








目录
1. 循环语句
- while循环
- for循环(后期)
while 条件: ... ...print("123") while 条件: ... ... print(456)
1.1 循环语句基本使用
示例:
data = True
print("开始")
while data:
print("如果祖国遭受到侵犯,热血男儿当自强。")
print("结束")练习题:重复3次输出我爱我的祖国。
num = 1
while num < 4:
print("我爱我的祖国")
num = num + 11.2 综合小案例
- 请实现一个用户登录系统,如果密码错误则反复提示让用户重新输入,直到输入正确才停止。
# 请实现一个用户登录系统,如果密码错误则反复提示让用户重新输入,直到输入正确才停止。
print("开始运行xiaofeng系统")
flag = True
while flag:
user = input("请输入用户名:")
pwd = input("请输入密码:")
if user == "xiaofeng" and pwd == "123456":
print("登录成功")
flag = False
else:
print("用户名或密码错误")
print("系统结束")
1.3 break
- break,用于在while循环中帮你终止循环。
print("开始")
while True:
print("1")
break
print("2")
print("结束")- 通过示例来更深入理解break的应用。
示例:
print("开始")
i = 1
while True:
print(i)
i = i + 1
if i == 11:
break
print("结束")注意:以后写代码时候,想要结束循环可以通过两种方式实现了,即:条件判断 和 break关键字,两种在使用时无好坏之分,只要能实现功能就行。
1.4 continue
continue,在循环中用于 结束本次循环,开始下一次循环。
print("开始")
while True:
print(1)
continue
print(2)
print(3)
print("结束")
#结果是在终端不断地输出 1
示例1:
print("开始")
i = 1
while i > 101:
if i == 7:
i = i + 1
continue
print(i)
i = i + 1
print("结束")
# 输出
开始
1
2
3
4
5
6
8
9
10
...
100
结束
示例2:
print("开始")
i = 1
while True:
if i == 7:
i = i + 1
continue
print(i)
i = i + 1
if i == 101:
break
print("结束")
# 输出
开始
1
2
3
4
5
6
8
9
10
...
100
结束
Tip: 写在最后,对于break和continue都是放在循环语句中用于控制循环过程的,一旦遇到break就停止所有循环,一旦遇到continue就停止本次循环,开始下次循环。当然,通过如果没有了break和continue,我们用while条件的判断以及其他协助也能完成很多功能,有了break和continue可以在一定程度上简化我们的代码逻辑。
1.5 while...else..
- 当while后的条件不成立时,else中的代码就会执行。
while 条件:
代码
else:
代码
while False:
pass
else:
print(123)
n=1
while n<5:
print(n)
n+=1
else:
print("数字n等于5了")
# 输出
1
2
3
4
数字n等于5了
2.字符串格式化
- 字符串格式化,使用跟便捷的形式实现字符串的拼接。
2.1 %
2.1.1 基本格式化操作
name = "小峰"
# 占位符
text1 = "我叫%s,今年18岁" %"小峰"
text2 = "我叫%s,今年18岁" %name
print(text1,text2)
#输出的结果一样message = "%(name)s你什么时候去学习?%(user)。" % {"name": "小峰", "user": "李杰"}
print(message)
2.1.2 百分比
text = "兄弟,这个文件我已经下载了90%了,居然断网了"
print(text)
text = "%s,这个文件我已经下载了90%%了,居然断网了" %"兄弟"
print(text)
# 输出:
兄弟,这个电视剧我已经下载了90%了,居然断网了
注意:一旦字符串格式化中存现百分比的显示,请一定要加 %% 以实现输出 %。
2.2 format(推荐)
text = "我叫{0},今年18岁".format("武沛齐")
text = "我叫{0},今年{1}岁".format("武沛齐",18)
text = "我叫{0},今年{1}岁,真是的姓名是{0}。".format("武沛齐",18)
- 输出结果如下:

text = "我叫{},今年{}岁,真实的姓名是{}。".format("小峰",18,"小峰")
#输出:我叫小峰,今年18岁,真实的姓名是小峰。text = "我叫{n1},今年18岁".format(n1="小峰")
text = "我叫{n1},今年{age}岁".format(n1="小峰",age=18)
text = "我叫{n1},今年{age}岁,真是的姓名是{n1}。".format(n1="小峰",age=18)
text = "我叫{0},今年{1}岁"
data1 = text.format("小峰",666)
data2 = text.format("alex",73)
text = "我叫%s,今年%d岁"
data1 = text %("小峰",20)
data2 = text %("alex",84)
2.3 f
- 到Python3.6版本,更便捷。
text = f"他的名字叫喵喵,今年{19 + 2}岁"
print(text)
# 在Python3.8引入
text = f"他的名字叫喵喵,今年{19 + 2=}岁"
print(text)
#输出结果:他的名字叫喵喵,今年19 + 2=21岁# 进制转换
v1 = f"他今年{22}岁"#十进制
print(v1)
v2 = f"他今年{22:#b}岁" #转化为二进制
print(v2)
v3 = f"他今年{22:#o}岁"#转化为8进制
print(v3)
v4 = f"他今年{22:#x}岁"#转化为16进制
print(v4)# 理解
text = f"我是{'alex'},我学习"
name = "alex"
text = f"我是{name},我学习"
name = "alex"
text = f"我是{ name.upper() },我学习" #upper() 的作用是将小写转化为大写
# 输出:我是ALEX,我学习
3. 运算符
- 提到运算符,我想大家首先想到的就是加、减、乘、除之类, 本节要系统的跟大家来聊一聊,我们写代码时常见的运算符可以分为5种:
算数运算符,例如:加减乘除
print( 9//2 )比较运算符,例如:大于、小于
注意:python3中不支持
<、>if 1 >2: pass while 1>2: pass data = 1 == 2赋值运算,例如:变量赋值
num = 1 while num < 100: print(num) num += 1成员运算,例如:是否包含
v1 = "le" in "alex" # True/False # 让用户输入一段文本,检测文本中是否包含XX词。 text = input("请输入内容:") if "苍老师" in text: print("少儿不宜") else: print(text)逻辑运算,例如:且或非
if username == "alex" and pwd == "123": pass data = 1 < 2 if not data: pass3.1 运算符优先级
运算符的优先级有很多,常见的没几个,推荐你记住3个即可:
算数优先级优先级 大于 比较运算符
if 2 + 10 > 11: print("真") else: print("假")比较运算符优先级 大于 逻辑运算符
if 1>2 and 2<10: print("成立") else: print("不成立")逻辑运算符内部三个优先级 not > and > or
if not 1 and 1<2 or 3 == 8: print("真") else: print("假")上述这3个优先级从高到低总结:
加减乘除 > 比较 > not and or。绝招:如果你实在分不清,你可以给你想让先运算的加括号。
3.2 面试题
- 逻辑运算中:and or
v2 = "wupeiqi" and "alex" # 第一步:将and前后的只转换为布尔值 True and True # 第二步:判断本次操作取决于谁?由于前面的是True,所以本次逻辑判断取决于后面的值。 # 所以,后面的只等于多少最终结果就是多少。 v2 = "alex" v3 = "" and "alex" # 第一步:将and前后的只转换为布尔值 False and True # 第二步:判断本次操作取决于谁?由于前面的是False,所以本次逻辑判断取决于前面的值。 # 所以,前面的只等于多少最终结果就是多少。 v2 = "" v4 = 1 or 8 # 第一步:将and前后的只转换为布尔值 True or True # 第二步:判断本次操作取决于谁?由于前面的是True,所以本次逻辑判断取决于前面的值。 # v4 = 1 v5 = 0 or 8 # 第一步:将and前后的只转换为布尔值 False or True # 第二步:判断本次操作取决于谁?由于前面的是False,所以本次逻辑判断取决于后面的值。 # v5 = 8v1 = 0 or 4 and 3 or 7 or 9 and 6 #过程 0 or 3 or 7 or 9 and 6 0 or 3 or 7 or 6 3 or 7 or 6 3 or 6 3v4 = not 8 or 3 and 4 or 2 4
总结:
- or,看第一个值,如果第一个值为真,结果就应该是第一个值,否则就结果就是第二个值。
- and,看第一个值,如果第一个值真,结果就应该是第二个值,否则结果就是第一个值。
- 如果多个and 和or的情况,先计算and再计算or。
- 先计算not,在计算and,最后计算or。
4、进制
计算机中底层所有的数据都是以 010101的形式存在(图片、文本、视频等)。
-
二进制
-
八进制
-
十进制
-
十六进制
4.1 进制转换
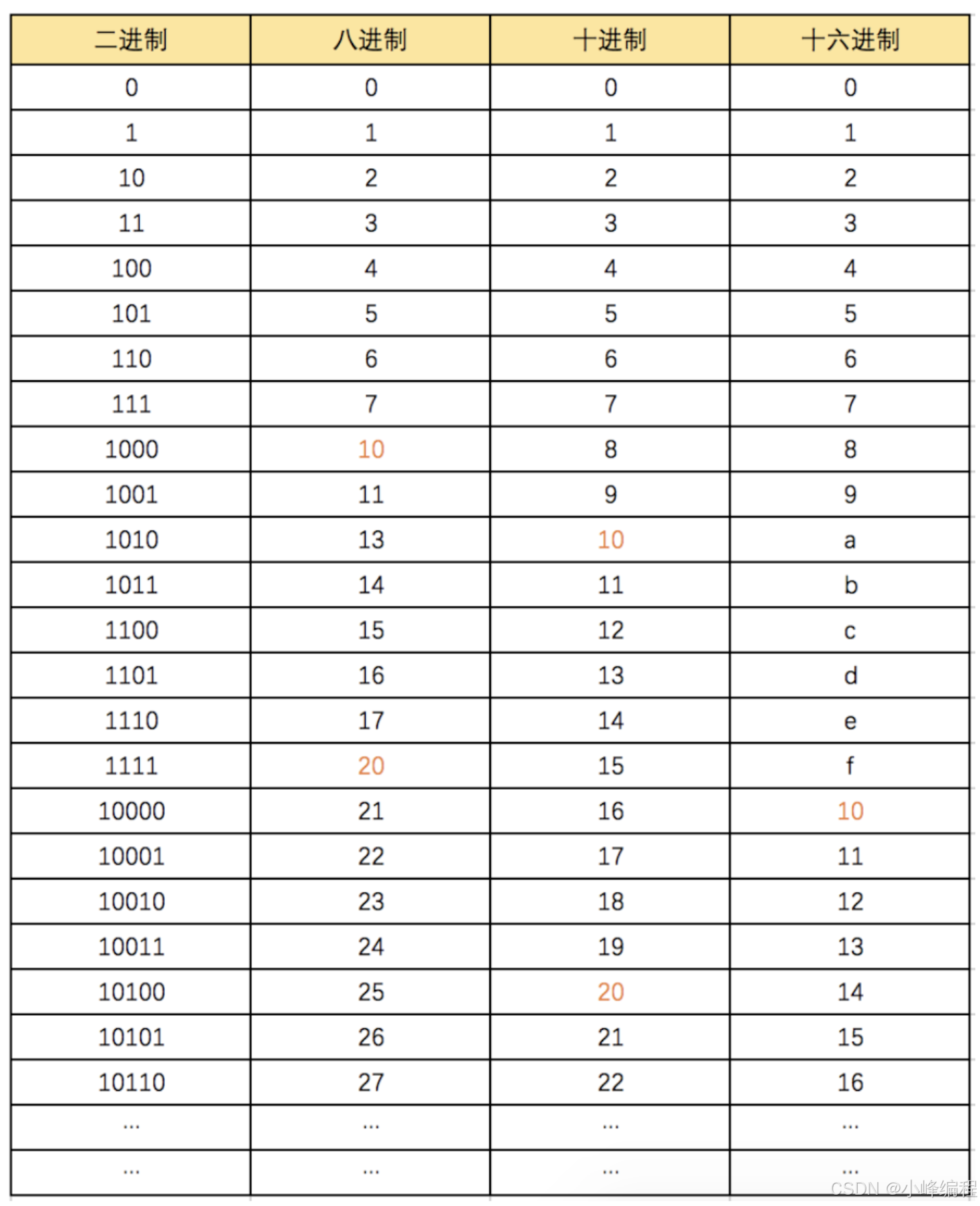
#十进制转化为二进制
v1=bin(10)
print(v1)
#十进制转化为八进制
v2=oct(10)
print(v2)
#十进制转化为十六进制
v3=hex(10)
print(v3)#二进制转化为10进制
v1=int("0b1010",base=2)
print(v1)
#八进制转化为十进制
v2=int("0o12",base=8)
print(v2)
#十六进制转化为十进制
v3=int("0x0a",base=16)
print(v3)4.2. 计算机中的单位
由于计算机中本质上所有的东西以为二进制存储和操作的,为了方便对于二进制值大小的表示,所以就搞了一些单位。
-
b(bit),位。
1,1位 10,2位 111,3位 1001,4位 -
B(byte),字节,1个字节就是8个比特位(b)。
10010110,1个字节 10010110 10010110,2个字节 -
KB(kilobyte),千字节 ,1024个字节就是1个千字节。
10010110 11010110 10010111 .. ,1KB 1KB = 1024B= 1024 * 8 b -
M(Megabyte),兆,1024KB就是1M。
1M= 1024KB = 1024 * 1024 B = 1024 * 1024 * 8 b -
G(Gigabyte),千兆,1024M就是1G。
1 G= 1024 M= 1024 *1024KB = 1024 * 1024 * 1024 B = 1024 * 1024 * 1024 * 8 b -
T(Terabyte),万亿字节。
1024个G就是1T -
…其他更大单位 PB/EB/ZB/YB/BB/NB/DB 不再赘述。
-
假设1个汉字需要2个字节(2B=16位来表示,如:10001010 11001100),那么1G流量可以通过网络传输多少汉字呢?(计算机传输本质上也是二进制)
1G = 1024M = 1024 * 1024KB = 1024 * 1024 * 1024 B 每个汉字需要2个字节表示 1024 * 1024 * 1024/2 =536870912 -
假设1个汉字需要2个字节(2B=16位来表示,如:1000101011001100),那么500G硬盘可以存储多少个汉字?
500G = 500 * 1024M = 500 * 1024 * 1024KB = 500 * 1024 * 1024 * 1024 B 500 * 1024 * 1024 * 1024 / 2 = 268435456000
5.编码
- 编码言外之意就是文字和二进制之间的一个对照表。
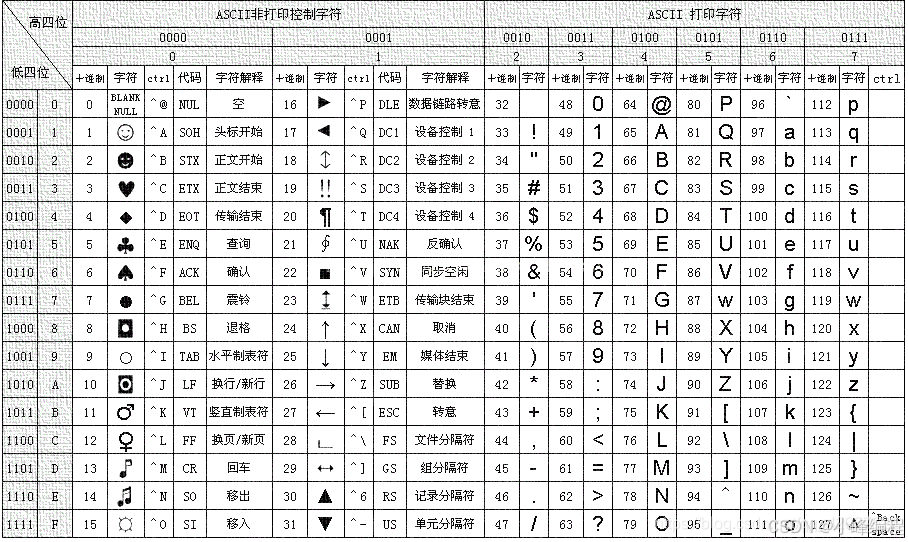
5.1 ascii编码
- ascii规定使用1个字节来表示字母与二进制的对应关系。
00000000
00000001
00000010
00000011
...
11111111
2**8 = 256(种)
5.2 gb-2312编码
gb-2312编码,由国家信息标准委员会制作(1980年)。gbk编码,对gb2312进行扩展,包含了中日韩等文字(1995年)。在与二进制做对应关系时,由如下逻辑:
- 单字节表示,用一个字节表示对应关系。2**8 = 256
- 双字节表示,用两个字节表示对应关系。2**16 = 65536中可能性。
5.3 unicode
unicode也被称为万国码,它为全球的每个文字都分配了一个码位(二进制表示)。
-
ucs2:使用固定的2个字节去表示一个文字。
00000000 00000000 悟 ... 2**16 = 65535 -
ucs4:使用固定的4个字节去表示一个文字。
00000000 00000000 00000000 00000000 无 ... 2**32 = 4294967296
文字 十六进制 二进制 编码形式
ȧ 0227 1000100111
ȧ 0227 00000010 00100111 ucs2
ȧ 0227 00000000 00000000 00000010 00100111 ucs4
😆 1F606 11111011000000110
😆 1F606 00000000 00000001 11110110 00000110 ucs4
无论是ucs2和ucs4都有缺点,都存在着浪费空间的现象。
文字 十六进制 二进制
A 0041 01000001
A 0041 00000000 01000001
A 0041 00000000 00000000 00000000 01000001
unicode编码的应用:在文件存储和网络传输时,一般我们不会直接使用unicode编码,而是在内存中会unicode编码。
5.4 utf-8编码
包含所有文字和二进制的对应关系,全球应用最为广泛的一种编码(即就是说:站在巨人的肩膀上功成名就)。本质上:utf-8编码是对unicode编码的压缩,因此它是用尽量少的二进制去与文字进行对应。
unicode码位范围 utf-8
0000 ~ 007F 用1个字节表示
0080 ~ 07FF 用2个字节表示
0800 ~ FFFF 用3个字节表示
10000 ~ 10FFFF 用4个字节表示
具体编码压缩的流程:
第一步:选择对应的转换模板
码位范围(十六进制) 转换模板 0000 ~ 007F 0XXXXXXX 0080 ~ 07FF 110XXXXX 10XXXXXX 0800 ~ FFFF 1110XXXX 10XXXXXX 10XXXXXX 10000 ~ 10FFFF 11110XXX 10XXXXXX 10XXXXXX 10XXXXXX 例如: "B" 对应的unicode码位为 0042,那么他应该选择的一个模板。 注意:一般中文都是使用第三个模板(3个字节),这也就是平时大家说中文在utf-8中会 占3个字节的原因了。第二步:在模板中正确填入数据
- "武" -> 6B66 -> 110 101101 100110 - 根据模板套入数据 1110XXXX 10XXXXXX 10XXXXXX 1110XXXX 10XXXXXX 10100110 1110XXXX 10101101 10100110 11100110 10101101 10100110 在UTF-8编码中 ”武“ 11100110 10101101 10100110
5.5 Python相关的编码
字符串(str) "男孩" unicode处理 一般用于内存
字节(byte) b"achaasas" utf-8编码 or gbk编码 一般用于文件或网络处理
v1="峰"
z1=v1.encode('utf-8')
z2=v1.encode('gbk')
print(z1)
print(z2)将一个字符串写入到一个文件中:
name = "好好学习编程技术"
data = name.encode("utf-8")
# 打开文件
file = open("log.txt",mode="wb")
# 在文件中进行写内容
file.write(data)
# 关闭文件
file.close()
补充:
-
实现将字符串转换为字节(utf-8编码)
data="小峰编程".encode("utf-8") print(data)#把字符串转化为字节形式 print(data.decode("utf-8"))#把字节形式转为字符串的形式 -
实现将字符串转换为字节(gbk编码)
data="小峰编程".encode("gbk") print(data)#把字符串转化为字节形式 print(data.decode("gbk"))#把字节形式转为字符串的形式
本 篇 完 结 … …
持 续 更 新 中 … …



















 119
119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











