






花指令
可执行花指令
顾名思义,可以执行的花指令,这部分垃圾代码会在程序运行的时候执行,但是执行这些指令没有任何意义,并不会改变寄存器的值,同时反汇编器也可以正常的反汇编这些指令。目的是为了增加静态分析的难度,加大逆向分析人员的工作量。
不可执行花指令
不可以执行的花指令,这类花指令会使反编译器在反编译的时候出错,反汇编器可能错误的反汇编这些指令。根据反汇编的工作原理,只有花指令同正常指令的前几个字节被反汇编器识别成一组无用字节时,才能破坏反汇编的结果。因此,插入的花指令应当是一些不完整的指令,被插入的不完整指令可以是随机选择的。
为了能够有效迷惑反汇编器,同时又确保代码的正确运行,花指令必须满足两个基本特征,即:
垃圾数据必须是某个合法指令的一部分。
程序运行时,花指令必须位于实际不可执行的代码路径。
原理:反汇编算法的设计缺陷
反汇编算法主要可以分为俩类:递归下降算法和线性扫描算法。
1)线性扫描算法
线性扫描算法p1从程序的入口点开始反汇编,然后对整个代码段进行扫描,反汇编扫描过程中所遇到的每条指令。线性扫描算法的缺点在于在冯诺依曼体系结构下,无法区分数据与代码,从而导致将代码段中嵌入的数据误解释为指令的操作码,以致最后得到错误的反汇编结果。
2)递归下降算法
递归下降采取另外一种不同的方法来定位指令。递归下降算法强调控制流的概念。控制流根据一条指令是否被另一条指令引用来决定是否对其进行反汇编,遇到非控制转移指令时顺序进行反汇编,而遇到控制转移指令时则从转移地址处开始进行反汇编。通过构造必然条件或者互补条件,使得反汇编出错。
IDA 反汇编应用的是递归下降算法
构造:
1.永恒跳转,jmp指令
2.多层跳转
3. jnz 和 jz 互补跳转
因为是近跳转,所以ida分析的时候会分析出jz或者jnz会跳转几个字节,这个时候我们就可得到垃圾数据的长度,将该长度字节的数据全部nop掉即可解混淆。
4.跳转指令构造
5. call 和 ret
主要就是这几种
例题
[HNCTF 2022 WEEK2]e@sy_flower
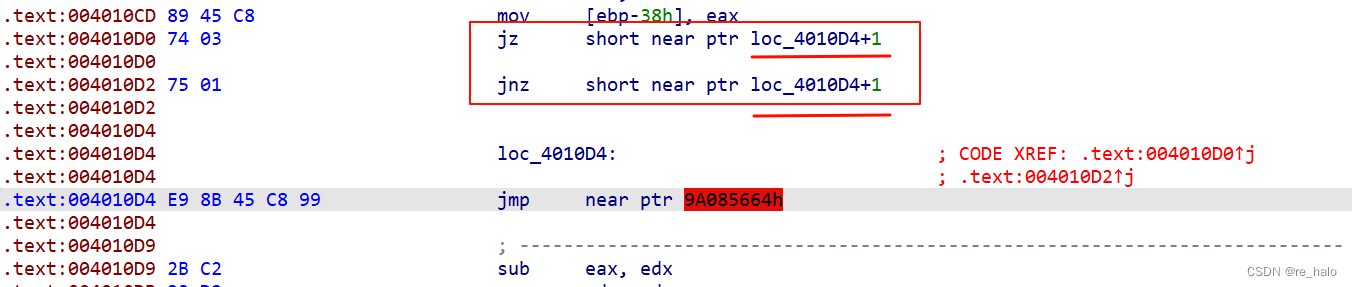
是互补跳转,并且提示了 跳转字节的大小,就把 E9 改为 90 就行了
[NSSRound#3 Team]jump_by_jump
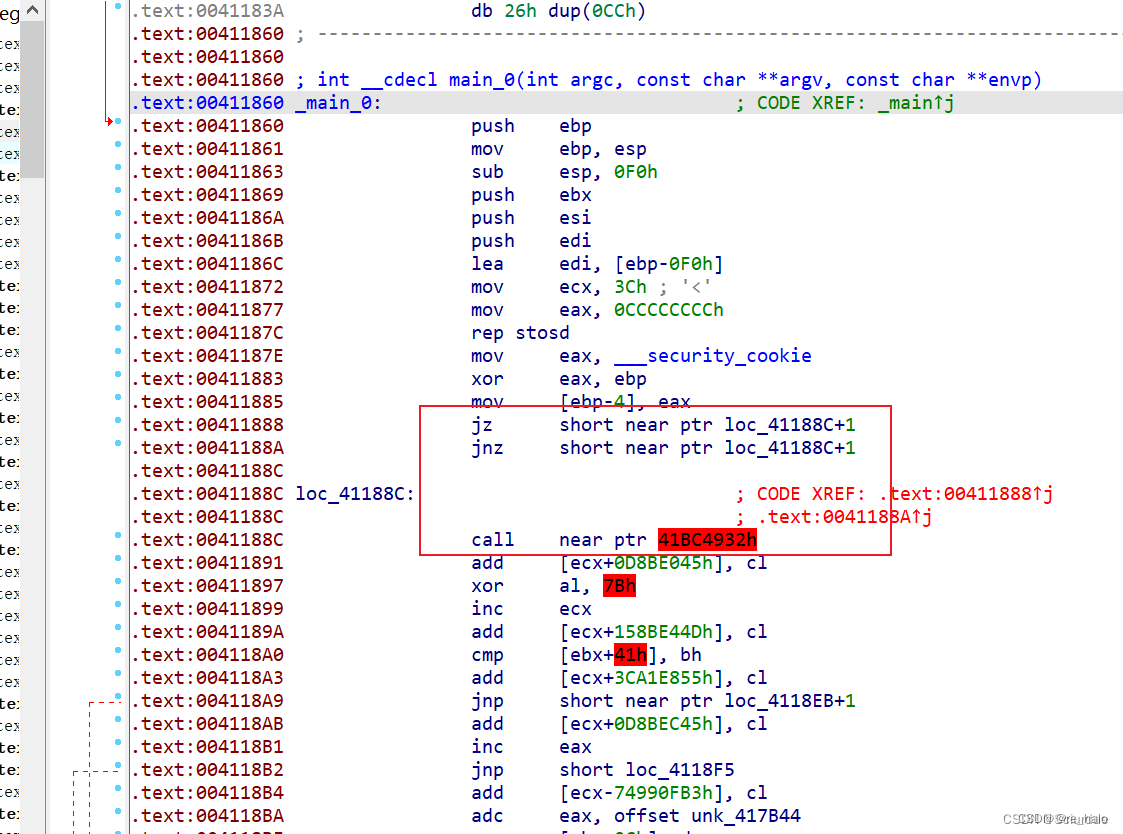
还是一道互补跳转的
题目,但是 nop 完后
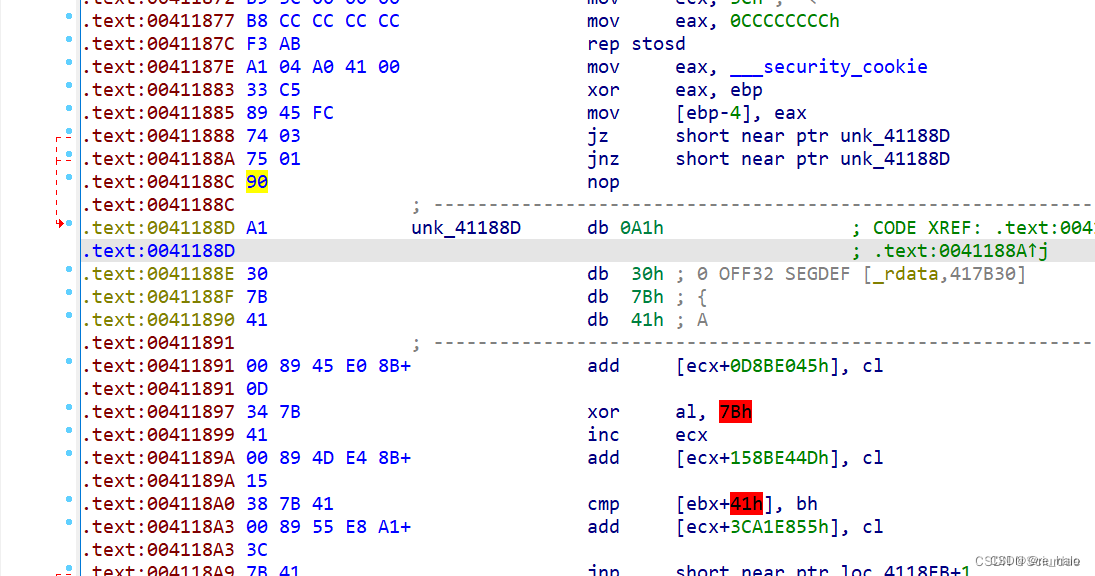
黄色部分要转换为代码,按 C 有的可能还要全部重新分析。
[NSSRound#3 Team]jump_by_jump_revenge

按上面所说的,应该要 nop 掉两个字节,但只 nop 了一个也是对的,不知道为什么
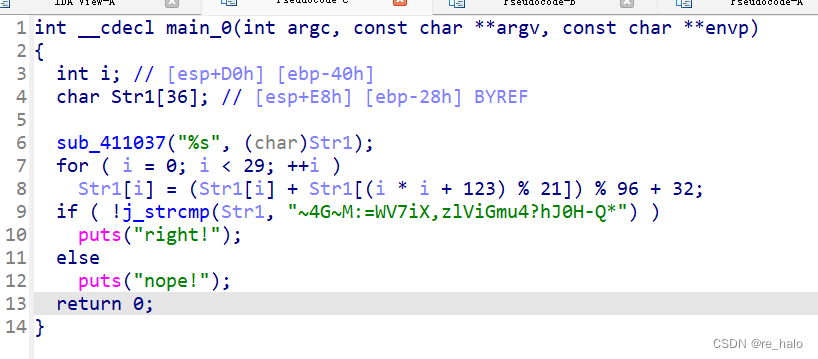
嗯,这个算法也写一下吧
(i * i + 123) % 21
范围是 0-20
xx %96 + 32
结果取模96,之后再加上32,使结果落在ASCII可打印字符范围内(32到127之间)
逆向时要逆向:
-
加密前一位时 利用了随机其他位的值,从左到右依次加密,
-
那么解密时就要从右往左,因为最后一位在进行加密时,其他位的状态是:已经完成加密
enc="~4G~M:=WV7iX,zlViGmu4?hJ0H-Q*"
flag=''
enc=list(enc)
print(enc)
for i in range(len(enc)-1,-1,-1):
tmp=ord(enc[i])-32
k=(i*i+123)%21
for j in range(5): # 爆破
s1=tmp+j*96-ord(enc[k])
if 33<=s1<=126:
flag+=chr(s1)
enc[i]=chr(s1)
break
print(flag[::-1])
print(''.join(enc))有取模运算一般都是爆破的
ciper='~4G~M:=WV7iX,zlViGmu4?hJ0H-Q*'
for i in range(len(ciper)-1,-1,-1):
tmp=ord(ciper[i])-32-ord(ciper[(i*i+123)%21])
while(tmp<33):
tmp+=96
ciper=ciper[:i]+chr(tmp)+ciper[i+1:]
print(ciper)
还有这种解法
总结:
发现大多都是 jz,jnz互补跳转,还有就是近距离跳转,在爆红位置仔细看一下就能发现的,遇到其他的以后再记一下
SMC
之前有一篇文章已经说过了,就不赘述了,就是通过 virtualprotect() 和 elf 下一个函数
进行代码修改,动态代码加密技术。
例题的话,就是 jocker 和 那个 babysmc 吧,之前的文章也写了。
还是要多复习。

















 816
816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









