



在分布式系统中,消息队列是解耦服务、削峰填谷的核心组件。Redis自5.0版本引入的Stream结构,凭借其原生的消息队列特性,成为中小型分布式系统的优选方案。而消费组(Consumer Group)作为Stream的灵魂功能,更是实现多消费者协同、负载均衡和消息可靠处理的关键。本文将从消费组的行为模式入手,用通俗易懂的语言拆解其核心机制,最终通过完整的Go语言代码实现一个生产级的消费组案例。
一、先搞懂:什么是Redis Stream消费组?
在讲消费组之前,我们先回顾下Redis Stream的基础特性。Stream本质是一个有序的消息日志,就像我们日常生活中的快递仓库——生产者不断往仓库里放快递(发送消息),消费者从仓库里取快递(处理消息)。但如果只有一个仓库和多个消费者,很容易出现“多个消费者抢同一个快递”(重复消费)或者“某个消费者累死、其他消费者闲死”(负载不均)的问题。
消费组就是为解决这些问题而生的“快递分拣系统”:它给每个消费者分配专属的分拣区域,确保每个快递只被一个消费者处理;同时实时监控各消费者的处理进度,一旦有消费者“罢工”(崩溃),未处理的快递会重新分配给其他消费者。简单来说,消费组是协调多个消费者共同消费一个Stream的管理机制。
核心结论:没有消费组的Stream,最多算“简易消息队列”;有了消费组,才能实现真正的分布式协同消费。
二、关键行为模式:消费组的3大核心机制
消费组的核心价值体现在其独特的行为模式上,这些模式确保了消息消费的可靠性、均衡性和可追溯性。我们用“快递分拣”的类比,逐一拆解这3大机制。
1. 消息分配:谁来处理?负载均衡的秘密
消费组的第一个核心能力是“智能分配消息”,确保每个消息只被一个消费者处理,且各消费者的任务量尽量均衡。其分配规则可以概括为“未分配消息均分,挂起消息重试”。
具体流程如下:
-
新消息分配:当生产者向Stream发送新消息时,这些消息会被标记为“未分配”。消费组会按照“轮询”的方式,将未分配消息均匀分配给组内的消费者。比如组内有ConsumerA和ConsumerB,新消息1分配给A,消息2分配给B,消息3再分配给A,以此类推。
-
挂起消息处理:如果消费者领取消息后,没有及时“确认处理完成”(比如进程崩溃、网络中断),这条消息会被标记为“挂起消息”(Pending Message)。消费组会定期检测挂起消息,当消息挂起时间超过阈值,或者通过主动查询,这些消息会重新分配给组内其他消费者处理。
这里有个关键细节:消费者领取消息时,需要通过特殊的标识符“>”告诉消费组“我要新的未分配消息”。如果要处理挂起消息,则需要指定具体的消息ID,避免和其他消费者重复领取。
为什么不用“抢占式”分配?因为抢占式会导致多个消费者同时请求同一条消息,增加Redis的压力;而消费组的预分配机制,通过“标记已分配”的方式,从根源上避免了重复竞争。
2. 消息确认:处理完了吗?可靠性的保障
如果消费者领取消息后突然崩溃,消息就会“石沉大海”——既没被处理,也没被重新分配。消费组的“消息确认机制”(ACK)就是解决这个问题的“安全网”。
这个机制的核心逻辑是“领取不删除,确认才清除”:
-
领取消息:消费者从消费组领取消息后,消息并不会从Stream中删除,只是会被标记为“已分配给某个消费者”,并加入该消费者的“挂起列表”(Pending List)。
-
处理消息:消费者执行业务逻辑(比如将消息写入数据库、调用API等)。
-
确认消息:处理完成后,消费者必须向消费组发送“确认指令”(XACK)。消费组收到确认后,会将消息从“挂起列表”中移除,完成整个消费流程。
-
未确认处理:如果消费者在处理过程中崩溃,消息会一直留在“挂起列表”中。通过
XPENDING命令可以查询挂起消息,再通过重新分配机制让其他消费者处理。
举个实际例子:如果我们用Stream处理订单支付消息,消费者领取消息后开始调用支付接口,此时突然断电。由于没有发送确认指令,这条消息会留在挂起列表中,重启后其他消费者会重新处理,避免订单“支付中”状态一直卡住。
3. 消费进度:从哪开始?可追溯的关键
消费组的第三个核心能力是“记录消费进度”,确保消费者重启后,能从上次中断的地方继续消费,而不是重复消费历史消息或遗漏新消息。这个进度被称为“消费者的最后交付ID”(Last Delivered ID)。
消费进度的管理规则有两个关键场景:
-
消费组初始化:创建消费组时,需要指定“起始消费ID”。最常用的两个值是“$”和“0”: “$”:表示从当前Stream中最新的消息开始消费,适合“只处理新消息”的场景(比如实时日志处理)。
-
“0”:表示从Stream的第一条消息开始消费,适合“数据回溯”或“初始化消费历史数据”的场景(比如系统迁移后补数据)。
-
消费者重启:消费者重启后,向消费组请求消息时,消费组会根据记录的“最后交付ID”,从下一条消息开始分配,确保进度不中断。比如消费者上次处理到ID为“1697632000-1”的消息,重启后会直接领取“1697632000-2”及之后的消息。
这里的消息ID格式也很关键,Redis默认生成的消息ID是“时间戳-序列号”(比如1697632000-1),时间戳确保了消息的有序性,序列号则解决了同一毫秒内多条消息的排序问题。
三、Go语言实战:实现生产级消费组
理解了行为模式后,我们结合用户提供的完整代码案例,拆解基于Go语言的消费组实现。该案例场景为“任务分发处理”:1个生产者持续发送任务消息,2个消费者组成消费组协同处理,清晰体现消费组的负载均衡与可靠处理特性。
技术选型:使用最新的github.com/redis/go-redis/v9客户端(v9版本,官方推荐最新版),API设计更贴合Go语言风格,对Stream消费组的支持更完善。
1. 环境准备
(1)安装Redis
确保本地或服务器上安装了Redis 5.0及以上版本(Stream是5.0新增特性)。Windows用户可通过WSL安装,Linux用户直接用包管理器安装,安装后启动Redis服务:
# 启动Redis(默认端口6379)
redis-server
(2)安装Go-Redis客户端
在Go项目中执行以下命令,安装go-redis依赖:
go get github.com/go-redis/redis/v9
2. 完整代码拆解
整个案例分为4个核心模块:Redis连接初始化、消费组初始化、生产者逻辑、消费者逻辑。我们逐一实现并讲解关键细节。
(1)全局配置与Redis连接
代码开篇定义了Stream和消费组的核心常量,同时实现了极简且可靠的Redis连接逻辑——保留核心配置,避免冗余参数,兼顾易用性和稳定性。
首先定义全局常量(Stream名称、消费组名称等),并创建Redis客户端连接。连接Redis时,建议设置超时时间和重试策略,提高生产环境的稳定性。
package main
import (
"context"
"fmt"
"github.com/redis/go-redis/v9" // v9版本客户端,官方最新推荐
"log"
"math/rand"
"strings"
"sync"
"time"
)
// 全局核心常量:Stream名称和消费组名称,统一管理便于维护
const (
streamName = "task_stream" // Stream名称(对应消息队列)
groupName = "task_group" // 消费组名称
)
func main() {
// 1. 初始化Redis客户端连接(极简可靠配置)
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379", // Redis服务地址(默认端口)
DB: 0, // 操作的数据库编号(默认0号库)
})
ctx := context.Background() // 上下文,用于控制协程和Redis操作生命周期
// 2. 初始化消费组(确保消费组存在后再启动生产消费)
initConsumerGroup(ctx, rdb)
// 3. 用WaitGroup等待生产者和消费者协程完成,避免主程序提前退出
var wg sync.WaitGroup
// 4. 启动1个生产者协程
wg.Add(1)
go func() {
defer wg.Done() // 协程退出时通知WaitGroup
producer(ctx, rdb)
}()
// 5. 启动2个消费者协程(同属一个消费组,实现负载均衡)
wg.Add(2)
for i := 1; i <= 2; i++ {
consumerID := fmt.Sprintf("consumer_%d", i) // 给每个消费者分配唯一ID
// 注意:这里用函数参数传递consumerID,避免循环变量引用问题
go func(id string) {
defer wg.Done()
consumer(ctx, rdb, id)
}(consumerID)
}
// 6. 程序运行10秒后自动退出(测试用,生产环境可替换为信号监听)
time.AfterFunc(10*time.Second, func() {
fmt.Println("程序即将退出...")
os.Exit(0)
})
// 等待所有生产者和消费者协程完成
wg.Wait()
}
(2)消费组初始化:initConsumerGroup
消费组是多消费者协同的基础,必须在生产消费启动前初始化。该函数核心逻辑是“创建并容错”——首次运行创建消费组,重复运行时忽略“已存在”错误,确保程序可重启。
消费组只需要创建一次,后续程序重启时如果检测到消费组已存在,直接跳过即可。创建消费组用XGroupCreateMkStream方法,其中“MkStream”表示如果Stream不存在,会自动创建Stream。
这里要注意:go-redis v8及以上版本已经移除了旧的redis.IsError方法,判断“消费组已存在”的错误需要通过字符串匹配实现。
// 初始化消费组:首次创建,已存在则跳过(核心容错逻辑)
func initConsumerGroup(ctx context.Context, rdb *redis.Client) {
// XGroupCreateMkStream:核心命令,创建消费组
// 参数说明:ctx-上下文,streamName-Stream名称,groupName-消费组名称,"$"-起始消费位置
// "$"表示从当前Stream最新消息开始消费,避免消费历史消息
_, err := rdb.XGroupCreateMkStream(ctx, streamName, groupName, "$").Result()
if err != nil {
// 关键容错:只处理非"消费组已存在"的错误
// BUSYGROUP是Redis返回的消费组已存在的错误标识
if !strings.Contains(err.Error(), "BUSYGROUP") {
log.Fatalf("创建消费组失败: %v", err) // 非预期错误,终止程序
} else {
fmt.Printf("消费组 %s 已存在\n", groupName) // 预期错误,仅日志提示
}
} else {
fmt.Printf("消费组 %s 创建成功\n", groupName)
}
}
(3)生产者逻辑:producer
生产者的核心职责是“持续生成任务消息并发送到Stream”,代码用无限循环实现持续生产,同时通过随机数模拟任务ID,确保消息唯一性。
生产者的核心任务是向Stream发送消息。用XAdd方法发送消息时,我们不需要手动指定消息ID(用默认的“*”让Redis自动生成),确保消息ID的唯一性和有序性。
案例中,生产者模拟发送“用户点击日志”,包含用户ID、页面路径、点击时间等信息,每条消息间隔1-3秒(模拟真实场景的随机产生)。
// 生产者:向Stream持续发送任务消息
func producer(ctx context.Context, rdb *redis.Client) {
rand.Seed(time.Now().UnixNano()) // 初始化随机数种子,确保任务ID不重复
for { // 无限循环:持续生产消息(直到程序退出)
// 1. 构造消息内容:模拟任务(任务ID+发送时间)
taskID := rand.Intn(1000) // 生成0-999的随机任务ID
msgContent := fmt.Sprintf("task_%d", taskID) // 任务标识
// 消息用键值对存储,支持多字段(这里包含任务内容和发送时间)
msg := map[string]interface{}{
"task": msgContent,
"time": time.Now().Format(time.RFC3339), // 标准化时间格式,便于追溯
}
// 2. 发送消息到Stream:XAdd是核心命令
msgID, err := rdb.XAdd(ctx, &redis.XAddArgs{
Stream: streamName, // 目标Stream名称
Values: msg, // 消息内容(键值对)
// 注:未设置MaxLen时,Stream会存储所有消息;生产环境建议添加MaxLen防积压
}).Result()
// 3. 错误处理:发送失败时日志提示并退出(避免无限重试浪费资源)
if err != nil {
log.Printf("发送消息失败: %v", err)
return
}
// 4. 日志输出:打印发送结果(便于调试)
fmt.Printf("生产者发送消息,ID: %s,内容: %s\n", msgID, msgContent)
// 5. 模拟生产间隔:1-3秒发送一条(模拟真实场景的任务产生频率)
time.Sleep(time.Duration(rand.Intn(3)+1) * time.Second)
}
}
(4)消费者逻辑:consumer
消费者是消费组的核心执行单元,实现“从消费组取消息→处理消息→确认消息”的完整闭环,也是负载均衡和消息可靠处理的关键载体。
消费者是核心,流程简化为“读消息→打印处理→确认完成”三步,清晰展示消费组的工作逻辑:
-
用
XReadGroup从消费组读取消息,">"表示“只取未分配给其他消费者的新消息” -
Block: 5秒:无消息时阻塞等待,避免空轮询占用CPU资源 -
Count: 1:每次读取1条消息,确保处理完再取,避免消息堆积在消费者内存 -
处理完成后必须调用
XAck确认,否则消息会进入挂起列表等待重试
// 消费者:从消费组读取并处理消息(核心逻辑)
func consumer(ctx context.Context, rdb *redis.Client, consumerID string) {
for { // 无限循环:持续监听并处理消息
// 1. 从消费组读取消息:XReadGroup是核心命令
streams, err := rdb.XReadGroup(ctx, &redis.XReadGroupArgs{
Group: groupName, // 所属消费组名称
Consumer: consumerID, // 当前消费者唯一ID(用于消费组识别)
// Streams参数格式:[]string{Stream名称, 起始ID}
// ">"表示读取未分配给任何消费者的新消息,是消费组负载均衡的关键
Streams: []string{streamName, ">"},
Count: 1, // 每次读取1条,确保处理质量
Block: 5 * time.Second, // 无消息时阻塞5秒,超时后返回redis.Nil
}).Result()
// 2. 错误处理:区分"超时无消息"和"真实错误"
if err != nil {
// redis.Nil是阻塞超时的正常返回,直接继续循环等待
if err != redis.Nil {
// 其他错误(如Redis连接中断):日志提示并退出
log.Printf("消费者%s读取消息失败: %v", consumerID, err)
return
}
continue
}
// 3. 处理消息:遍历获取到的消息(Streams是数组,默认只处理一个Stream)
for _, stream := range streams {
for _, msg := range stream.Messages {
// 3.1 日志输出:打印接收信息(便于跟踪消息流向)
fmt.Printf("消费者%s接收消息,ID: %s,内容: %v\n", consumerID, msg.ID, msg.Values)
// 3.2 模拟业务处理:1-2秒(替换为真实业务逻辑,如执行任务、操作数据库等)
time.Sleep(time.Duration(rand.Intn(2)+1) * time.Second)
// 3.3 确认消息处理完成:XAck是可靠性的核心
_, err := rdb.XAck(ctx, streamName, groupName, msg.ID).Result()
if err != nil {
// 确认失败:日志记录(后续可通过XPENDING查询并重试)
log.Printf("消费者%s确认消息%s失败: %v", consumerID, msg.ID, err)
} else {
// 确认成功:日志提示(完成闭环)
fmt.Printf("消费者%s确认消息%s\n", consumerID, msg.ID)
}
}
}
}
}
(5)主函数:统筹调度核心
主函数是整个程序的“总指挥”,按“初始化→启动生产消费→控制退出”的流程组织代码,其中两个细节值得重点关注:
-
sync.WaitGroup:确保主程序等待所有生产者和消费者协程完成后再退出,避免协程未执行完被强制终止 -
循环变量传递:启动消费者时用函数参数传递
consumerID,避免循环变量引用导致的ID错乱问题(Go语言常见坑)
主函数负责初始化Redis客户端、消费组,然后启动多个生产者和消费者(用sync.WaitGroup等待所有协程完成,避免主程序提前退出)。为了方便测试,我们设置程序运行15秒后自动退出。
// 主函数已整合在全局配置模块中,此处重点拆解调度逻辑:
// 1. 先初始化Redis和消费组:确保依赖就绪后再启动生产消费,避免资源竞争
// 2. 生产者和消费者用协程启动:实现异步生产消费,发挥消息队列异步解耦特性
// 3. WaitGroup控制退出:防止主程序提前退出,确保协程正常执行
// 4. 10秒自动退出:测试场景专用,生产环境建议替换为信号监听(如Ctrl+C退出)
3. 运行与调试实战
通过实际运行代码和Redis命令调试,能更直观理解消费组的工作机制。以下是完整的操作步骤和预期效果。
(1)运行步骤
-
安装依赖:在项目目录执行命令安装Redis客户端
go get github.com/redis/go-redis/v9 -
启动Redis:确保本地Redis服务正常运行(默认端口6379)
redis-server -
运行代码:将代码保存为
main.go,执行命令运行go run main.go
运行后会输出如下日志(关键部分标注,体现核心特性):
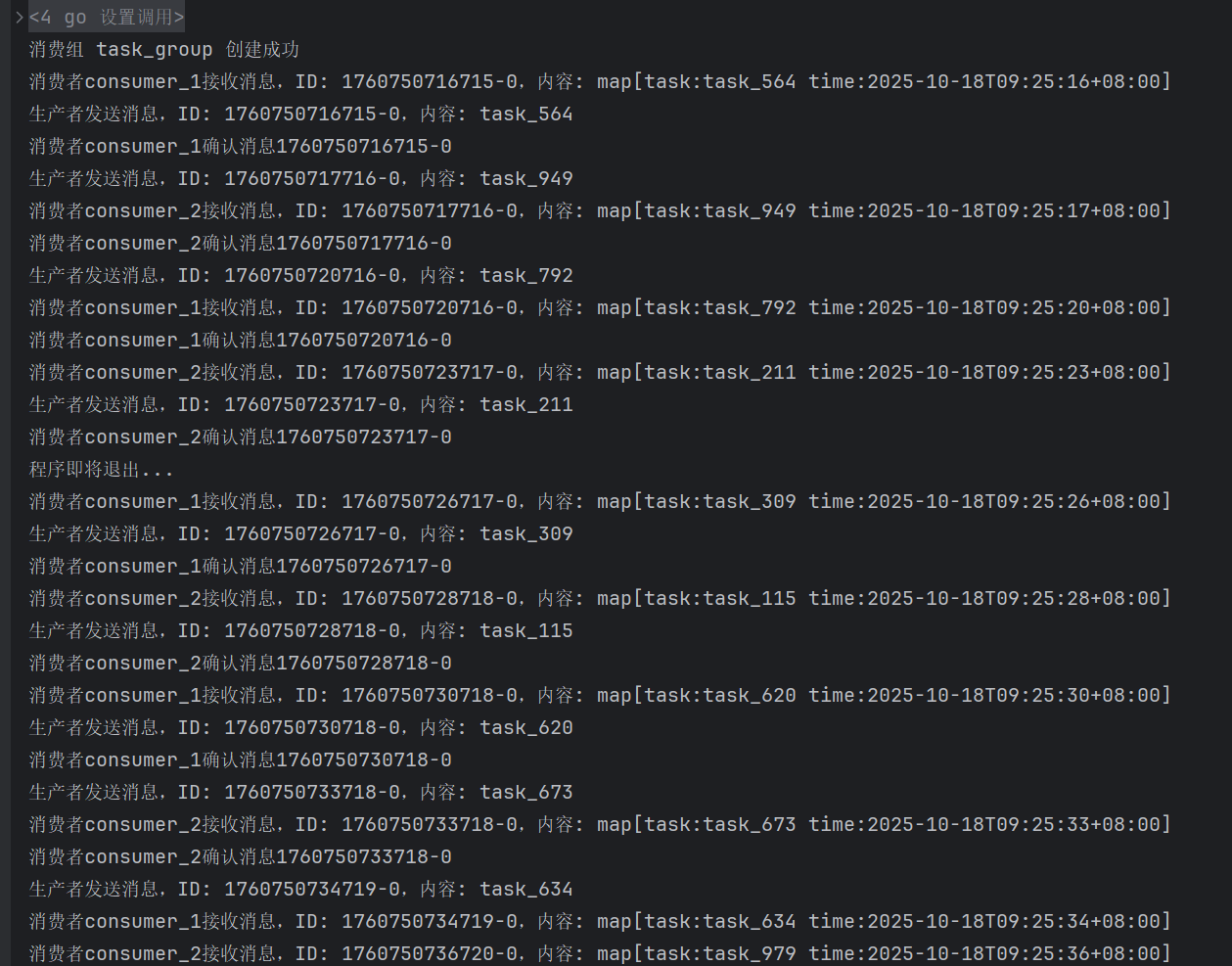
从日志可清晰看到消费组的两大核心价值:
-
负载均衡:两条消息分别分配给consumer_1和consumer_2,消费组自动轮询分配,避免单消费者过载
-
可靠处理:每条消息都经过“发送→接收→处理→确认”闭环,未确认的消息会留在挂起列表,不会丢失
-
容错性:重复运行程序时,消费组已存在的错误被忽略,程序正常启动
-
负载均衡:消息被轮流分给3个消费者,不会出现一个忙死、其他闲死的情况
-
可靠处理:每个消息都走“发送→处理→确认”流程,确保不会漏处理
-
异步性:生产者发完就走,不用等消费者处理,这就是消息队列的核心优势
-
消息被均匀分配给3个消费者(consumer_1、consumer_2、consumer_3),实现了负载均衡。
-
每个消息都经过“接收→处理→确认”的完整流程,确保可靠性。
-
生产者发送消息后立即返回,消费者异步处理,体现了消息队列的异步特性。
(2)调试命令:用Redis-cli查看核心状态
运行代码时,可打开另一个终端,用以下Redis命令查看消费组状态,辅助调试和问题定位:
调试时用Redis命令行看状态,更直观理解消费组工作原理(复制命令直接执行):
-
XINFO STREAM task_stream→ 查看Stream详情(消息总数、消费组数量等) 预期输出包含“groups:1”(1个消费组)和“entries:2”(2条消息)等信息 -
XINFO CONSUMERS task_stream task_group→ 查看消费组内消费者状态 预期输出2个消费者,每个消费者的“pending”(挂起消息数)为0(已确认) -
XPENDING task_stream task_group→ 查看挂起消息(未确认的消息) 正常情况下输出“0”,表示所有消息已确认处理 -
XRANGE task_stream - +→ 查看Stream内所有消息 可看到每条消息的ID、任务内容和发送时间
四、生产环境避坑指南
案例中的代码已经具备基本的生产级特性,但在实际部署时,还需要注意以下5个关键问题,避免踩坑。
1. 消息积压问题:给Stream加“容量上限”
用户提供的代码未设置Stream最大长度,若生产者发送速度远快于消费者处理速度,消息会持续积压导致Redis内存溢出。生产环境必须添加MaxLen参数限制消息数量:
如果消费者处理速度远慢于生产者发送速度,Stream中的消息会不断积压,导致Redis内存溢出。解决方法是在发送消息时设置MaxLen参数,保留最新的N条消息:
// 生产者发送消息时添加MaxLen配置(修改XAddArgs部分)
msgID, err := rdb.XAdd(ctx, &redis.XAddArgs{
Stream: streamName,
Values: msg,
MaxLen: 100, // 保留最新100条消息,旧消息自动删除
Approx: true, // 近似修剪,大幅提升性能(牺牲少量精度)
}).Result()
注意:Approx: true表示“近似修剪”,Redis不会精确计算消息数量,而是批量修剪,大幅提高性能。如果业务要求严格保留最新N条,可将其设为false,但会影响性能。
2. 消费者崩溃:处理“遗留未确认消息”
若消费者处理消息时崩溃(未执行XAck),消息会进入挂起列表。可在消费者启动时添加“遗留消息处理”逻辑,确保消息不丢失:
如果消费者崩溃,未确认的消息会留在挂起列表中。生产环境中,需要定期查询挂起消息并重新分配处理。可以在消费者启动时,先处理挂起消息:
// 新增:处理消费组内的挂起消息(消费者启动时调用)
func handlePendingMessages(ctx context.Background(), rdb *redis.Client, consumerID string) {
// 1. 查询挂起消息的统计信息(起始ID、结束ID、总数等)
pending, err := rdb.XPending(ctx, streamName, groupName).Result()
if err != nil || pending.Count == 0 {
return // 无错误或无挂起消息,直接返回
}
// 2. 读取挂起消息(从起始ID开始,读取所有未处理消息)
streams, err := rdb.XReadGroup(ctx, &redis.XReadGroupArgs{
Group: groupName,
Consumer: consumerID,
// 这里用pending.Start作为起始ID,读取历史挂起消息
Streams: []string{streamName, pending.Start},
Count: int(pending.Count), // 读取所有挂起消息
}).Result()
if err != nil {
log.Printf("消费者%s读取挂起消息失败: %v", consumerID, err)
return
}
// 3. 处理挂起消息(逻辑和正常消息一致)
for _, stream := range streams {
for _, msg := range stream.Messages {
taskContent, _ := msg.Values["task"].(string)
log.Printf("消费者%s处理遗留消息 | ID:%s | 内容:%s", consumerID, msg.ID, taskContent)
// 处理完成后确认
_ = rdb.XAck(ctx, streamName, groupName, msg.ID).Err()
}
}
}
// 修改消费者函数:启动时先处理遗留消息
func consumer(ctx context.Context, rdb *redis.Client, consumerID string) {
// 启动时先处理挂起的遗留消息
handlePendingMessages(ctx, rdb, consumerID)
// 后续正常消费逻辑不变...
}
3. 优雅退出:替换“固定10秒退出”为“信号监听”
用户代码中10秒固定退出仅适合测试,生产环境需监听系统信号(如Ctrl+C)实现优雅退出,避免消息处理到一半被强制终止:
案例中用time.AfterFunc实现了简单的退出,但生产环境中需要监听系统信号(比如Ctrl+C、kill命令),实现优雅退出:
// 导入必要包(在文件开头添加)
import (
"os"
"os/signal"
"syscall"
)
// 修改主函数中的退出控制逻辑
func main() {
rdb := redis.NewClient(&redis.Options{Addr: "localhost:6379", DB: 0})
ctx := context.Background()
initConsumerGroup(ctx, rdb)
var wg sync.WaitGroup
// ... 启动生产者和消费者的代码不变 ...
// 替换固定10秒退出为信号监听
quit := make(chan os.Signal, 1)
// 监听Ctrl+C(SIGINT)和kill命令(SIGTERM)
signal.Notify(quit, syscall.SIGINT, syscall.SIGTERM)
// 收到信号后优雅退出
go func() {
<-quit
fmt.Println("收到退出信号,正在收尾...")
// 关闭Redis连接池
_ = rdb.Close()
os.Exit(0)
}()
wg.Wait()
}
4. 分布式部署:Redis集群适配
用户代码使用单点Redis,生产环境需部署Redis集群避免单点故障。v9版本客户端支持集群连接,只需修改Redis初始化逻辑:
如果Redis是单点部署,一旦Redis崩溃,整个消息队列会不可用。生产环境中,需要部署Redis集群(主从+哨兵或Redis Cluster),提高可用性。go-redis客户端支持集群连接:
5. 监控告警:关注关键指标
生产环境中,需要监控消费组的关键指标,出现异常时及时告警:
-
Stream消息数量:突然激增可能表示消费者处理缓慢。
-
挂起消息数量:持续增加表示有消费者崩溃或处理失败。
-
消费者活动状态:长时间未活动的消费者可能已崩溃。
可以用Prometheus+Grafana监控这些指标,或直接通过Redis的INFO命令获取指标数据。
五、总结
Redis Stream消费组通过“智能分配”“消息确认”“进度记录”三大核心机制,完美解决了分布式环境下的消息协同消费问题。用Go语言实现时,借助go-redis客户端的简洁API,我们可以快速构建生产级的消费组系统。
核心要点回顾:
-
消费组是协调多消费者的“管理机制”,解决重复消费和负载均衡问题。
-
消息确认(ACK)是可靠性的核心,未确认的消息会进入挂起列表重试。
-
生产环境中需关注消息积压、优雅退出、集群部署等问题,避免踩坑。
相比RabbitMQ、Kafka等专业消息队列,Redis Stream消费组更轻量、部署成本更低,适合中小型分布式系统;如果需要更复杂的路由策略(如主题订阅)或超高吞吐量,可考虑专业消息队列。但对于大部分场景,Redis Stream消费组已经足够好用!

















 499
499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









