







K-means聚类算法——鸢尾花识别
这次的代码还有一定的问题要优化,预测的准确率有待提高,我们实验最好结果是98的测试集准确率。正常只有30左右。
一、选题分析
鸢尾花识别项目基于经典的K-means聚类算法,旨在通过特征值输入来预测鸢尾花的种类。选题的具体分析如下:
背景
鸢尾花数据集是一个经典的数据集,广泛应用于分类和聚类算法的教学和研究中。该数据集包含三类鸢尾花:Setosa、Versicolor和Virginica,每类各50个样本,每个样本有4个特征:花萼长、花萼宽、花瓣长和花瓣宽。
目标
- 使用K-means聚类算法对鸢尾花数据进行聚类:通过无监督学习的方式,将鸢尾花数据分成四类(也就是分为所谓的4簇)。
- 预测鸢尾花种类:用户输入鸢尾花的特征值后,系统能够预测其所属的种类。
- 展示预测的迭代过程:通过显示迭代过程中的质心变化,让我们可以更直观地理解K-means聚类算法的工作原理。
- 增加非鸢尾花数据:模拟实际环境中的数据混合情况,提高算法的鲁棒性(鲁棒性是指算法在面对噪声、数据缺失或异常数据等情况下仍然能保持其性能的能力。在鸢尾花识别项目中,确保K-means聚类算法的鲁棒性是非常重要的)而本项目正是通过添加非鸢尾花集,更好的模拟了实际情况。
需求
- 数据处理:包括数据加载、特征缩放和数据集划分。
- 算法实现:K-means聚类算法的实现,包括质心初始化、簇分配、质心更新和收敛判断。
- 结果展示:输入特征值进行预测,并显示预测结果及其迭代过程。
挑战
- 质心初始化的随机性:不同的初始化可能导致不同的聚类结果。
- 收敛判断:判断质心是否已经收敛需要设定合适的阈值。
- 处理混合数据:需要正确区分鸢尾花和非鸢尾花数据。
二、知识补充
1.k-means算法
K-means算法是一种常用的无监督学习方法,用于将数据点划分为K个簇,每个簇由其质心(centroid)表示。算法通过迭代的方式,最小化各点到其所属质心的距离,从而实现数据点的聚类。
K-means算法步骤
- 初始化:
- 随机选择K个点作为初始质心。
- 迭代步骤:
- 簇分配:将每个数据点分配到离它最近的质心所属的簇。
- 质心更新:重新计算每个簇的质心,质心为簇内所有点的平均值。
- 收敛条件:
- 质心不再发生变化,或者达到最大迭代次数。
补充:
- 一般情况下k-means算法是不确定有几个簇的,一般要运用“肘部法则”来判断几个簇,此题恰好已经分类好就不需要运用肘部法则来确定簇的数量。
三、整体设计思路
#include <iostream>
#include <fstream>
#include <vector>
#include <array>
#include <cmath>
#include <limits>
#include <algorithm>
#include <numeric>
#include <cstdlib>
#include <ctime>
#include <opencv2/opencv.hpp>
1.头文件的添加
<cstdlib>- 提供了标准库中的通用工具函数,包括动态内存分配、随机数生成、进程控制、环境查询和转换等功能。
<ctime>:- 用于随机数生成和时间相关的操作,例如在运用**
<cstdlib>** 初始化随机数种子srand(static_cast<unsigned int>(time(0)))和生成随机数rand()。
- 用于随机数生成和时间相关的操作,例如在运用**
<limits>:- 用于获取数据类型的极限值,例如
numeric_limits<double>::max()和numeric_limits<double>::min(),在代码中用于特征缩放和初始化距离数组。
- 用于获取数据类型的极限值,例如
<numeric>:- 用于数值算法操作,例如
accumulate用于计算总距离accumulate(distances.begin(), distances.end(), 0.0)。
- 用于数值算法操作,例如
2.对数据集部分内容的相关处理——标签
struct Iris {
array<double, 4> features;
int label; // 0: Setosa, 1: Versicolour, 2: Virginica, 3: 非鸢尾花
};
// 将字符串标签映射为整数
int labelToInt(const string& label) {
if (label == "setosa") return 0;
if (label == "versicolor") return 1;
if (label == "virginica") return 2;
return 3;
}
// 将整数标签映射为字符串
string labelToString(int label) {
if (label == 0) return "setosa";
if (label == 1) return "versicolor";
if (label == 2) return "virginica";
return "non-iris";
}
-
创建一个鸢尾花结构体
-
features:一个长度为 4 的array<double, 4>数组,用于存储鸢尾花的四个特征值(如花萼长、花萼宽、花瓣长、花瓣宽)。double是数据类型,4是数组大小。-
与原生数组相比,
array提供了更好的类型安全性和丰富的成员函数接口,使其使用更加方便和安全。 -
array与一般数组的区别
特性 传统数组 array初始化方式 支持 支持 获取大小 需手动计算 提供 size()方法边界检查 不支持 支持(通过 at()方法)迭代 使用循环 支持迭代器和范围 for循环类型安全 不完全 完全类型安全 与 STL 结合 不直接支持 完全支持 -
运用
array很好的避免了访问越界的现象。
-
-
label:一个int类型的标签,用于表示鸢尾花的种类。标签的含义如下:- 0:Setosa
- 1:Versicolour
- 2:Virginica
- 3:非鸢尾花
-
-
函数
labelToInt和函数labelToString-
将表示鸢尾花种类的字符串标签和整数标签进行转化
-
作用:
-
数据加载:从文件中加载鸢尾花数据时,字符串标签需要转换为整数标签以便于后续处理。
-
数据存储:处理后的数据需要保存到文件中时,需要将整数标签转换回字符串标签。
-
分类和预测:在分类和预测过程中,标签的表示形式需要在整数和字符串之间转换,以便于显示和分析结果。
-
-
这样提高了代码的可读性和维护性。
-
3.加载鸢尾花数据集
vector<Iris> loadIrisData(const string& filename) {
vector<Iris> data;
ifstream file(filename);
if (!file.is_open()) {
cerr << "无法打开文件" << endl;
return data;
}
string line;
while (getline(file, line)) {
istringstream iss(line);//创建了一个流对象
Iris iris;
string label;
if (iss >> iris.features[0] >> iris.features[1] >> iris.features[2] >> iris.features[3] >> label) {
iris.label = labelToInt(label);
data.push_back(iris);
}
}
file.close();
return data;
}
- 初始化
vector<Iris>:声明一个vector<Iris>变量data,用于存储从文件中读取的数据。 - 打开文件:使用
ifstream打开指定的文件。如果文件打开失败,输出错误信息并返回空的vector - 读取文件内容:使用
getline逐行读取文件内容。- 解析每一行:将每一行数据读入一个
istringstream对象iss。- 方便解析:
istringstream使得解析字符串变得非常简单,可以直接使用流提取运算符>>逐个提取数据项,而不需要手动拆分字符串。 - 一致的接口:使用
istringstream可以与从标准输入(如cin)读取数据的方式一致,简化了代码。 - 安全性:流操作符
>>会自动处理不同类型的数据,并在数据类型不匹配时返回错误状态,使得解析过程更加安全。
- 方便解析:
- 读取特征值和标签:从
iss中提取四个特征值和一个标签字符串,并将特征值存储到Iris结构体的features数组中。 - 转换标签:使用
labelToInt函数将标签字符串转换为整数标签,并存储到Iris结构体的label字段中。 - 添加到数据集:将解析后的
Iris结构体对象添加到data向量中。
- 解析每一行:将每一行数据读入一个
- 关闭文件:读取完所有行后,关闭文件。
- 返回数据集:返回包含所有读取和解析后的
Iris数据的vector。
4.生成非鸢尾花数据
vector<Iris> generateNonIrisData(int numSamples) {
vector<Iris> data;
srand(static_cast<unsigned int>(time(0)));
for (int i = 0; i < numSamples; ++i) {
Iris nonIris;
for (int j = 0; j < 4; ++j) {
nonIris.features[j] = (rand() % 11)/10.0 ;
}
nonIris.label = 3; // 非鸢尾花
data.push_back(nonIris);
}
return data;
}
-
函数返回值以及参数
-
该函数返回一个
std::vector<Iris>容器,包含生成的非鸢尾花数据。 -
numSamples参数指定要生成的样本数量。
-
-
设置随机数种子
- 使用当前时间设置随机数种子,确保每次运行程序时生成不同的随机数。
-
生成非鸢尾花数据
- 对于每一个样本:
- 创建一个
Iris对象nonIris。 - 使用内层的
for循环生成四个随机特征值,每个特征值在 0 到 1 之间。 - 将标签设置为
3,表示非鸢尾花。 - 将生成的
nonIris对象添加到data容器中。
- 创建一个
- 对于每一个样本:
-
增加非鸢尾花集更好的模拟实际情况,增加数据的多样性和复杂性。
5.将数据写入文件
void writeDataToFile(const vector<Iris>& data, const string& filename) {
ofstream file(filename);
if (!file.is_open()) {
cerr << "无法打开文件" << endl;
return;
}
for (const auto& iris : data) {
file << iris.features[0] << " " << iris.features[1] << " " << iris.features[2] << " " << iris.features[3] << " " << labelToString(iris.label) << endl;
}
file.close();
}
for (const auto& iris : data)运用这种方式- 使用
auto关键字可以让编译器自动推导出iris的类型。不需要显式地指定类型,减少了代码的冗长和可能的错误。 - 使用
const auto&可以避免不必要的拷贝操作,提高性能,并且通过引用来访问元素,这样修改iris的值不会影响原来的数据。另外,const确保了在循环体内不会修改容器中的元素。
- 使用
6.进行特征缩放
void scaleFeatures(vector<Iris>& data, array<double, 4>& minVal, array<double, 4>& maxVal) {
// 找到每个特征的最小值和最大值
for (const auto& iris : data) {
for (int i = 0; i < 4; ++i) {
if (iris.features[i] < minVal[i]) minVal[i] = iris.features[i];
if (iris.features[i] > maxVal[i]) maxVal[i] = iris.features[i];
}
}
// 进行特征缩放
for (auto& iris : data) {
for (int i = 0; i < 4; ++i) {
iris.features[i] = (iris.features[i] - minVal[i]) / (maxVal[i] - minVal[i]);
}
}
}
-
目的:通过特征缩放,可以使不同特征值在相同的范围内,有助于提高机器学习算法的性能和准确性。
-
缩放后的特征值 = (特征值 − 最小值) / (最大值 − 最小值) 缩放后的特征值=(特征值−最小值)/(最大值−最小值) 缩放后的特征值=(特征值−最小值)/(最大值−最小值)
这是特征缩放公式。
-
步骤:
- 找到每个特征的最小值和最大值
- 遍历数据集中的每个
Iris对象。 - 对于每个特征(共有四个),找到当前特征的最小值和最大值,并更新
minVal和maxVal数组。
- 遍历数据集中的每个
- 进行特征缩放
- 找到每个特征的最小值和最大值
-
优点:
- 消除特征值的量纲差异:特征缩放使得所有特征值在同一个量纲范围内,有助于提高机器学习算法(如 K-means)的性能和准确性。
- 增强数值稳定性:通过归一化,可以减少数值计算中的溢出和下溢问题,提高数值稳定性。
7.k-means类
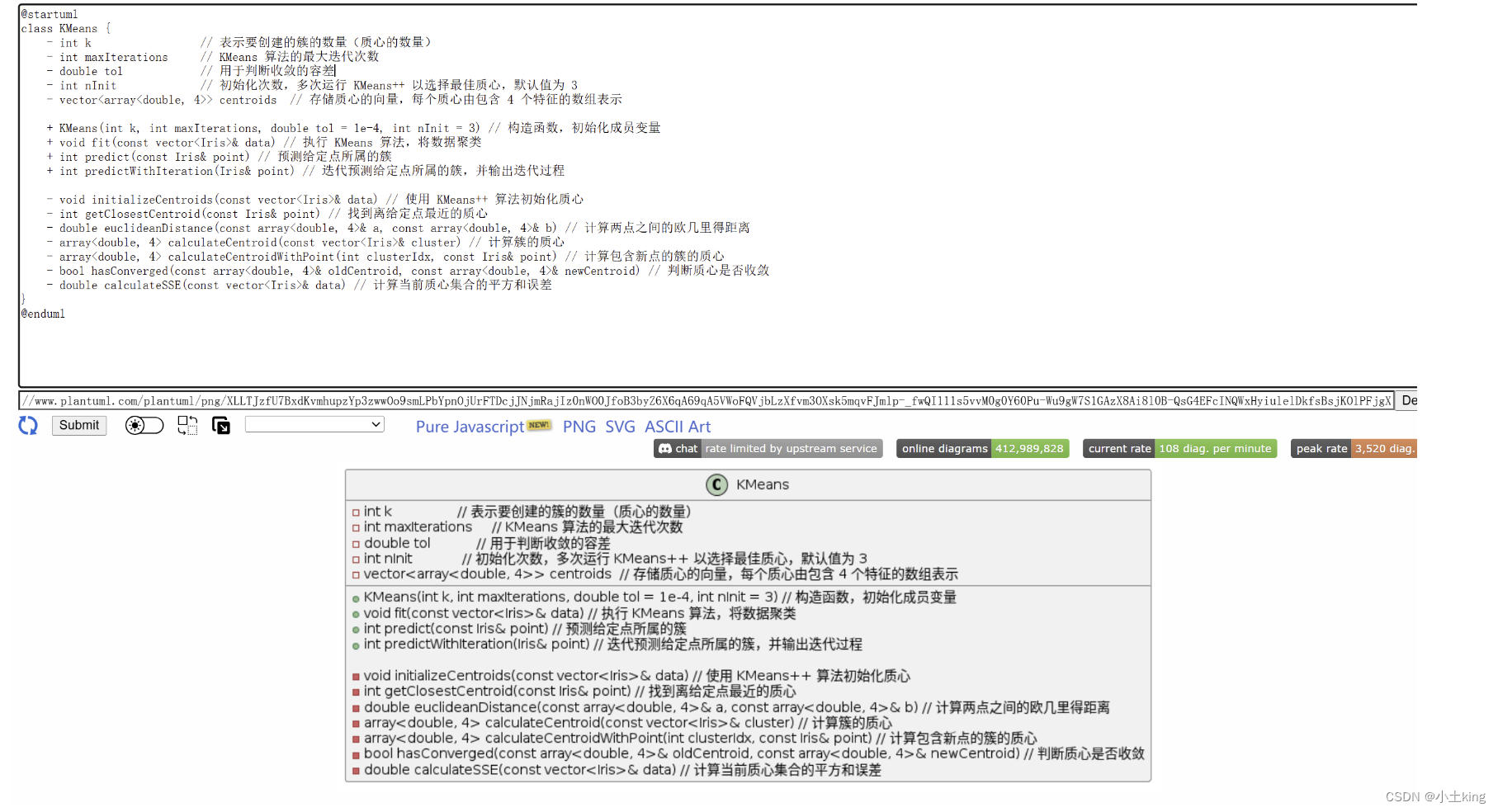
+(public)、-(private)用于修饰- 这是用plantUML绘制的用例图
1.构造函数
KMeans(int k, int maxIterations, double tol = 1e-4, int nInit = 3) : k(k), maxIterations(maxIterations), tol(tol), nInit(nInit) {
}
-
初始化成员变量
-
k:聚类的数量(簇的数量)。 -
maxIterations:KMeans 算法的最大迭代次数。 -
tol:用于判断收敛的容差,默认为1e-4。 -
nInit:初始化次数,即多次运行 KMeans++ 算法以选择最佳质心,默认为3。
-
2.euclideanDistance函数——计算欧氏距离
double euclideanDistance(const array<double, 4>& a, const array<double, 4>& b) {
double sum = 0.0;
for (int i = 0; i < 4; ++i) {
sum += pow(a[i] - b[i], 2);
}
return sqrt(sum);
}
-
欧氏距离的数学公式
-
欧氏距离(Euclidean Distance)是两个向量之间最常用的距离度量方法,其公式如下:

-
使用一个
for循环遍历向量的每个维度。对于每个维度
i,计算a[i]和b[i]的差的平方,并将其累加到sum中。使用
pow计算平方。
-
3.initializeCentroids函数——初始化质心
void initializeCentroids(const vector<Iris>& data) {
centroids.push_back(data[rand() % data.size()].features);
for (int i = 1; i < k; ++i) {
vector<double> distances(data.size(), numeric_limits<double>::max());
for (size_t j = 0; j < data.size(); ++j) {
for (int m = 0; m < i; ++m) {
double dist = euclideanDistance(data[j].features, centroids[m]);
if (dist < distances[j]) {
distances[j] = dist;
}
}
}
double totalDistance = accumulate(distances.begin(), distances. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









