、dwd_modify_time均填写操作时间,并进行数据类型转换。在hive cli中按照region_key顺序排序,查询dim_region表前1条数据,将结果内容复制粘贴至对应报告中;
5、 将ods库中orders表数据抽取到dwd库中fact_orders的分区表,分区字段为etldate且值与ods库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”,dwd_insert_time、dwd_modify_time均填写操作时间,并进行数据类型转换。在执行hive cli执行select count(distinct(etldate)) from dwd.fact_orders命令,将结果内容复制粘贴至对应报告中;
6、 待任务5完成以后,需删除ods.orders中的分区,仅保留最近的三个分区。并在hive cli执行show partitions ods.orders命令,将结果截图粘贴至对应报告中;
7、将ods库中lineitem表数据抽取到dwd库中fact_lineitem的分区表,分区字段为etldate且值与ods库的相对应表该值相等,抽取的条件为根据orderkey和partkey进行去重,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”,dwd_insert_time、dwd_modify_time均填写操作时间,并进行数据类型转换。在hive cli执行show partitions dwd.fact_lineitem命令,将结果截图粘贴至对应报告中。
import org.apache.spark.SparkConf
import org.apache.spark.sql.functions.{col, lit}
import org.apache.spark.sql.{DataFrame, SparkSession}
import java.text.SimpleDateFormat
import java.util.Calendar
class Tools {
def createSpark(): SparkSession = {
System.setProperty("HADOOP_USER_NAME", "root")
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("task2")
SparkSession.builder()
.config(sparkConf)
.config("dfs.client.use.datanode.hostname", "true")
.config("dfs.replication", "3")
.enableHiveSupport()
.getOrCreate()
}
def loadHive(spark:SparkSession,table:String): DataFrame= {
val df=spark.table(s"ods.$table")
val cts=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
val calendar=Calendar.getInstance()
val ft=cts.format(calendar.getTime)
val ff = df.withColumn("etldata", col("etldata"))
.withColumn("dwd_insert_user", lit("user1"))
.withColumn("dwd_insert_time", lit(ft))
.withColumn("dwd_modify_user", lit("user1"))
.withColumn("dwd_modify_time", lit(ft))
if (table=="lineitem"){
println("这里是item,即将进行去重操作")
ff.dropDuplicates(Seq("orderkey", "partkey"))
}
else {
ff
}
}
}import org.apache.spark.sql.functions.{col, from_unixtime, unix_timestamp}
object Test {
def main(args:Array[String]): Unit = {
val spark=new Tools().createSpark()
val table1=Array("customer","part","nation","region","orders")
val table2=Array("dim_customer","dim_part","dim_nation","dim_region","fact_orders")
var i=0
table1.foreach(table=>{
println(s"${"="*10}抽取表数据${"="*10}")
val df=new Tools().loadHive(spark,table)
df.schema.fields.foreach(scm=>
{
val cn=scm.name
.toLowerCase
cn match {
case "etldata" =>val fn=df.withColumn(cn,
from_unixtime(
unix_timestamp(col(cn),"yyyyMMdd"),
"yyyy-MM-dd HH:mm:ss"
)
)
println(s"更改字段格式,当前表:$table")
fn.write.mode("overwrite").partitionBy("etldata").saveAsTable(s"dwd.${table2(i)}")
case "orderdate"|"commentdate"|"receiptdate"=> val fn = df.withColumn(cn,
from_unixtime(
unix_timestamp(col(cn), "yyyy-MM-dd"),
"yyyy-MM-dd HH:mm:ss"
)
)
fn.write.mode("overwrite").partitionBy("etldata").saveAsTable(s"dwd.${table2(i)}")
case _=>println()
}
}
)
i=i+1
}
)
spark.stop()
}
def rmPartition(spark: SparkSession): Unit = {
val partitions=spark.table("ods.orders")
.select("etldata")
.distinct()
.orderBy(desc("etldata"))
val p=partitions.limit(3)
.collect()
.map(_.getString(0))
.toSeq
partitions.filter(
!col("etldata").isin(p:_*)
)
.collect()
.foreach(row =>
spark.sql(s"ALTER TABLE ods.orders DROP IF EXISTS PARTITION (etldata='${row.getString(0)}')")
)
}
}Task3:指标计算
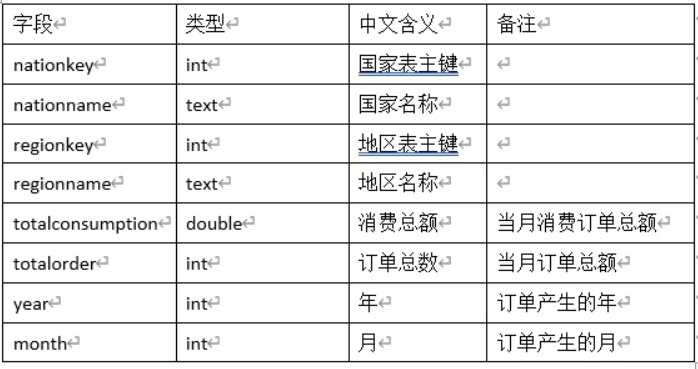
1、 编写Scala工程代码,根据dwd层表统计每个地区、每个国家、每个月下单的数量和下单的总金额,存入MySQL数据库shtd_store的nationeverymonth表(表结构如下)中,然后在Linux的MySQL命令行中根据订单总数、消费总额、国家表主键三列均逆序排序的方式,查询出前5条,将SQL语句与执行结果截图粘贴至对应报告中;
1、totalprice记录了每个用户的消费金额,因此每个月下单数量(totalorder)即当月该用户出现的消费金额次数,下单总金额(totalconsumption)为当月该用户出现的消费金额总和;
2、时间相关字段由orders表中orderdate字段抽取转换。
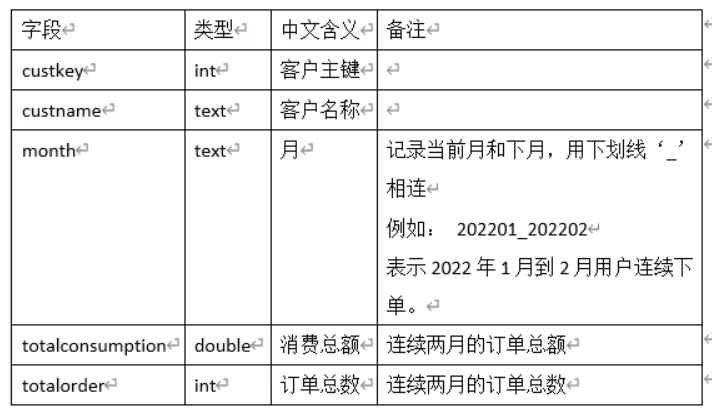
2、 编写Scala工程代码,根据dwd层表统计连续两个月下单并且下单金额保持增长的用户,订单发生时间限制为大于等于某年,存入MySQL数据库shtd_store的usercontinueorder表(表结构如下)中。然后在Linux的MySQL命令行中根据订单总数、消费总额、客户主键三列均逆序排序的方式,查询出前5条,将SQL语句与执行结果截图粘贴至对应报告中。
1、连续月份下单需要获取时间相关字段偏移量,以月向后偏移1,比较两个月如果相邻,即偏移量减去偏移前数据=1或89,因为相邻跨年1月-12月=89,如199501-199412=89;
2、判定金额是否增长需要获取金额相关字段偏移量,以月向后偏移1,比较偏移量减去偏移前数据是否大于0;
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
class Tools {
def createSpark(): SparkSession = {
System.setProperty("HADOOP_USER_NAME","root")
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("task3")
SparkSession.builder()
.config(sparkConf)
.config("hive.exec.dynamic.partition", "true")
.config("hive.exec.dynamic.partition.mode", "nonstrict")
.config("hive.exec.max.dynamic.partitions","3000")
.config("dfs.replication","3")
.config("dfs.client.use.datanode.hostname","true")
.enableHiveSupport()
.getOrCreate()
}
def saveMysql(dataFrame: DataFrame, table:String): Unit = {
val mysqlProp=Map(
"url"->"jdbc:mysql://localhost:3306/shtd_store?useSSL=false&characterEncoding=UTF-8",
"driver"->"com.mysql.jdbc.Driver",
"user"->"root",
"password"->"8888",
"dbtable"->table
)
dataFrame.write
.format("jdbc")
.options(mysqlProp)
.mode("overwrite")
.save()
}
}import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
object Test {
def main(args:Array[String]): Unit = {
val spark=new Tools().createSpark()
println(s"${"="*10}开始抽取数据${"="*10}")
val dfCust=spark.table("dwd.dim_customer").cache()
val dfNation=spark.table("dwd.dim_nation").cache()
val dfRegion=spark.table("dwd.dim_region").cache()
val dfOrder=spark.table("dwd.fact_orders").cache()
println(s"${"="*10}数据抽取完成${"="*10}")
println(s"${"="*10}开始执行任务一${"="*10}")
val firsttask=dfOrder.join(dfCust,"custkey")
.join(dfNation,"nationkey")
.join(dfRegion,"regionkey")
.groupBy(
col("nationkey"),
col("dim_nation.name").as("nationname"),
col("regionkey"),
col("dim_region.name").as("regionname"),
date_format(col("fact_orders.orderdate"),"yyyy").as("year"),
date_format(col("fact_orders.orderdate"),"MM").as("month")
)
.agg(
sum("totalprice").as("totalconsumption"),
count("totalprice").as("totalorder")
)
.orderBy(desc("totalorder"),desc("totalconsumption"),desc("nationkey"))
.select(
col("nationkey"),
col("nationname"),
col("regionkey"),
col("regionname"),
round(col("totalconsumption"), 2).as("totalconsumption"),
col("totalorder"),
col("year"),
col("month")
)
println(s"${"="*10}任务一最终结果${"="*10}")
firsttask.show()
println(s"${"="*10}正在将数据存入MySQL${"="*10}")
new Tools().saveMysql(firsttask,"nationeverymonth")
println(s"${"="*10}任务一完成${"="*10}")
println(s"${"="*10}开始执行任务二${"="*10}")
val secondtask=dfOrder
.select(
col("custkey"),
date_format(col("orderdate"),"yyyyMM").as("orderdate"),
col("totalprice")
)
.groupBy(col("custkey"),col("orderdate"))
.agg(
sum(col("totalprice")).as("sumprice"),
count(col("totalprice")).as("cntprice")
)
.select(
dfOrder("custkey"),
col("orderdate"),
col("sumprice"),
col("cntprice"),
lead(col("orderdate"),1)
.over(Window.partitionBy(col("custkey")).orderBy(col("orderdate")))
.as("next_month"),
lead(col("sumprice"),1)
.over(Window.partitionBy("custkey").orderBy("orderdate"))
.as("next_sumprice"),
lead(col("cntprice"),1)
.over(Window.partitionBy("custkey").orderBy("orderdate"))
.as("next_cntprice")
)
.join(
dfCust,
dfOrder("custkey")===dfCust("custkey")
&& ((col("next_month")-col("orderdate"))===1
|| (col("next_month")-col("orderdate"))===89)
&& col("next_sumprice")>col("sumprice")
)
.select(
dfOrder("custkey"),
dfCust("name").as("custname"),
concat_ws("_",col("orderdate"),col("next_month")).as("month"),
round(col("sumprice")+col("next_sumprice"),2).as("totalconsumption"),
(col("cntprice")+col("next_cntprice")).as("totalorder")
)
println(s"${"="*10}任务二最终结果${"="*10}")
secondtask.show()
println(s"${"="*10}正在将数据存入MySQL${"="*10}")
new Tools().saveMysql(secondtask,"usercontinueorder")
println(s"${"="*10}任务二完成${"="*10}")
spark.stop()
}
}


















 488
488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









