






Finetune介绍

主要有两种微调范式,目的是使基座大模型成为垂直模型
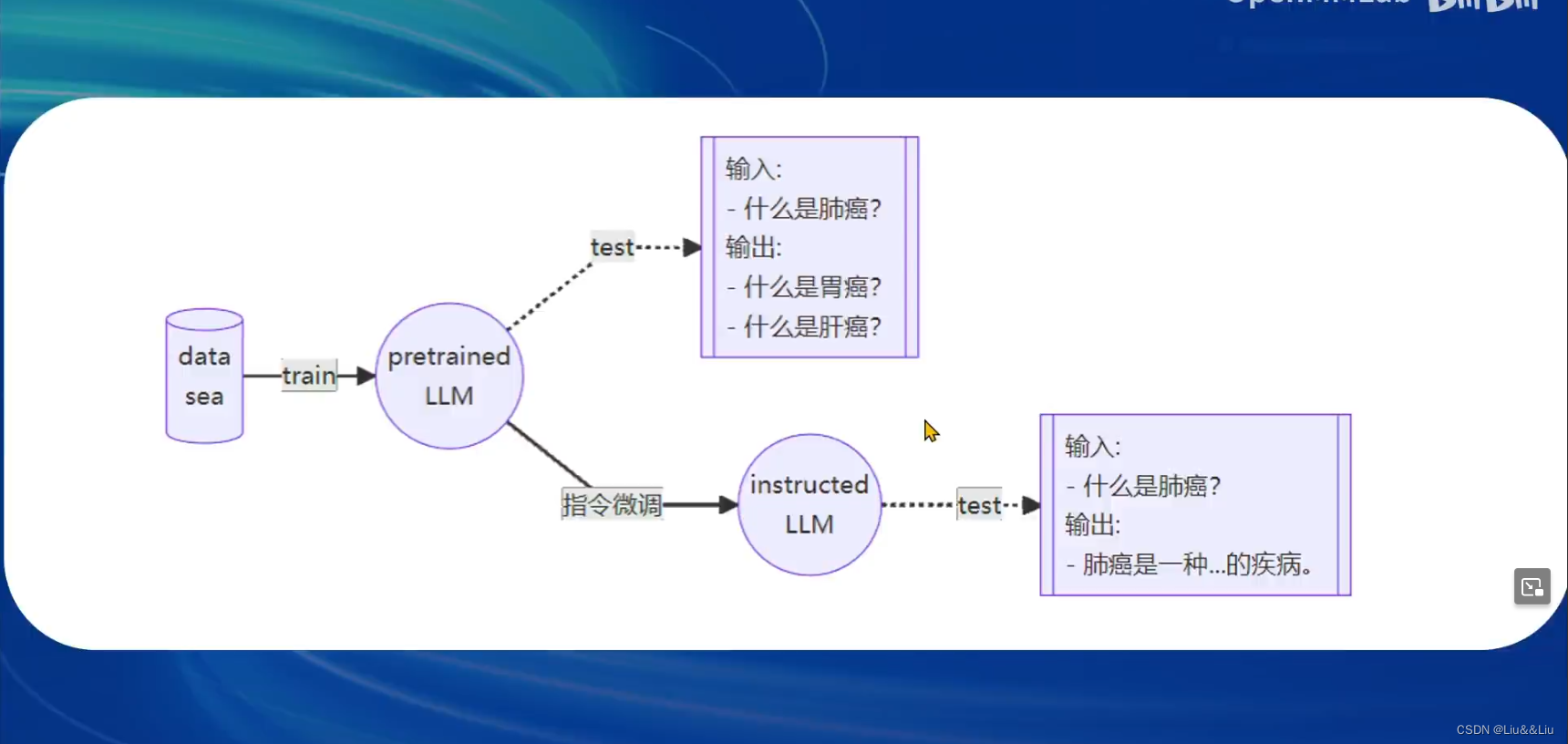
什么是指令微调————就是有对话

数据要可以被系统利用
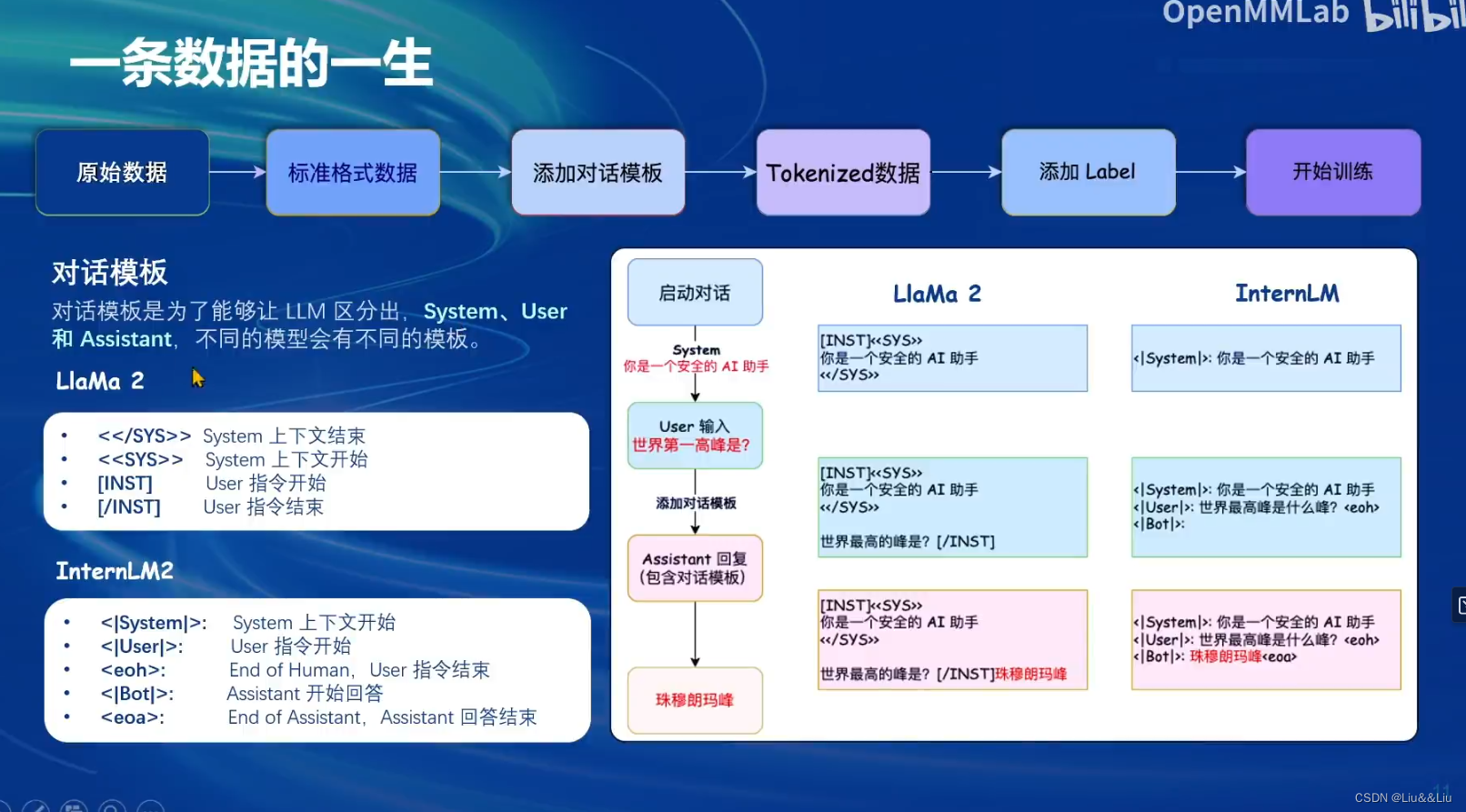
不同模型有不同的输入/输出模板
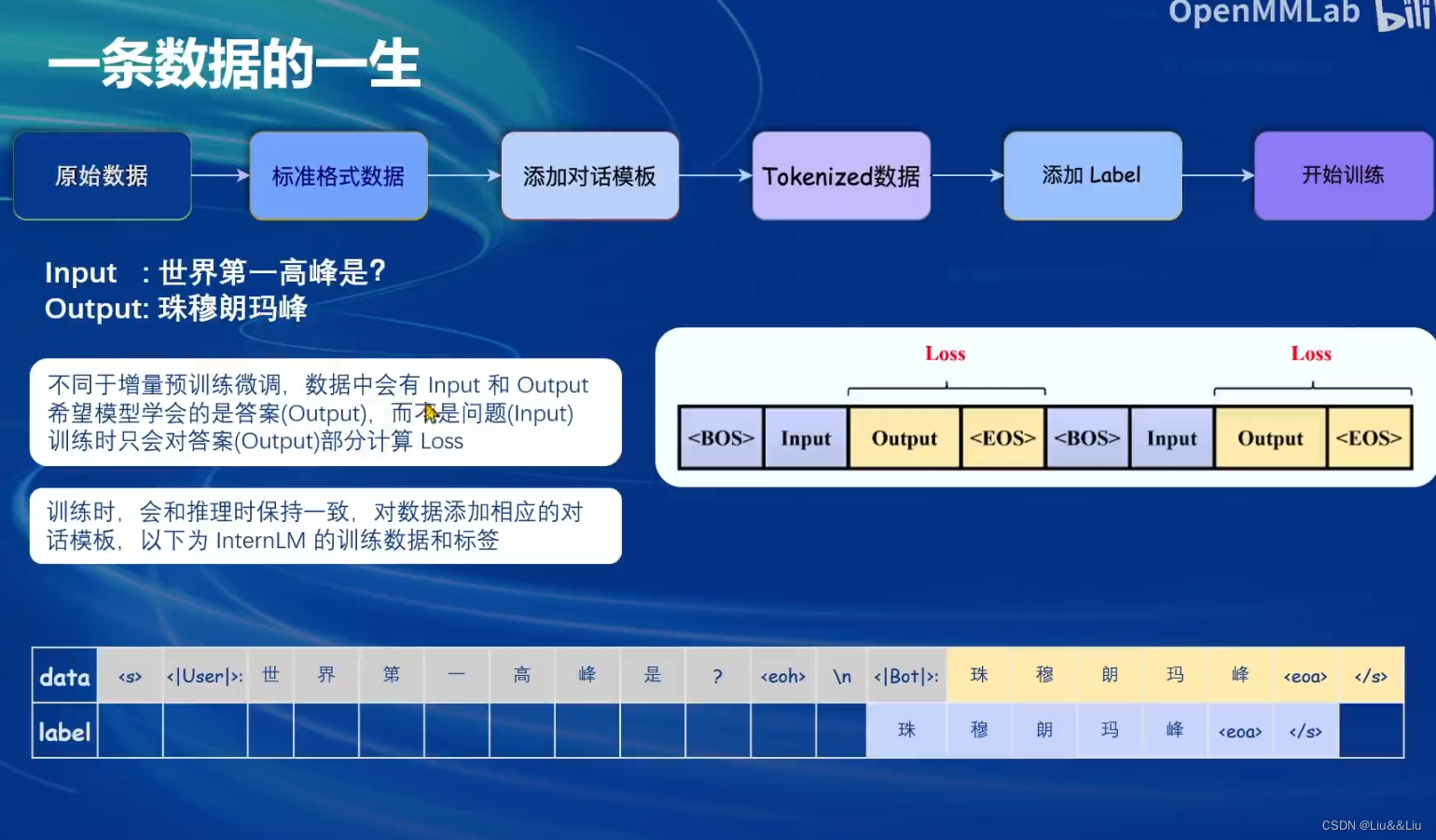
喂给模型的是拼装好的
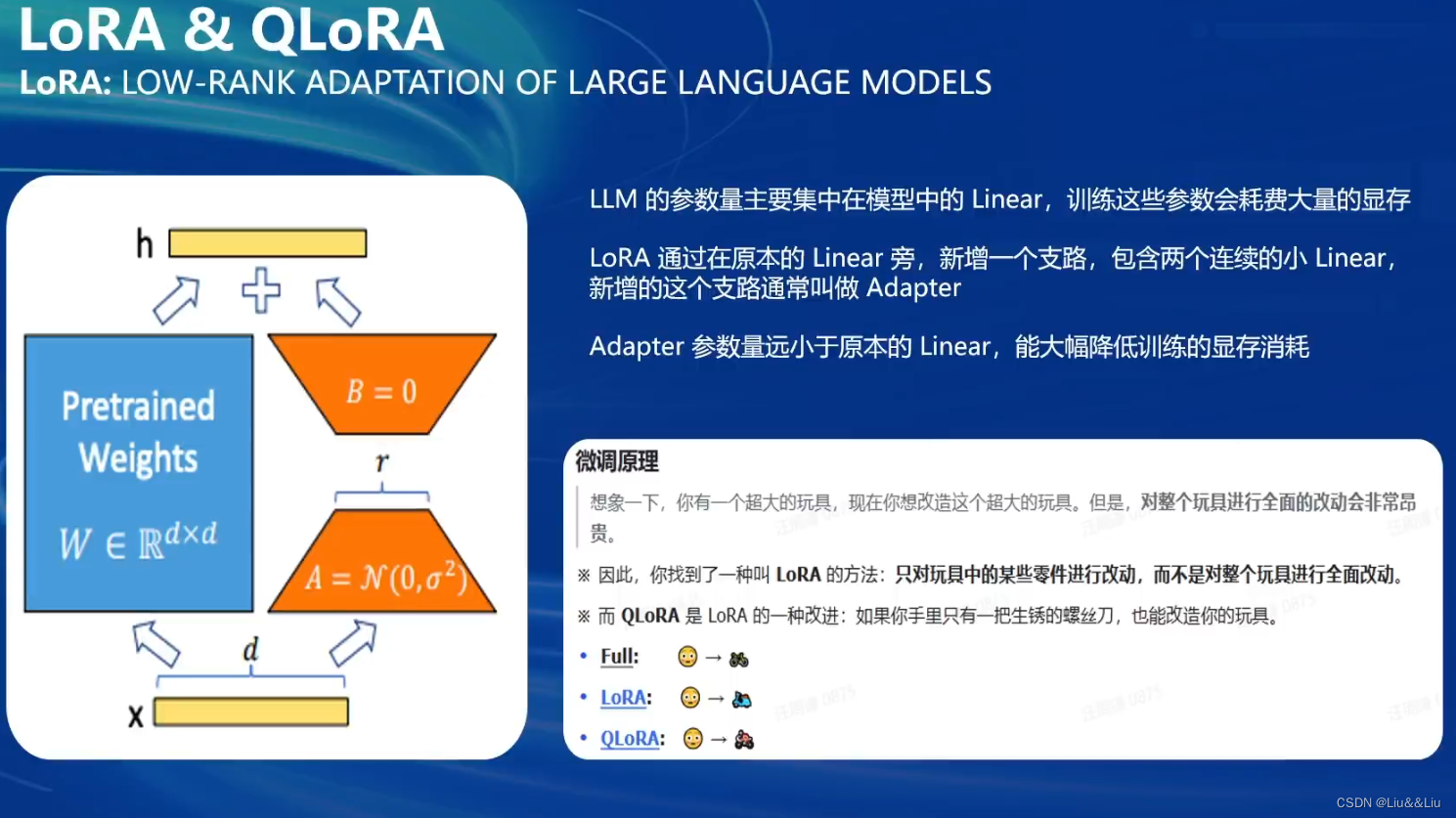
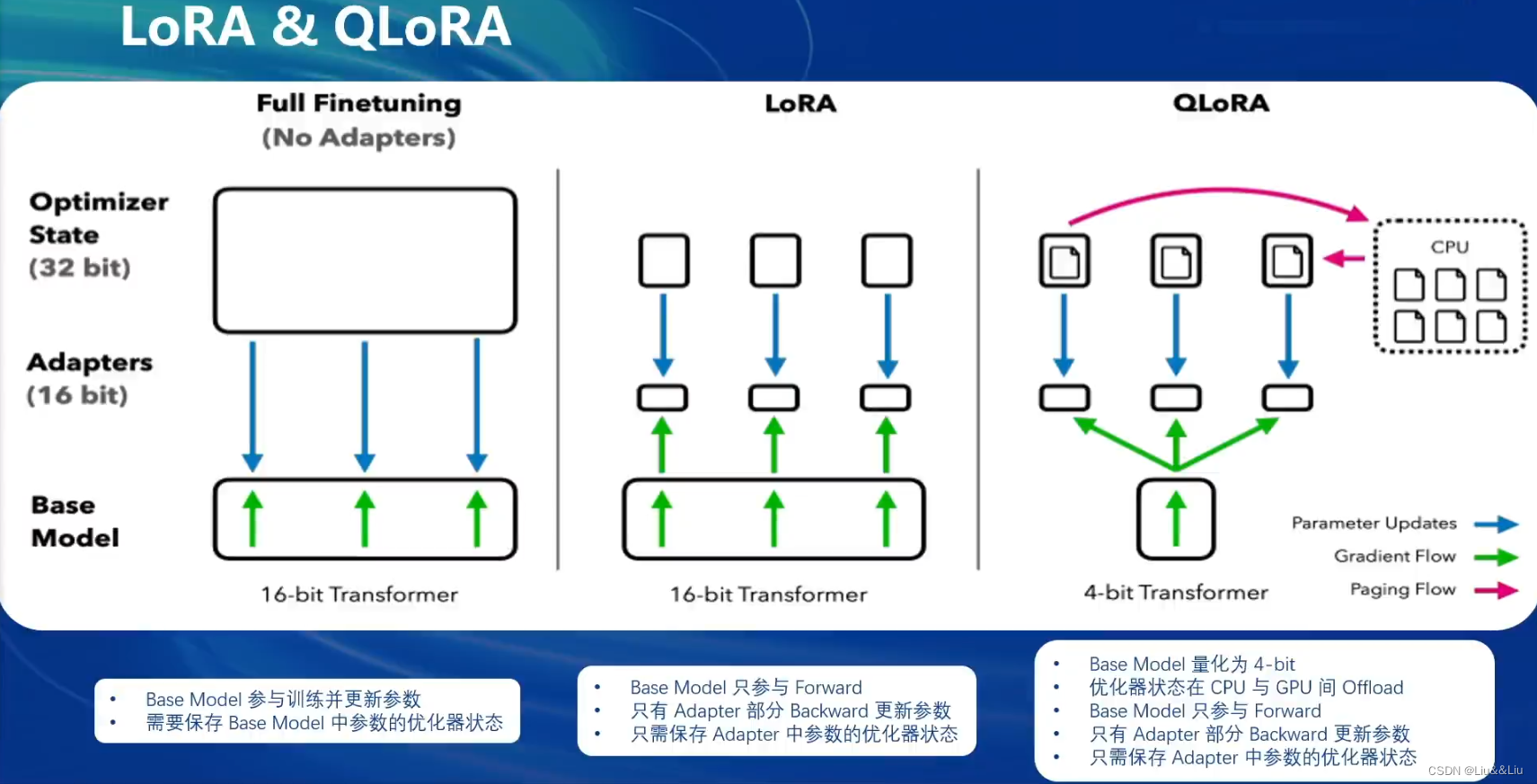
基座不变,在基座上微调lora,新建小linear,也就是adapter。主要目的是减少开销。
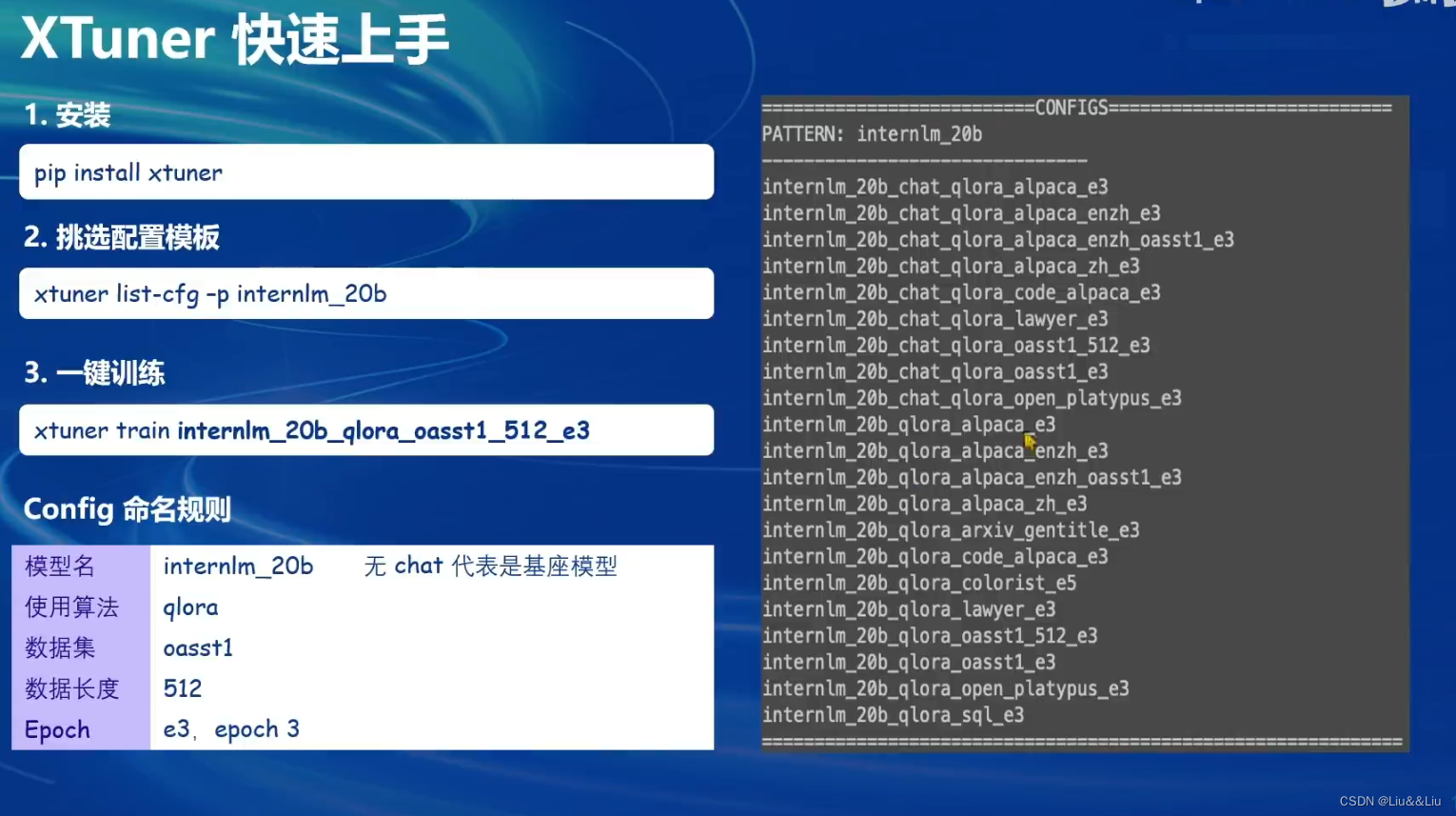
XTuner介绍


主要有两种微调范式,目的是使基座大模型成为垂直模型
什么是指令微调————就是有对话
数据要可以被系统利用
不同模型有不同的输入/输出模板
喂给模型的是拼装好的
基座不变,在基座上微调lora,新建小linear,也就是adapter。主要目的是减少开销。
 1399
1128
672
1209
1399
1128
672
1209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





























