






方法一:暴力枚举 -- 时间复杂度O(n*2^n) -- 指数级别 最好用于少量数据
def L(nums, i):
if i == len(nums) - 1: # 最后一个number 递归终止条件
return 1
max_len = 1 # initial
for j in range(i+1, len(nums)):
if nums[j] > nums[i]:
max_len = max(max_len, L(nums, j) + 1)
return max_len
def length_of_LIS(nums):
return max(L(nums, i) for i in range(len(nums)))
nums = [1,5,2,4,3]
print(length_of_LIS(nums)) # 输出3
解释为什么是2^n:每个元素有两种可能,要么在子序列中,要么不在子序列中
(或者从子集问题理解)
数组 [1, 2, 3] 所有的子集有 8 个,分别是:
------->>>>
空集 []
[1]
[2]
[3]
[1, 2]
[1, 3]
[2, 3]
[1, 2, 3]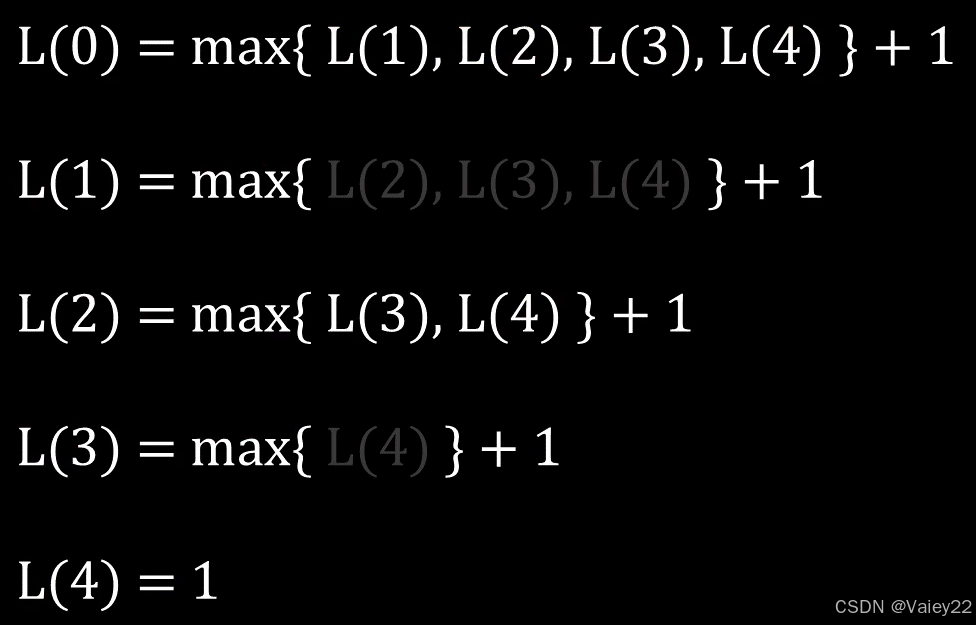 -------> L(index)
-------> L(index)
方法二:记忆化搜索 -- 时间复杂度O(n^2)
def L(nums, i):
if i in memo:
return memo[i]
if i == len(nums) - 1: # 数组中最后1位数字,后面没有数字了;规定从其开始的最长序列是1
return 1
max_len = 1 # initial
for j in range(i+1, len(nums)):
if nums[j] > nums[i]:
max_len = max(max_len, L(nums, j) + 1)
memo[i] = max_len # 表示从当前i开始的最长上升子序列长度
# print(memo)
return max_len
def length_of_LIS(nums):
return max(L(nums, i) for i in range(len(nums))) # max取 从当前i开始的最长上升子序列长度
memo = {} # 字典存储已经计算过的值,避免重复计算 “记忆化搜索”
nums = [1,5,2,4,3]
print(length_of_LIS(nums)) # 输出3
'''
每个 i 只会被计算一次,之后就直接从 memo 取值,不再重复计算。
由于 L(nums, i) 遍历 j = i+1 到 n-1,它最多会被计算 O(n) 次,每次计算的复杂度是 O(n)
时间复杂度降为 O(n^2)
'''方法三:动态规划 -- 时间复杂度:O(n^2)
def length_of_LIS(nums):
n = len(nums)
L = [1] * n # initial 从当前i开始都是1(本身)
for i in reversed(range(n)):
for j in range(i + 1, n):
if nums[j] > nums[i]:
L[i] = max(L[i], L[j] + 1) # 更新记得+1 算上(第i位本身)
return max(L)
nums = [1,5,2,4,3]
print(length_of_LIS(nums)) # 输出3
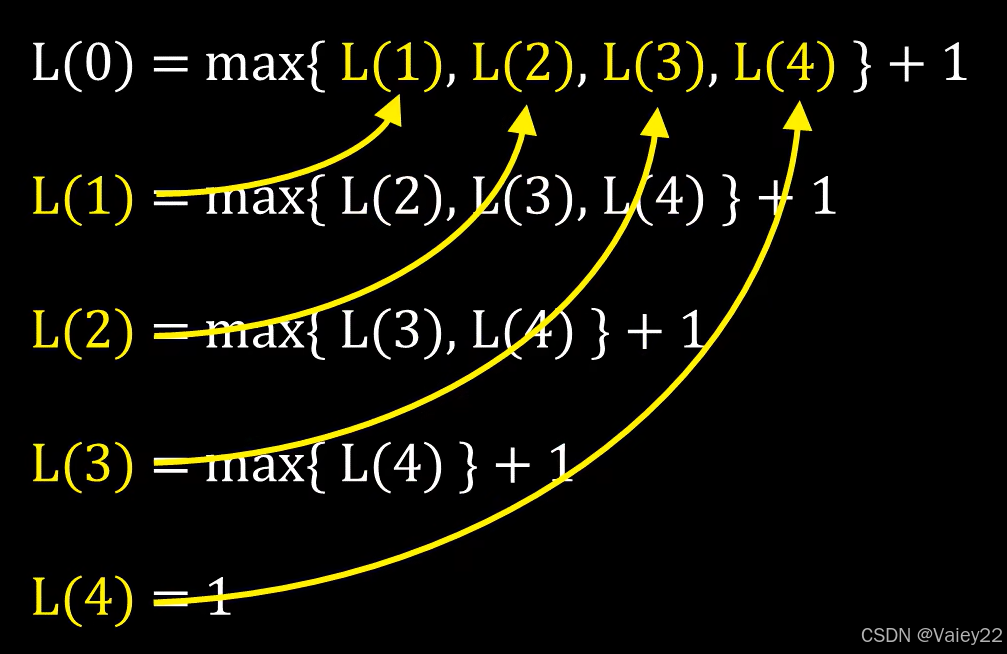 利用反向思路,迭代求解
利用反向思路,迭代求解
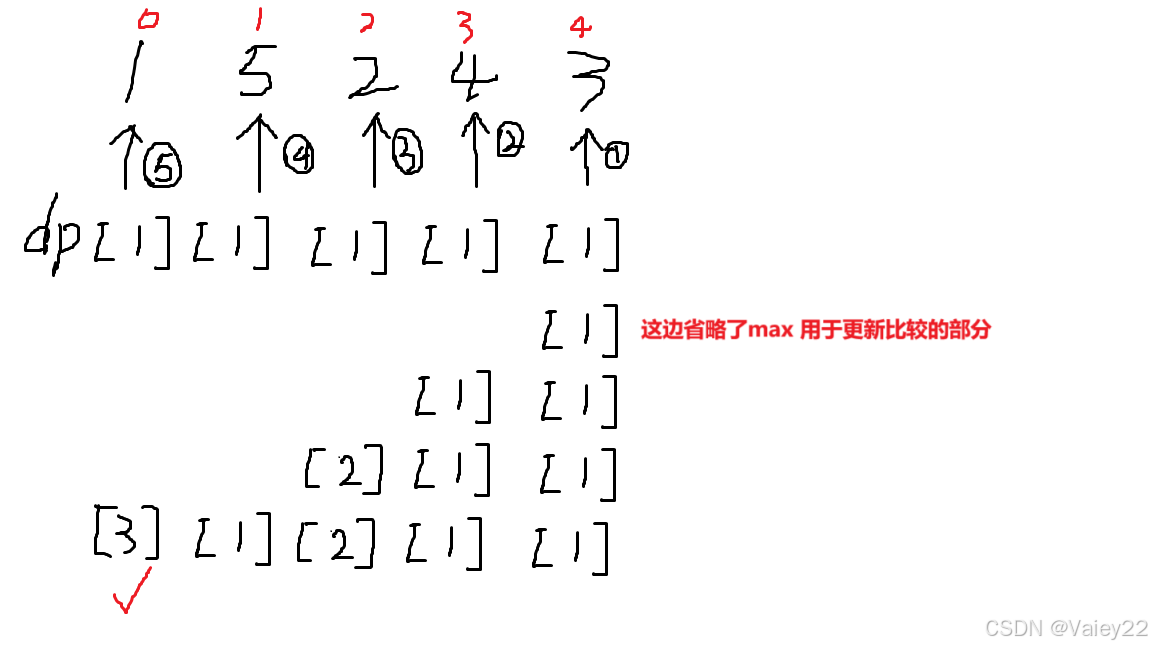
方法四:动态规划 + 二分查找 -- 时间复杂度:O(n*logn)
# 最矮台阶思想,尽可能保证后面高台阶的增长空间更大(尽可能把台阶堆高)
import bisect
def lengthOfLIS(nums):
dp = [] # dp 数组用于存储上升子序列的最小末尾元素
for num in nums:
# 使用二分查找找到 num 应该插入的位置
idx = bisect.bisect_left(dp, num) # 找到第一个大于等于 num 的位置
print(idx)
if idx < len(dp): # 直接理解为把idx的range限定在[ 0~len(dp)-1 ],;也可以具体分析情况
# 如果找到的索引小于 dp 的长度,更新该位置
dp[idx] = num
else: # # 内部没有 直接加到末尾;情况1:dp为空;情况2:num比dp中所有元素都大
dp.append(num)
# print(dp)
return len(dp) # 最终 dp 数组的长度就是 LIS 的长度
nums = [10, 9, 2, 5, 3, 7, 101, 18]
print(lengthOfLIS(nums)) # 输出 4
'''
----> 直觉理解:这和贪心策略类似
想象 LIS 是一条上升的楼梯,我们总是想让每一层台阶尽可能低,以便未来能接更长的楼梯:
看到比当前台阶更矮的,就用它替换(因为它会给未来更大的增长空间)。
看到更高的,就放到后面(让楼梯增长)。
这个策略类似贪心,但它和动态规划结合,让我们保证找到最优解。
'''补充一下bisect库中相关函数的用法:
- bisect_left:返回插入位置,x 插入到等于或大于 x 的第一个元素之前。
import bisect
a = [1, 3, 4, 4, 7, 10]
position = bisect.bisect_left(a, 4)
print(position) # 输出 2- bisect_right:返回插入位置,x 插入到等于或大于 x 的第一个元素之后。
position = bisect.bisect_right(a, 4)
print(position) # 输出 4- insort_left:将 x 插入到有序数组中,保持排序,插入到第一个等于 x 的位置,剩余部分后移。
import bisect
a = [1, 3, 4, 4, 7, 10]
bisect.insort_left(a, 4)
print(a) # 输出 [1, 3, 4, 4, 4, 7, 10]- insort_right:将 x 插入到有序数组中,保持排序,插入到最后一个等于 x 的位置,剩余部分前移。
bisect.insort_right(a, 4)
print(a) # 输出 [1, 3, 4, 4, 4, 7, 10]
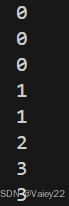
ps.(右侧补充idx在每一次迭代中寻找到的位置)
补充:[2] --> [2, 5] 而不是[2] --> [5]:
1、如果数组中没有比 num 小的元素(即 num 比数组中的所有元素都大),bisect_left 会返回 数组的末尾位置。也就是,num 会被插入到数组的最后面。
2、如果数组中有适当的位置(比如 num 大于某个元素,但小于下一个元素),bisect_left 会返回那个合适的位置。
这里的 ”二分查找“ 体现在寻找dp[]上升子序列中 >= num的最小值
ps. 插图来源:10分钟彻底搞懂“动态规划”算法_哔哩哔哩_bilibili

















 543
543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









