






目录
一.Mysql架构
这两个词汇得分清楚,单词很相近,认证和授权意义不一样。
authentication认证 身份认证 账号密码验证-->token
authorisation授权 -->分配权限菜单
1.连接层
在mysql服务中,负责客户端连接,进行身份认证,授权。
2.服务层
在服务层进行sql分析,优化,各种逻辑的处理等.
3.引擎层
引擎层是实际负责数据存储和提取操作. mysql提供了不同的引擎(处理方式),可以根据需要进行选择。
4.物理文件存储层
实际的文件存储, 包括存储数据的文件,还有各种日志文件。
二.Mysql引擎
引擎就是负责实现数据存储和提取的一种实现方式,不同的引擎数据存储和提取的方式不同。
mysq提供多种引擎。
1.InnoDB
是MySQL中默认的引擎。
支持事务(安全可靠),支持行级锁(锁的粒度小,并发量高),支持外键约束,支持全文索引,支持数据缓存,提高查询的效率,不存储总行数( select count(*) from table 统计总行数 逐行统计)。
2.MyISAM
myisam不支持事务,不支持外键,不支持行级锁,支持表锁(并发量低),适合写多查询少的场景,支持全文索引,存储表的行数。
三.索引
1.什么是索引
索引是一种有序的数据结构(B+树),可以帮助更快地查询数据。
如果数据库中的存储量特别大的话,逐行查询效率就很低。
索引类似于书的目录,可以帮助我们快速的定位到具体的页数.
2.为什么要有索引
没有索引的话,数据库中查询一条数据就是逐行查询,效率就很低,所以就存在了索引这个概念,使得查询效率大幅提高。
3.索引的原理
索引的目的在于提高查询效率,与我们查阅图书所用的目录是一个道理:先定位到章,然后定位到该章下的一个小节,然后找到页数。相似的例子还有:查字典,查火车车次,飞机航班等.
本质都是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
索引类似于书的目录,在一本书前面加上目录,查找内容时不必逐页翻阅就能够快速地找到所需的内容。借助索引,执行查询时不必扫描整个表就能够快速地找到所需要的数据。
4.索引优势
可以快速定位到数据,提高查询效率,减少了硬盘的IO成本。
同时所以就已经排好序了,也降低了排序的成本,减少了CPU的消耗。
5.索引劣势
索引虽然好,但是也不能滥用,创建索引也是需要空间的,当数据发生改变时(新增,删除),那么索引信息也要改变。
6.索引分类
如何在表中加索引
主键索引
把某个列设置为主键后,自动创建主键索引,
-- 创建表时添加注解索引
CREATE TABLE test(
id INT PRIMARY KEY
)
-- 修改表结构,添加主键
ALTER TABLE test ADD PRIMARY KEY test(id)
-- 删除主键
ALTER TABLE test DROP PRIMARY KEY ;唯一索引
CREATE UNIQUE INDEX 索引名 ON 表名(列名);
DROP INDEX 索引名 ON test;单值索引
一般的列多数添加的都是单值索引,用的最多的.
CREATE INDEX 索引名 ON 表名(列名);
DROP INDEX 索引名 ON 表名;组合索引(复合索引)
一个索引中包含多个列,降低索引开销(推荐)
CREATE INDEX 索引名 ON 表名(列 1,列 2...);
DROP INDEX 索引名 ON 表名;最左前缀原则
在使用组合索引时,需要满足组合索引的最左前缀原则。
例如:表中有 a,b,c 3 列,为 a,b 两列创建组合索引,那么在使用时需要满足最左侧索引原则.在使用组合索引的列作为条件时,必须要出现最左侧列为条件,否则组合索引不生效.
CREATE INDEX test_a_b_index ON test(a,b);
EXPLAIN SELECT * FROM test WHERE a='1' AND b='1' 索引生效
EXPLAIN SELECT * FROM test WHERE a='1' AND c='1' 索引生效
EXPLAIN SELECT * FROM test WHERE b='1' AND c='1' 没有使用最左列,索引失效也就是说a,b两列已经是组合索引,左侧的列是a列,所以要想使用组合索引,条件中就必须存在a列。
前缀索引
有的列中的内容比较长(新闻摘要,内容),如果给该列建立索引,对索引开销就很大,
给指定长度的区间内容建立索引。
create index 索引名 on 表名(列名(长度))全文索引
需要模糊查询时,一般索引无效,这时候就可以使用全文索引了。
解决了使用模糊查询索引失效的问题。
CREATE FULLTEXT INDEX 索引名 ON test(列) WITH PARSER ngram;
SELECT * FROM 表名 WHERE MATCH(列) AGAINST('搜索词')
EXPLAIN SELECT * FROM 表名 WHERE MATCH(列) AGAINST('搜索词')7.索引创建原则
哪些情况下的列可以创建索引?
①主键自动建立唯一索引
②作为查询条件的列
③尽量使用联合索引(几个列添加一个索引),减少单列索引
④针对于数据量较大,且查询比较频繁的表建立索引。
⑤针对于用来排序,分组的列创建索引会提高效率。
哪些情况下的列不要创建索引?
①表记录太少
②经常增删改的表,发生增删改操作时,mysql不仅要保存数据,还要保存索引文件。
③where条件里面用不到的字段
④重复出现很多的数据,例如性别.
8.索引数据结构
B+树
首先B+树是有序的,而且一个节点可以存储多个数据,非叶子节点只存储索引数据。
所以每个节点可以存储更多的索引数据。
9.聚簇索引和非聚簇索引
聚簇索引就是能通过这个索引找到完整的数据的索引。eg:主键id
mysql中innodb引擎中的主键索引就是聚簇索引。
因为数据和索引都在一个文件中存储,主键索引是一级索引,直接与数据绑定。
还有像name等其他索引是属于二级索引,如果通过name进行查询学生信息,先在name二级索引树上查找,找到了然后再通过name对应的主键去主键索引树上找到数据,那么这些二级索引属于非聚簇索引.
非聚簇索引不能通过索引找到完整的数据,一般只能找到聚簇索引,并通过回表查询再找到完整的数据。
innodb中的二级所以属于非聚簇索引。
myisam中索引和数据分别存储在不同的文件中,所以是非聚簇的。
10.回表查询
回表查询就是查询时,一次没有查到我们需要的数据,而是需要再次进行查询。
例如学生信息有id(主键),学号(唯一索引 二级索引),姓名(没有加任何索引),
如果我们通过主键查询学生所有信息,那么是直接可以找到数据的,不需要二次回表查询。
如果我们通过学号查询学生所有信息,先在学号索引树上找到学号,以及主键,然后再二次上主键索引树上查找,才能找到数据,就是发生了两次查询,称为回表查询了.
如果我们通过学号只查询学号,可以直接在学号索引树上找到数据,不会二次回表.
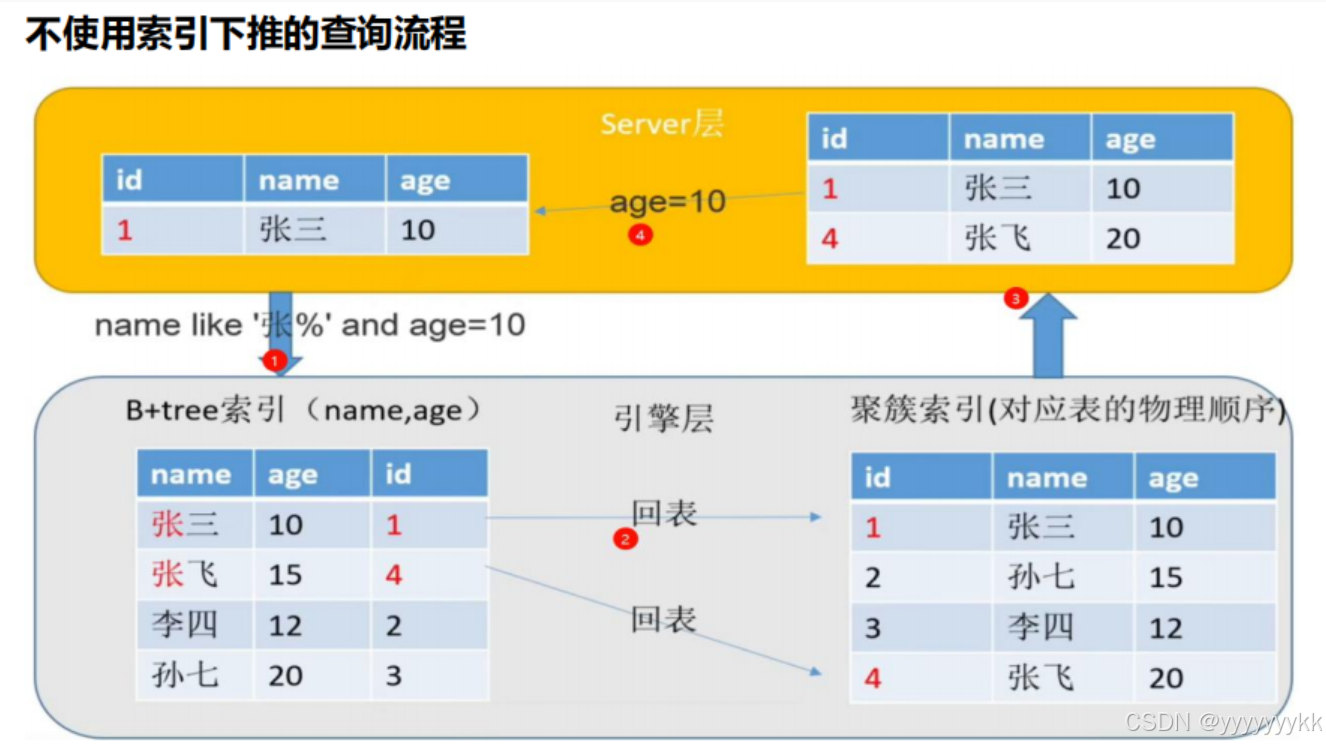
11.索引下推
索引下推(Index Condition Pushdown,简称 ICP)是Mysql中的一项优化技术,尽量在查询时,减少回表查询的次数。
也就是在查询之前,先通过条件中的索引进行初筛(先在索引树上面进行条件筛选)。
注意:索引下推只存在于查询条件中有索引的情况。

四.数据库事务
1.什么是事务?
数据库事务就是对一次数据库操作过程的管理,保证一次与数据库交互过程中执行的多条sql要么全部都成功执行,要么全部都不执行,保证原子性。
eg:银行转账问题,购物车下订单。
2.事务的特征(4个)
原子性:保证一次操作中多条sql在没有问题时,提交事务,多条sql都执行,一旦有问题,事务回滚,回滚到事务开始前的状态。
隔离性:数据库为了提高读写的并发性,提供了四种隔离级别:读 未提交,读 已提交,可重复读,串行化。
持久性:事务处理结束后,对数据的修改就是永久的,即便宕机也不会丢失。
一致性:是事务的终极目标, 以上三点都是为了保证一致性,当多个事务同时对一条数据多次操作时,最终结果与我们预期结一致.
3.隔离级别
a.读 未提交:A事务可以读到B事务中还没提交的数据,并发访问量是最高的。
产生问题:脏读,不可重复读,幻读。
脏读:读到的是垃圾数据,A查询到了B事务还没提交的数据,此时一旦B事务撤销回滚了,那么数据就是无效的。
b.读 已提交:A事务只能读到B事务已提交的数据。
解决了脏读的问题,但是还存在不可重复读,幻读的问题。
不可重复读问题:A事务在同一个事务当中,读取同一个内容两次,如果读第二次的时候数据已经修改提交,那么读到的数据就是修改后的。
eg:A事务第一次读id=1,拿到的结果是10,继续还在这次事务中,又读了一次id=1,结果读到是20,两次结果不同,这就是不可重复读问题。
c.可重复 读:A事务在同一个事务中,读取相同的数据两次,两次读到的结果是一致的,即使期间其他的事务对这个数据进行了修改提交,同一个事务读到的数据仍然是相同的。
解决了不可重复的的问题,一般的查询也解决了幻读的问题。
在查询语句的后面,如果添加了for update 这样的查询语句,拥有了与新增,修改,删除同等的权利,还是会出现幻读的问题。
幻读问题:同一个事务中,读取了两次,而两次读到数量不一致。
d.串行化:和加锁是一样的,不管是查询也好,还是新增,修改删除,一次只能允许一个事务进行操作,并发访问量最低。
两个事务都是读,不互斥
读写,写写都是互斥的。
保证数据安全可靠,但是效率也是最低的。
4.事务实现原理
a.持久性实现原理:在事务提交后,先把数据写到redo log日志文件当中,再向库中去持久化,一旦期间断电宕机,那么服务恢复之后,会将redo log文件中的数据再次写入到库中。
b.原子性实现原理:当执行insert操作时,在undo log日志文件中存储一个相反的delete操作,当事务回滚撤销时,执行相反的操作。
c.隔离性实现原理:
MVCC(多版本并发控制 Multi-Version Concurrent Control)
实现不同的事务在写-读操作,读-写操作时,可以同时进行,提高并发访问的能力,每次事务在对数据操作,都会在表中的隐式字段中记录当前操作者的id和上一个记录的回滚指针,从而形成一个版本链。
读视图(readView),从版本链上进行的一个快照。
读-已提交:称为当前读,每次读取时,都会获得一个最新的快照,即使是在同一个事务中的两次读取,都是读到的是最新的内容。
可重复读:称为快照读,在同一个事务当中,第一次查询时生成一个版本快照,在下一次读取时还是从第一次生成的这个快照中读取,这样就保证了可重复读。
d.一致性:由其他三个特征来保障。
五.锁机制
锁机制保证了进行数据操作时,保证写操作安全可靠。
按照锁的粒度分:
全局锁:对数据库备份时,锁住整个库。
FLUSH TABLES WITH READ LOCK
mysqldump --single-TRANSACTION -uroot -proot test> E:/文件名.sql
UNLOCK TABLES;表级锁:表级锁,在操作时会锁住整张表,加锁开销小,但是并发量低。
muisam引擎只支持表锁,适合读多写少的场景。
行级锁:航机送就是只锁住操作那一行的数据。
innodb引擎就支持行级锁。
间隙锁:间隙锁可以说是行级锁的一个子锁。
对与范围操作的 id>1 and id<10 的区间范围进行加锁。
按照锁的行为分:
排他锁:(写锁)新增,修改,删除操作时,默认加的的就是排他锁,锁住操作的那行数据。
查询语句如果执行时,需要添加排他锁,需要在查询语句末尾添加 for update
共享锁:(读锁)用于给查询语句添加的,如果事务1给行1添加了共享锁,那么其他事务就只能给行1添加共享锁。
其他事务不能给行1添加共享锁。
六.Sql优化
写sql语句的一些注意事项:
物理删除(真删):delete操作
逻辑删除(假删):update操作 表中会有一个列,表示删除状态 0-未删除 1-已删除
1.查询时,只查询需要的列
尽量不使用 select *
2.能使用整数的列,不要使用字符
例如mysal主键 使用int 自增
性别,可以使用0/1表示
还有各种状态等
3.varchar():变长字符串,最大上限
char():定长字符串
char一般存储长度固定的内容,varchar用于存储长度不固定的内容。
4.清空表数据
truncate table 比 delete 速度快,且使用的系统和事务日志资源少.
delete 语句每次删除一行,并在事务日志中为所删除的每行记录一项。
truncate table 通过释放存储表数据所用的**数据页**来删除数据.
5.建立索引
where order by , group by涉及的列添加索引,提高效率,避免全表扫描,同时注意创建索引的规则。
6.避免索引失效
模糊查询,在条件上使用函数,in,not in,or 这些语句导致索引失效
7.order by 写法,先条件筛选,在分组。切勿先分组,再条件筛选。
8.减少表关联查询的数量,阿里建议最多三张表,索引也不宜过多。
9.避免深度分页的问题
分页是为了减少每次查询过多的数据。
反例
select id,name from account limit 100000,10;
正例
select id,name FROM account where id > 100000 order by id limit 10; 先条件过滤,然后再取值10.使用explain关键字查看sql执行计划
使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的 SQL 语句的。分析你的查询语句或是表结构的性能瓶颈。查看如何执行这条sql的,使用到了什么索引,引擎.....等。
explain select * from test where a = 10
possible_keys : 查询中可以使用的索引
key: 本次查询实际使用到的索引 (查看索引是否有效)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









