






 本文详细阐述了MySQL执行流程,包括连接器的作用、查询缓存的局限性、SQL解析与优化过程,以及InnoDB如何通过日志和锁保证事务的ACID特性。此外,还介绍了MySQL的优化策略,如索引使用、查询优化技巧和读写分离等。
本文详细阐述了MySQL执行流程,包括连接器的作用、查询缓存的局限性、SQL解析与优化过程,以及InnoDB如何通过日志和锁保证事务的ACID特性。此外,还介绍了MySQL的优化策略,如索引使用、查询优化技巧和读写分离等。
MYSQL执行流程
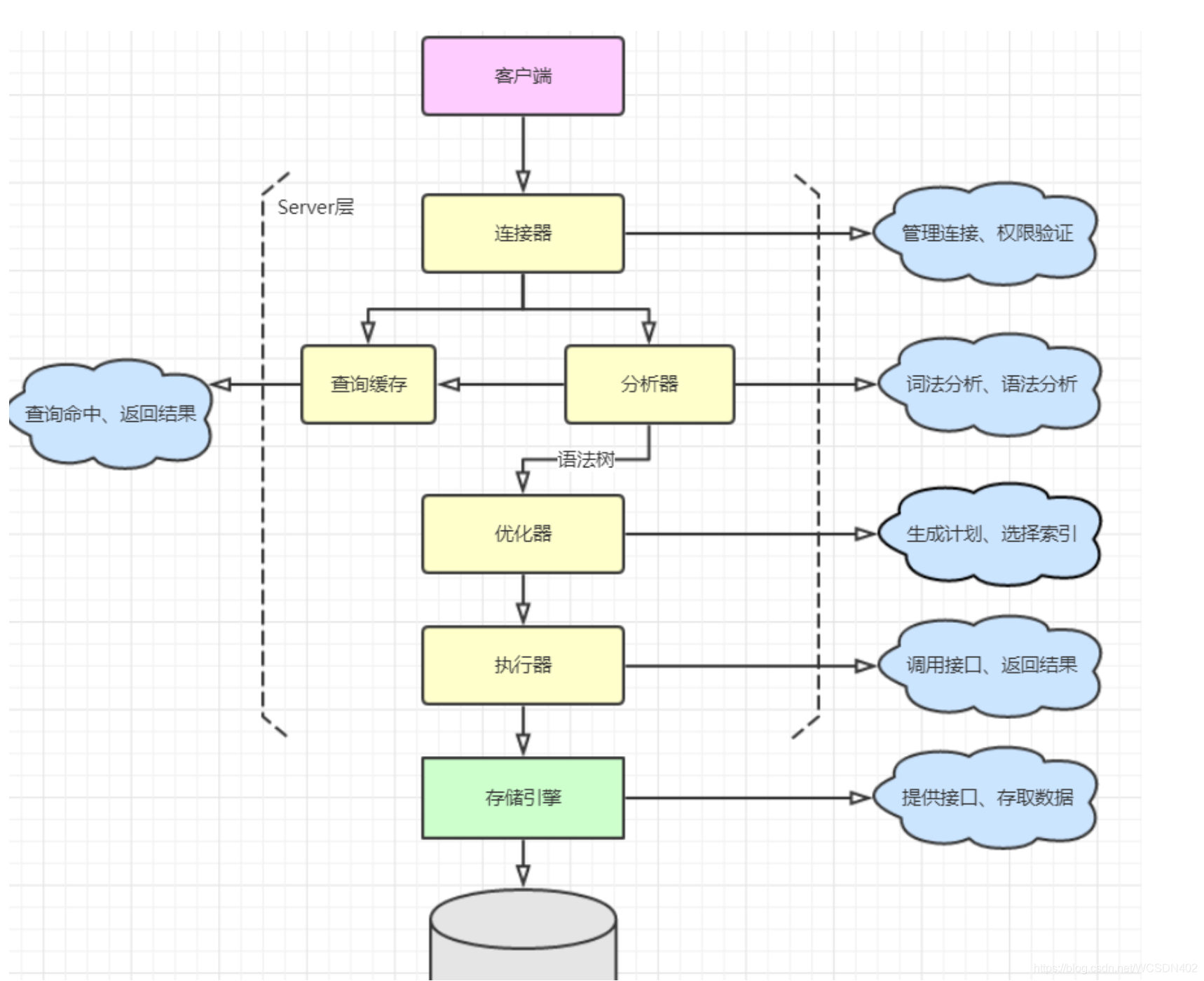
连接器(connect)
连接器负责跟客户端建立连接、获取权限、维持和管理连接。有些时候MySQL 占用内存涨得特别快, 是因为在执行过程中临时使用的内存(join buffer 表join用到、sort buffer 表排序用到、内存临时表和磁盘临时表在分组、去重等时候用到)是管理在连接对象里面的,需要定期断开才能释放,特别是执行过一个占用内存的大查询后,最好断开连接,之后再重连;所以如果连接长时间累积下来,可能导致内存占用太大,被系统强行杀掉(OOM),从现象看就是 MySQL 异常重启了
查询缓存(query_cache)
当连接建立成功后,select语句就会来到缓存查询这一块,尝试从缓存中拿到数据。以前执行过的sql语句和结果会以K-V的形式存储,sql是K,查询的结果是V。如果拿到了结果会直接返回,如果没拿到结果则会继续走后面的流程拿到数据返回。但是大多数情况下,该缓存很鸡肋,为什么这样说,假设我们缓存中一张表存在很多缓存,一旦该表执行了update语句,因此所有缓存数据都会失效,对于更新压力大的数据表命中率会很低,在mysql8.0版本已经将缓存功能移除
解析器(parser)
输入的是由多个字符串和空格组成的一条SQL 语句,MySQL 需要识别出里面的字符串分别是什么,代表什么;根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法,然后从文本中将要查询的表,查询条件都提取出来放到mysql服务器内部使用的一些数据结构上
优化器(optimizer)
会对我们的语句做一些优化,如外连接转换为内连接、表达式简化、子查询转为连接等,并生成执行计划
存储引擎层(storage engines)
人们把mysql服务器处理请求的过程简单地划分为server层和存储引擎层。
server层的功能包括连接管理、查询缓存、语法解析、查询优化这些并不涉及真实数据存取的功能,server层涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等;另外只要涉及到多表运算,也都在server层;
存储引擎层实现存取真实数据的功能,各种不同的存储引擎为server层提供统一的调用接口,其中包含了几十个不同用途的底层函数,比如"读取索引第一条记录",“读取索引下一条记录”,"插入记录"等,所以在server层完成了查询优化后,只需按照生成的执行计划调用底层存储引擎提供的接口,获取到数据后返回给客户端就好了
MySQL四大特性
1. 原子性(atomicity):
一个事务必须被视为一个不可分割的工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚。对于一个事务来说,不可能只执行其中的一部分操作,这就是事务的原子性
2. 一致性(consistency)
数据库总是从一个一致性状态转换到下一个一致性状态。在前面的例子中,一致性确保了,即使在执行第3、4条语句之间时系统崩溃,支票账户中也不会损失200美元。如果事务最终没有提交,该事务所做的任何修改都不会被保存到数据库中。
3. 隔离性(isolation)
通常来说,一个事务所做的修改在最终提交以前,对其他事务是不可见的,这就是隔离性带来的结果。在前面的例子中,当执行完第3条语句、第4条语句还未开始时,此时有另外一个账户汇总程序开始运行,其看到的支票账户的余额并没有被减去200美元。后面我们讨论隔离级别(isolation level)的时候,会发现为什么我们要说“通常来说”是不可见的
4. 持久性(durability)
一旦提交,事务所做的修改就会被永久保存到数据库中。此时即使系统崩溃,数据也不会丢失。持久性是一个有点模糊的概念,实际上持久性也分很多不同的级别。有些持久性策略能够提供非常强的安全保障,而有些则未必。而且不可能有100%的持久性保障(如果数据库本身就能做到真正的持久性,那么备份又怎么能增加持久性呢?)。
事务隔离级别
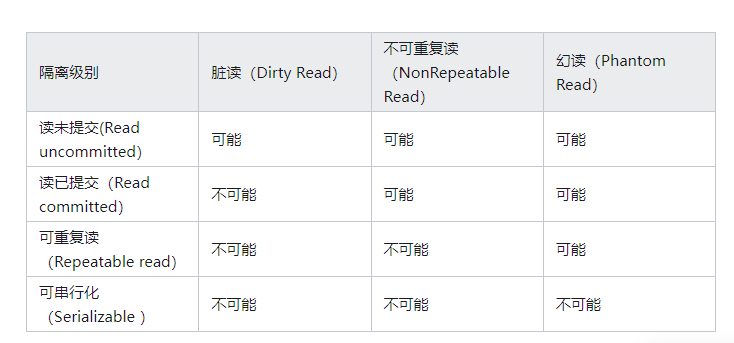
读未提交
如果一个事务正在处理某一数据,并对其进行了更新,但同时尚未完成事务,或者说事务没有提交,与此同时,允许另一个事务也能够访问该数据。例如A将变量n从0累加到10才提交事务,此时B可能读到n变量从0到10之间的所有中间值。
允许脏读。在 读未提交 隔离级别下,允许 脏读 的情况发生。
例:
脏读指的是读到了其他事务未提交的数据,未提交意味着这些数据可能会回滚,也就是可能最终不会存到数据库中,也就是不存在的数据。读到了并一定最终存在的数据,这就是脏读
读已提交
只允许读到已经提交的数据。即事务A在将n从0累加到10的过程中,B无法看到n的中间值,之中只能看到10。
在 读已提交 隔离级别下,禁止了 脏读,但是 允许不可重复读的情况发生
例:
事务A在将n从0累加到10的过程中,B无法看到n的中间值,之中只能看到10。同时,有事务C进行从10到20的累加,此时B在同一个事务内再次读时,读到的是20。
可重复读
保证在事务处理过程中,多次读取同一个数据时,其值都和事务开始时刻时是一致的。
在可重复读隔离级别下,禁止了:脏读、不可重复读
允许幻读:
在可重复读中,该sql第一次读取到数据后,就将这些数据加锁(悲观锁),其它事务无法修改这些数据,就可以实现可重复读了。但这种方法却无法锁住insert的数据,所以当事务A先前读取了数据,或者修改了全部数据,事务B还是可以insert数据提交,这时事务A就会发现莫名其妙多了一条之前没有的数据,这就是幻读,不能通过行锁来避免
可串行化
最严格的事务,要求所有事务被串行执行,不能并发执行。
如果不对事务进行并发控制,我们看看数据库并发操作是会有那些异常情形:
1)一类丢失更新:两个事物读同一数据,一个修改字段1,一个修改字段2,后提交的恢复了先提交修改的字段。
2)二类丢失更新:两个事物读同一数据,都修改同一字段,后提交的覆盖了先提交的修改。
3)脏读:读到了未提交的值,万一该事物回滚,则产生脏读。
4)不可重复读:两个查询之间,被另外一个事务修改(update)了数据的内容,产生内容的不一致。
5)幻读:两个查询之间,被另外一个事务插入或删除了(insert、delete)记录,产生结果集的不一致。
MySQL数据库的事务实现原理
InnoDB 是通过 日志和锁 来保证的事务的 ACID特性,具体如下:
(1)通过数据库锁的机制,保障事务的隔离性;
(2)通过 Redo Log(重做日志)来,保障事务的持久性;
(3)通过 Undo Log (撤销日志)来,保障事务的原子性;
Undo Log 如何保障事务的原子性呢
具体的方式为:在操作任何数据之前,首先将数据备份到一个地方(这个存储数据备份的地方称为 Undo Log),然后进行数据的修改。如果出现了错误或者用户执行了 Rollback 语句,系统可以利用 Undo Log 中的备份将数据恢复到事务开始之前的状态
Redo Log如何保障事务的持久性呢
具体的方式为:Redo Log 记录的是新数据的备份(和 Undo Log 相反)。在事务提交前,只要将 Redo Log 持久化即可,不需要将数据持久化。当系统崩溃时,虽然数据没有持久化,但是 Redo Log 已经持久化。系统可以根据 Redo Log 的内容,将所有数据恢复到崩溃之前的状态
Mysql 优化
字段
1.尽量使用 TINYINT 、 SMALLINT 、 MEDIUM_INT 作为整数类型而非 INT ,如果非负则加上 UNSIGNED
2.VARCHAR 的长度只分配真正需要的空间
3.使用枚举或整数代替字符串类型
4.尽量使用 TIMESTAMP 而非 DATETIME ,
5.单表不要有太多字段,建议在20以内
6.避免使用NULL字段,很难查询优化且占用额外索引空间
索引
1.索引并不是越多越好,要根据查询有针对性的创建,考虑在 WHERE 和 ORDER BY 命令上涉及的列建立索引,可根据 EXPLAIN 来查看是否用了索引还是全表扫描
2.应尽量避免在 WHERE 子句中对字段进行 NULL 值判断,否则将导致引擎放弃使用索引而进行全表扫描
3.值分布很稀少的字段不适合建索引,例如"性别"这种只有两三个值的字段
4.字符字段只建前缀索引
5.字符字段最好不要做主键
6.不用外键,由程序保证约束
7.尽量不用 UNIQUE ,由程序保证约束
8.使用多列索引时注意顺序和查询条件保持一致,同时删除不必要的单列索引
查询SQL
1.可通过开启慢查询日志来找出较慢的SQL
2.不做列运算:SELECT id WHERE age + 1 = 10 ,任何对列的操作都将导致表扫描,它包括数据库教程函数、计算表达式等等,查询时要尽可能将操作移至等号右边
3.sql语句尽可能简单:一条sql只能在一个cpu运算;大语句拆小语句,减少锁时间;一条大sql可以堵死整个库
4.不用 SELECT *
5.OR 改写成 IN :OR 的效率是n级别, IN 的效率是log(n)级别,in的个数建议控制在200以内
6.不用函数和触发器,在应用程序实现
7.避免 %xxx 式查询
8.少用 JOIN
9.使用同类型进行比较,比如用 '123' 和 '123' 比, 123 和 123 比
10.尽量避免在 WHERE 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描
11.对于连续数值,使用 BETWEEN 不用 IN :SELECT id FROM t WHERE num BETWEEN 1 AND 5
12.列表数据不要拿全表,要使用 LIMIT 来分页,每页数量也不要太大
读写分离
也是目前常用的优化,从库读主库写,一般不要采用双主或多主引入很多复杂性,尽量采用文中的其他方案来提高性能。同时目前很多拆分的解决方案同时也兼顾考虑了读写分离
索引什么情况下不生效
(数据库设计和索引选择中,考虑到索引的离散性是很重要的)
1.查询条件包含or,会导致索引失效
2.隐式类型转换,会导致索引失效,例如 age字段类型是int,我们where age= "1",这样就会触发隐式类型转换
3.like通配符会导致索引失效,注意: "ABC%"不会失效,会走range索引,"%ABC"索引失效
4.联合索引,查询时的条件列不是联合索引中的第一列,索引失效
5.对索引字段进行函数运算
6.对索引列运算(如,+,-,*,/),索引失效
7.索引字段上使用(!= 或者 <>,not in)时,会导致索引失效
8.索引字段上使用 is null, is not null ,可能导致索引失效
9.像 join的两个表的字符编码不同,不能命中索引,会导致笛卡尔积的循环计算
10.mysql高级使用全表扫描要比使用索引快,则不使用索引

















 111万+
111万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









